In this issue of EuropeanaTech Insight, the EuropeanaTech publication, we present three articles related to multilingual access of digital cultural heritage material.
Letter from the editors
Antoine Isaac, Gregory Markus
In October 2019, policymakers, cultural heritage institutions, members of the ‘Digital Cultural Heritage and Europeana’ expert group and experts in multilingualism from European Union member states participated in an event titled ‘Multilingualism in Digital Cultural Heritage - needs, expectations and ways forward’. This meeting was hosted in Espoo, Finland, by the Finnish Ministry of Education and Culture under the auspices of the Presidency of the Council of the European Union. Over two days, participants discussed how the CH sector can use advances in digital technology to make heritage material more accessible across the EU. For Europeana, which gathers collections from all 27 EU countries and in 38 languages, finding solutions to run a better, more multilingual service is paramount, and the meeting was a milestone in the definition of Europeana's multilingual strategy. But multilingualism is relevant for the entire cultural heritage sector, not just Europeana. The variety of views expressed during the meeting represented these different perspectives, as well as the voice of experts in technology that can be used to fill the existing gaps, now or in the longer term.
The presentations, images and video for the meeting are available online. A summary of the points discussed in the various presentations, panels and group working sessions can also be found here and a full report is available here. Today, we are glad to present a EuropeanaTech Insight issue that focuses on three contributions, which represents the diversity of topics discussed. First, Juliane Stiller, information specialist and co-founder of You, We & Digital, gives a general introduction to the problem space and the possible solutions for multilingualism in digital Cultural Heritage. Tom Vanallemeersch, language technology expert at CrossLang, then writes about the technical challenges and solutions of automated translation. Finally, Antoine Isaac, Dasha Moskalenko and Hugo Manguinhas from Europeana Foundation present three case studies on how multilingual issues can be solved at Europeana, using appropriate design choices combined with knowledge graph and translation technologies.
Multilingual Developments in Digital Cultural Heritage - Problem Space and Solutions
Juliane Stiller; You, We & Digital
When looking for digital cultural heritage in Europeana, you want to find all relevant books, paintings, photos, or other cultural heritage objects that match your search. You might not care much about the language in which the objects you desire are described, as long as the object satisfies your needs. Providing you with this kind of experience, where you always get relevant results to your inquiry independent of the language you speak or the language the objects are described in, is not trivial. This is particularly true for the cultural heritage domain because multilingualism is still one of the major challenges for digital cultural heritage. Not only do we need to deal with evolving languages over time but also with retrieving information stored in cultural heritage artefacts across multiple languages.
Bridging these language gaps is essential for searching digital cultural heritage and presenting it in a comprehensible way. One of the goals during the “Multilingualism in Digital Cultural Heritage” meeting that took place under the Finish presidency in November 2019 in Espoo, Finland, was to understand the opportunities and benefits of multilingualism for digital cultural heritage. The benefits of multilingualism in cultural heritage are obvious, including increased usage and exposure of cultural heritage objects as well as fostering and understanding different cultures. Nonetheless, implementing this multilingual access to digital cultural heritage is still challenging.
Advancing multilingualism is not only a matter of providing translation but requires a deep understanding of multilingual aspects and how they impact different components of a digital library or an information system that offers access to cultural heritage. This includes the user interface, search, browse and engagement. Multilingualism penetrates each layer of an information system for cultural heritage. On one side is the cultural heritage object that carries language information in the form of text or audio. On the other side are the users who want to access cultural heritage in their preferred language. Providing a user-friendly interface in the preferred language of the user is one challenging problem where one needs to decide what is the most reliable indicator for automatically setting the preferred language, for example the IP-address, the browser language or the system language.
The multilingual user experience is determined by the different functionalities that the systems provide, such as searching, browsing and engaging with the cultural heritage content. Retrieval of and access to digital cultural heritage objects is a genuine challenge that is aggravated by the nature of digital cultural heritage: not only can the cultural heritage object have multiple languages, but so can the metadata, such as titles and descriptions which are mostly in the language of the owning institution. The language gaps that need to be bridged lay between the user and the object, and the object and its describing metadata. If you want to dive deeper into this matter, refer to the White Paper on Best Practices for Multilingual Access, which aggregates resources and strategies for realizing multilingual access to cultural heritage content in digital libraries.
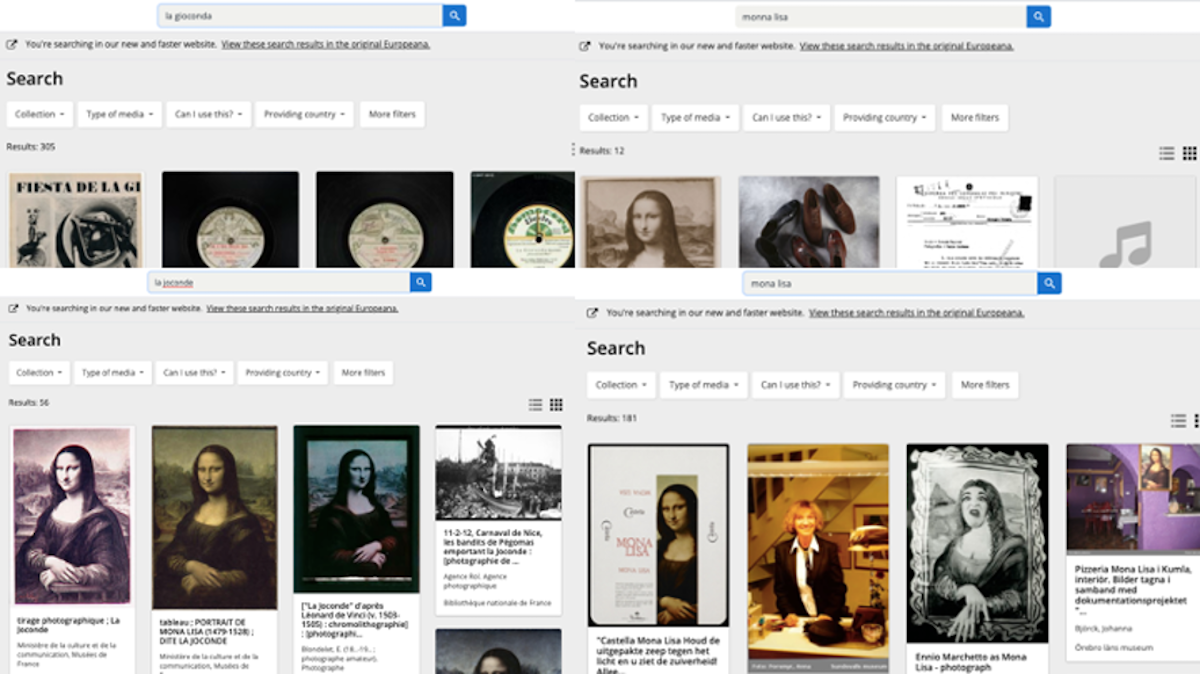
To retrieve cultural heritage information in Europeana, one can search items with the provided search box. Search poses the challenge that the query language needs to be aligned with the content in the system. Overcoming this potential mismatch between the language of a query and the language of the content is a technical problem that is tackled by research in the area of multilingual information access (MLIA). To illustrate the complexity of the problem, think about the different language versions of the famous da Vinci painting Mona Lisa that is named differently in different languages. Typing any of these different language versions into the search box in Europeana yields different result sets. Typing “Mona Lisa”, as the painting is known in German and English, yields almost 200 results. In French, the painting is known as “La Joconde” and in Italian it is either “Monna Lisa” or “La Gioconda”; all of these queries retrieve different results sets. Ideally, each query retrieves the same set of results. But this is a hard task to do and the approach for bridging the language gap is either to translate the content or translate the query.
Although automatic translation recently became more and more powerful, it is in need of high quality training data as well as context to produce satisfactory results. The Europeana use case operates under difficult conditions as content is described in over 50 languages. Being able to translate between each language pair is almost impossible due to the sheer amount of language pairs. The problem is further exacerbated by missing training data for small languages, metadata heterogeneity and sparsity, as well as historical language information which is inherent for digital cultural heritage. The good news is that translation does not need to be perfect if used for retrieval only. For example, search results can still be relevant across languages if translations used for retrieval lack fluency. But if translations are shown to users to help them make sense of the search results they see then good translations are needed as to not negatively impact the user experience.
Looking at queries that users send to the Europeana search engine, we find many queries in different languages. A query such as “alphonse mucha” suggests that the user is interested in the painter and his life and works but it does not give away the language the user expects to receive results in. A user querying театър (English: theatre) might be interested in seeing Russian results but the intent of the query is not very clear as it is short, provides no context and the term is very broad. It is also not unusual to find queries with terms in several languages such as “berlin berliner mauer or wall”.
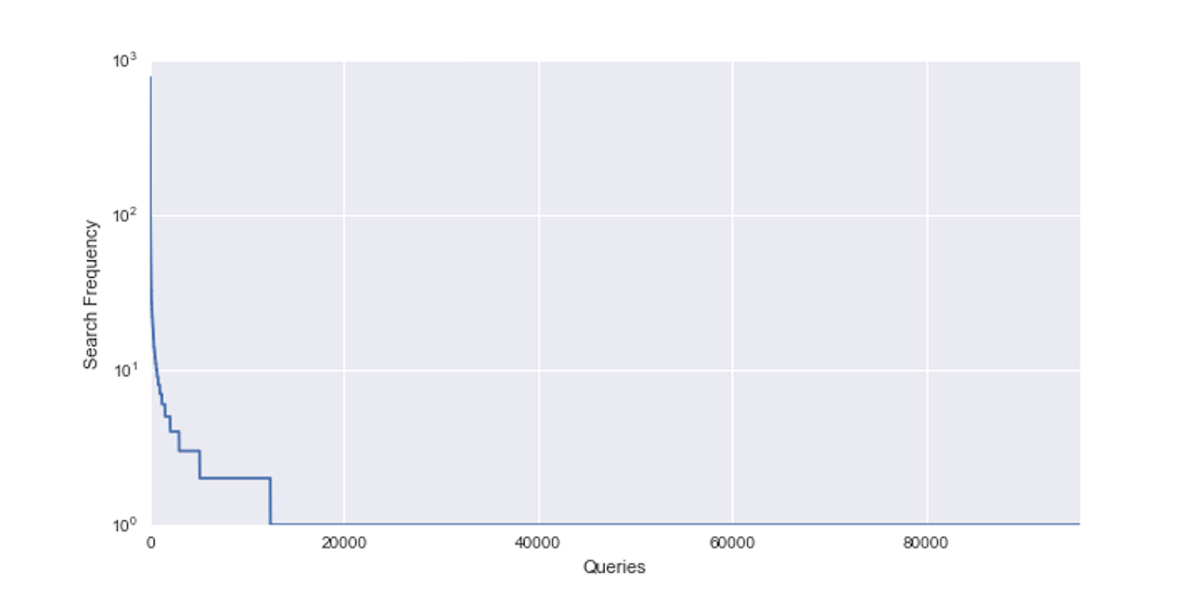
In general, Europeana queries are characterized by a huge long tail which means that most of the queries only appear once and some queries appear very often. For example, check out some of the most searched queries in 2016. Furthermore, queries can be ambiguous in language as terms such as “culture”, “administration”, or “madonna”, occur in more than one language. Semantically ambiguous queries such as “barber” (composer or hairdresser) are another category of challenging queries that need to be addressed. Matters are made worse when thinking about terms such as “Inde” which means India in French and poison in Lithuanian. Mixing these meanings can result in very poor user experiences and should be avoided. Europeana addresses some of these challenges by using entity pages and optimizes for the large set of queries that ask for entities such as “paris” or “mozart”. One example is the entity page of Leonardo da Vinci that links all works and content related to the painter.
For effectively bridging the language gap, one can further use controlled vocabularies - an approach Europeana has been using for a long time. To see the currently supported vocabularies that are used to enrich metadata refer to this document that lists Europeana dereferenceable vocabularies. This so-called enrichment process adds language versions of a term found in the vocabularies to the metadata of the Europeana object. Next to entities, such as persons and location, Europeana enriches metadata with vocabularies for concepts to offer users keywords in their preferred languages.

To summarize, the challenges of enabling multilingualism in digital cultural heritage are immense and very diverse. There are solutions that work particularly well for this domain but all solutions become less suitable once they have to be scaled to a large number of language pairs as found in Europeana.
The art of automated translation – a tasting
Tom Vanallemeersch, CrossLang
The digital cultural heritage sector touches upon scenarios where multilingualism plays a crucial role, in order to cater for the information needs of citizens and organisations throughout the European Union. One such scenario consists of searching through large digital inventories of metadata describing cultural objects. Imagine metadata providing a description of a Greek painting depicting a dish. A French food historian looking for paintings on the Europeana website may likely provide search terms like peinture (“painting”), plat (“dish”) and poisson (“fish”) and retrieve a list of paintings with a French description and possibly a French title. However, without the necessary multilingual support, the below Greek still-life with fish painted by twentieth-century artist Nikolaos Magiasis may remain out of reach. Another search scenario consists of diving into the very contents of artworks themselves, for instance historical documents. Uncountable are those who have never reached the desks of translators, leading valuable knowledge to be shielded from researchers.

The key to unlocking vast quantities of textual data consists of automating the translation process using a machine translation (MT) system, even though the output of the latter may not be ideal in all cases. In this era of constantly increasing digitisation, it is essential to be transparent about the possibilities of MT towards users and to raise awareness about MT among organisations. This was one of the conclusions of the Europeana meeting Multilingualism in digital cultural heritage - Needs, expectations and ways forward, which took place on 24 and 25 October 2019 in Espoo, Finland and included a presentation by CrossLang on the challenges for MT in the domain of cultural heritage.
The field of MT has been around since the very advent of the first computers, but systems which have the capacity to approach human translator performance have only started to see the light in recent years, thanks to the sophisticated math of neural networks. These complex computing systems, inspired by the human brain, have led to impressive progress in many applications of Artificial Intelligence (such as deep fakes and speech recognition). However, a huge caveat lies hidden in the abovementioned word “capacity”. Powerful machines require loads of energy to run. Similarly, an MT system needs to be fed with many translation examples, i.e. texts paired with their translation, in order to be able to “learn” how to translate new texts from one language into another. Moreover, these examples, which compose the training data of the system, should not only consist of “generic” sentences, but also of sentences from the specific domain for which the MT system is built.
The digital cultural heritage sector no doubt presents one of the most complex scenarios for MT. Metadata related to objects of art, as well as art-related books and other types of documents, have a very heterogeneous content and are less repetitive than texts in the “classical” domains in which MT operates. An example of such a domain consists of the administrative and legal texts that form the backbone of the European Commission’s eTranslation system. Moreover, cultural heritage texts are typically available in only one language. Therefore, translation examples are scarce. An aggravating factor for MT is that metadata tends to consist of small pieces of text (imagine the book title Bass, pike, perch & others as a metadata record), while MT systems have a strong appetite for longer sentences in their training data: in the sentences I prefer to pan-fry sea bass in order to improve the taste, The pike found extensive use in these armies, and The bird was chained to the perch in the garden, the words surrounding bass, pike and perch help to capture their meaning.

To further complicate things, digital cultural information may not only come to us as heterogeneous textual content (possibly in older language variants), but also in various data formats that have to undergo careful processing before MT can be applied at all. This is for instance the case for scanned books, photographs with text, and recorded speeches. Given these challenges, you may get the impression that, at this point in time, multilingual cultural information for all to enjoy is still far away. While the low-hanging fruit is indeed not abundant, some recent strategies in neural MT can exploit the data we have in astute ways. Let us have a look at some of the strategies that focus on the textual content. These strategies are currently of such importance that the eTranslation developers have asked the Commission’s Multilingualism team (DG CNECT) and CrossLang to organise workshops on them, moderated by top-level researchers from academia and industry (Facebook AI Research).
A first strategy we will highlight consists of domain adaptation. We provide an MT system with a large number of generic sentences and their translation (such translations are available for many languages through assiduous collection efforts in the last decades), and, once the system becomes good at translating generic text, we specialise it by feeding it translations in a specific domain. If we have only a few domain-specific translation examples to “tweak” the system, we can cook up many more examples using a simple technique called backtranslation. Imagine we want to translate from English into German. If we have art-related German books or websites, we translate them using a generic German to English system and add the resulting English-German translation examples to the MT training data. This way, our system learns to translate from “moderate” or “bad” English (i.e. an automatic translation) to good German (written by a human being), in addition to learning from the original “good” translation examples. While it is counterintuitive, even imperfect examples can be useful for learning!

In case of languages ranking low in terms of number of speakers, such as Icelandic, the scarcity of translations, especially domain-specific ones, is even more pressing. In this scenario, we could go for a multilingual MT strategy. It consists of adding translation examples involving more than two languages to the proverbial blender, for instance, translations from English into German, Norwegian, Swedish, and Icelandic. By adding language codes (like IS and NO) to translation examples, training a system from them, and adding the code IS when translating new sentences (the system needs to know into which language we want to translate), we will obtain a better translation quality in Icelandic than in case we only trained on examples in English-Icelandic ! When learning to translate into Icelandic, the system actually learns from the other languages, which also belong to the Germanic family (at this point, we should remark that neural MT systems typically translate pieces of words rather than complete words, and some of these word pieces are shared among languages).
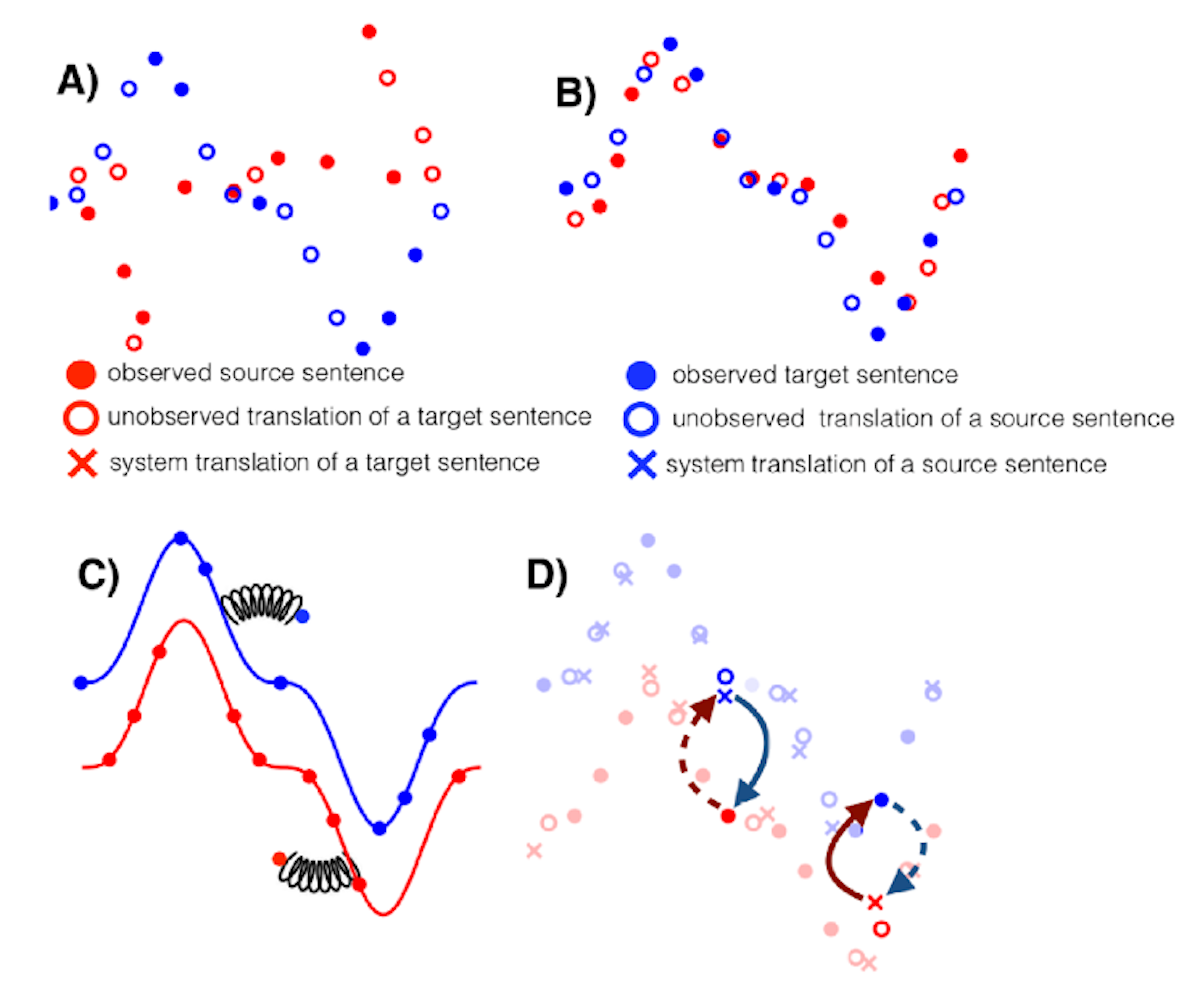
More experimental strategies are unsupervised and document-level translation. They are far from an acquired taste. In case of unsupervised MT, the blender contains texts which are not each other’s translation (for instance, English and French texts in the same domain), and yet what comes out looks like a rudimentary translation system. Without going into the minor details, the idea is to identify similar words and sentences in both languages, as shown in the below figure (step B) and learning to translate in two directions (step D). We could even apply this strategy to language variants. For instance, a system may learn to translate from old English into modern English using texts from both variants. In case of document-level MT, we look at the whole document when translating a sentence, in order to capture its full context. In case of metadata records, the document would be the set of all records related to an object of art (for instance, an object with the words Bass, pike, perch & others in one record may have a subject record that includes Bass fishing).
In conclusion, many brand-new recipes are available from the rapidly evolving field of neural MT. They allow to tackle the scarcity of domain-specific translations available for the languages under scrutiny, especially for languages which rank lower in terms of number of speakers. These recipes have already proven useful in research experiments and in “classical” MT scenarios involving repetitive texts. Trying them out on cultural-heritage texts will lead to interesting dishes and, hopefully, delightful tastings for European citizens and organisations.
Three case studies on tackling Europeana’s multilingual challenges
Antoine Isaac, Dasha Moskalenko, Hugo Manguinhas; Europeana Foundation
For several years, the Europeana.eu portal has offered the option to translate elements of its user interface into the languages of the European Union. Part of the content, for instance, some virtual exhibitions, have also been manually translated. Finally, readers familiar with metadata issues are aware of how Europeana and its partners perform manual and automatic metadata enrichment to relate objects to multilingual (linked data) vocabularies, harnessing the versatility of the Europeana Data Model and paving the way for more multilingual search and display based on that enriched metadata.
Recently, Europeana has articulated a general approach to tackling multilingual issues, across the various services it offers. At the Finnish Presidency event on Multilingualism in Digital Cultural Heritage, Europeana presented ideas that informed the new DSI-4 multilingual strategy. We also presented three case studies on key aspects of the strategy: user experience and design, using a knowledge graph to enhance multilingualism of the metadata, and exploiting automatic translation services like EU’s eTranslation for search within full-text content.
UX Design and user testing
The first case study was about user experience (UX) and testing. Results from a user survey indicate that around half of Europeana.eu’s visitors already activate the existing language-related features in the user interface (language selector, object language filter in facets). A vast majority is ready to use other languages than their own (four languages on average) during search, in order to find what they are looking for. The same proportion is eager to consume search results in even more languages than the ones they use for querying the system.
Future UX designs need to serve these users willing to cross language barriers. In this light, we have presented design options for the search page, which reflect the detection of the language of queries, the firing of translated queries against Europeana’s database, and the intelligible display of results that could be in the language of the original query or result from translation.
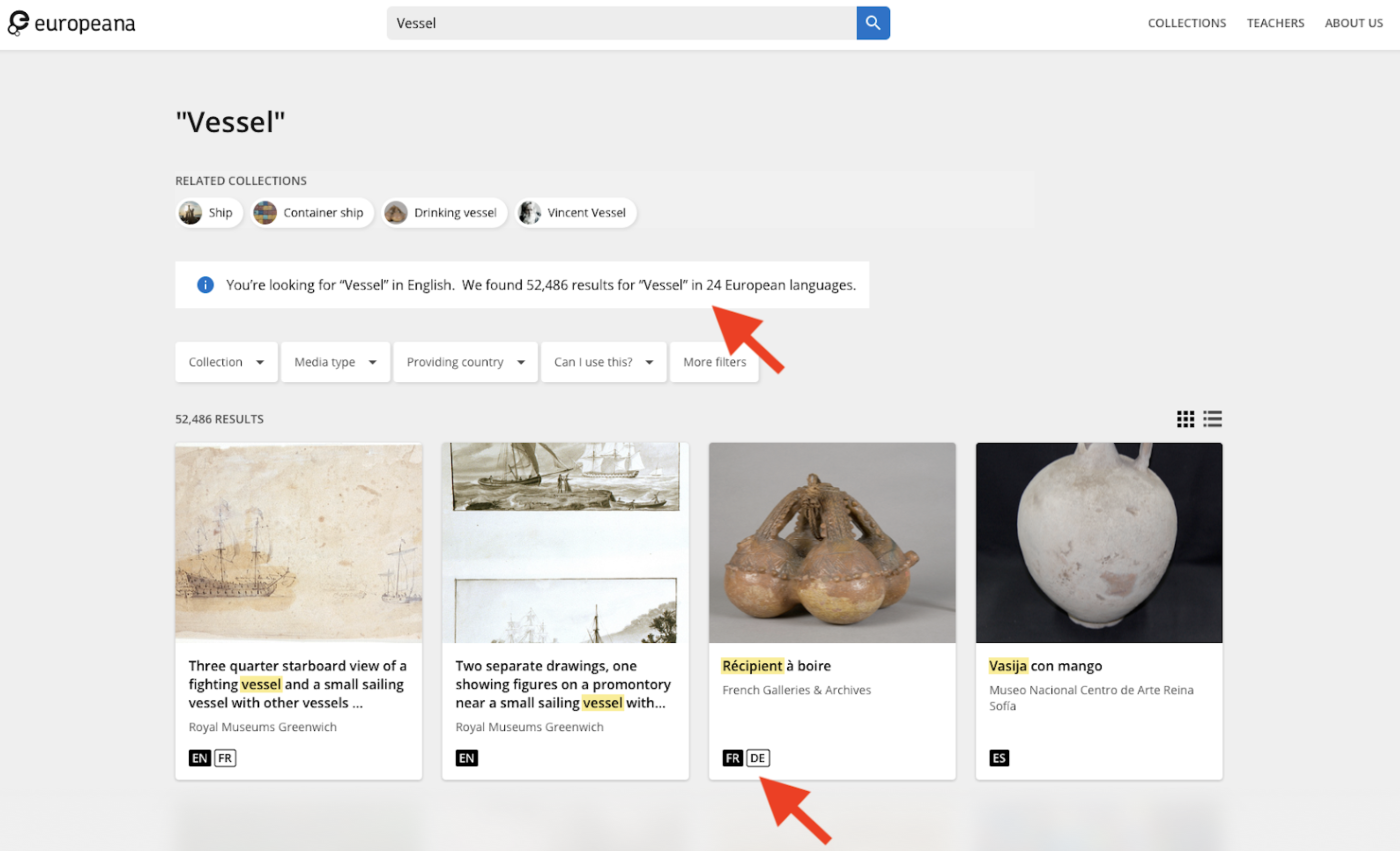
We have also begun to investigate ways to enhance multilinguality of item pages, proposing new features that would allow users to shift between the various languages that Europeana’s database may provide for a given item’s metadata and to activate automatic translation when the metadata is not available in the user’s language of choice.
Translation of object metadata using the Knowledge Graph
The second case study looked under the hood of the metadata infrastructure that Europeana has already been working on to enable such multilingual end-user scenarios. The first principle here is to back the object metadata that Europeana aggregates with its partners (e.g., on the type, subject or creators of objects) with a multilingual knowledge graph. Since 2014, Europeana has encouraged its data providers to contribute links to their own vocabularies and publish them as Linked Open Data, or directly use available reference vocabularies to describe their content. This is notably the case in Europeana’s licensing framework, which enforces the selection of rights statements for objects among the multilingual set of statements provided by Creative Commons and RightsStatements.org.
This is a long-term effort though, which requires everyone in Europeana's ecosystem to improve the way they manage and enrich their data – a key aspect of a never-ending digital transformation. To complement it, Europeana has begun to assemble a specific semantic vocabulary of core places, concepts and subjects, the Europeana Entity Collection. This “in-house” knowledge graph is used to support enhanced searching and browsing, by providing data to create multilingual "entity pages'' (for example for Pablo Picasso) and by enriching existing object metadata. Built on top of resources from DBpedia, Wikidata, Geonames, the Entity Collection also links to elements from other controlled vocabularies available as linked data, including Getty’s Art and Architecture Thesaurus (AAT), OCLC’s Virtual International Authority File (VIAF), the thesaurus from the Musical Instrument Museums Online (MIMO). This enables connecting it to even more objects from Europeana’s providers. The Entity Collection has a higher language coverage than most typical cultural heritage vocabularies: for example, its subjects have labels in 13.1 languages on average. This in turn allows us to provide many objects with more labels: for example, more than 12 million objects are assigned extra topic labels in 17 languages.
The Entity Collection provides a spine to harmonize vocabularies from the many data providers into a single point of reference and build a more homogeneous and multilingual user experience. This work is still in progress, however: we will work to increase the coverage of the Entity Collection, both in terms of resources and languages.
Combining the metadata knowledge graph with automatic translation
While the knowledge graph approach promises relatively high-quality multilingual metadata, we are aware that it will not be enough: there will always be gaps to fill, especially in terms of language coverage. To palliate these issues, our multilingual strategy foresees that Europeana will employ automatic translation as a complement. For example, for the display of metadata in a given language, we foresee that the system will first attempt to retrieve the metadata in that language from the original metadata completed with the knowledge graph. Should this fail, the system will then rely on automatic translation from the English version of its metadata, where this version will have been pre-computed and stored in our system:
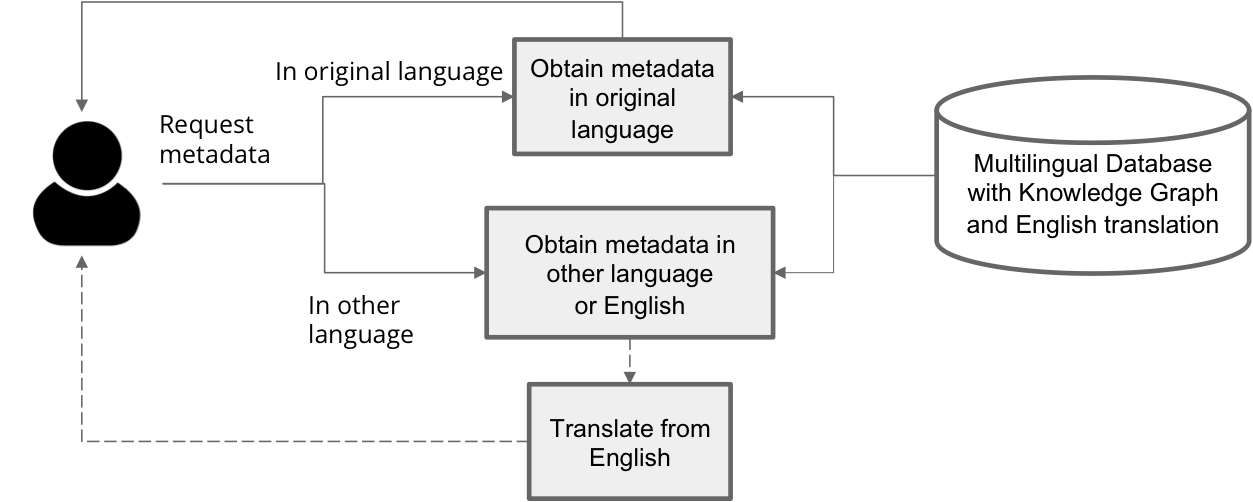
Europeana’s multilingual strategy also envisions the use of English as a pivot language in search. The idea is to detect a query’s language, use the Entity Collection and automatic translation to augment the search string with more languages, and then perform the augmented query against Europeana’s index, which will have been augmented too, thanks to the knowledge graph and automatic translation. This process, shown below, will give more opportunities to match the original query with relevant objects.
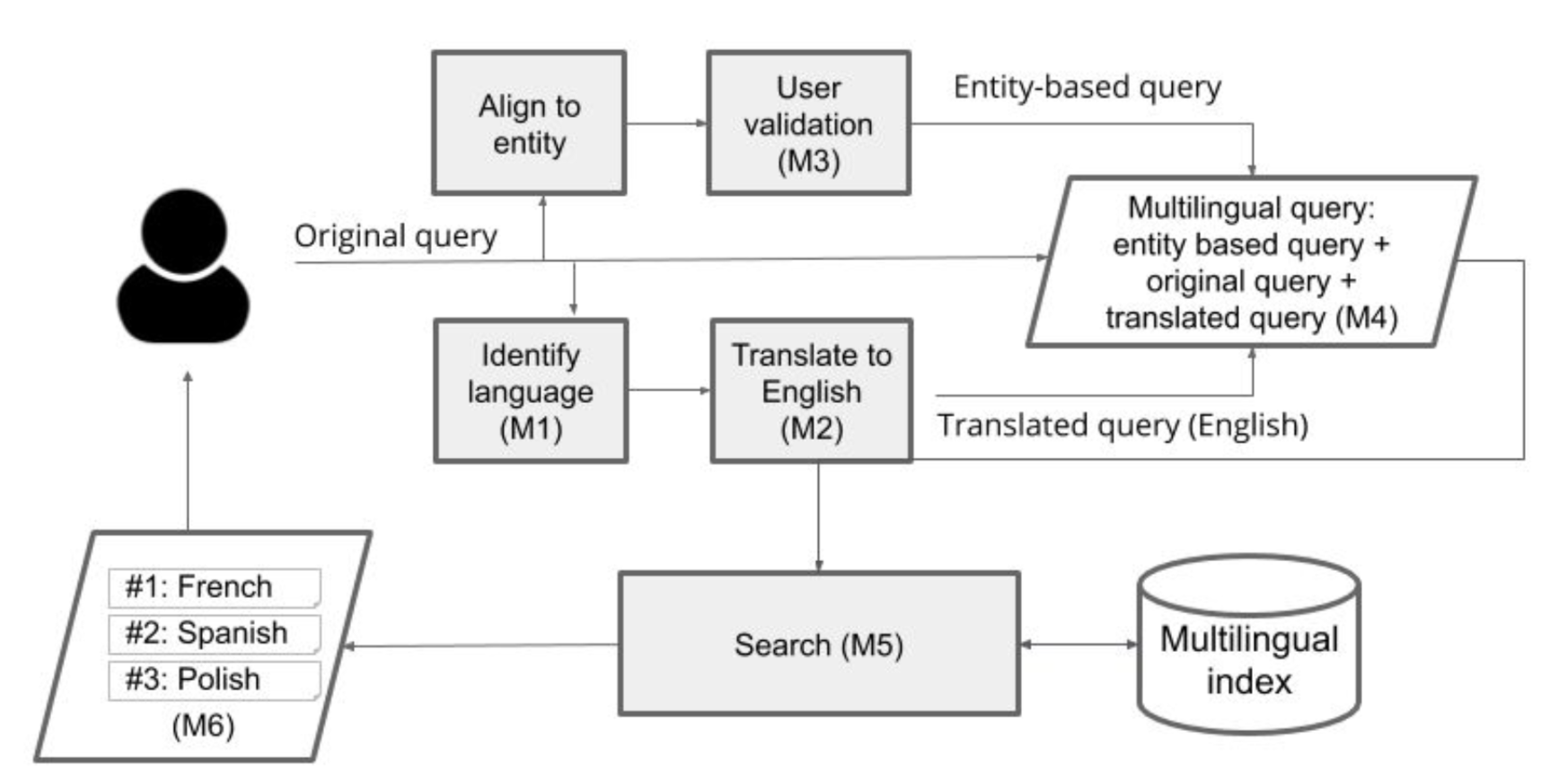
A similar flow is conceived for search over full-text content (for instance, newspapers or transcriptions of documents). The additional steps here are about building on a multilingual fulltext index: identifying the source language of text objects, translating the full-text to English and indexing it in both English and source language.
Europeana still needs to validate many building blocks for these processes. Especially, much remains to be done for experimenting with and ensuring the quality of automatic steps, such as enrichment, language detection and translation.
Content translation and search
Our third case study was, as a matter of fact, a preliminary evaluation of automatic translation. More precisely, we tested query and content translation for multilingual search over full-text documents. We selected 18,257 transcriptions (in 17 languages) of World War I objects from Transcribathons hosted by the Enrich Europeana project. We have used the CEF eTranslation automatic translation service, which managed to provide translations in English for all required languages. We loaded the resulting data in a search index and assessed the resulting cross-lingual search prototype with a sample of 69 user queries from the Europeana 1914-1918 thematic collection.
As expected, cross-lingual results based on English translations of queries and documents add many more results to these obtained with queries and documents in original languages – several hundreds new results in some cases. The question is whether quantity comes at the price of quality. We conducted a first evaluation comparing results with or without automatic translation: it showed that using automatic translation leads to incomplete coverage: extrapolating the evaluation results, we expect that using translation would bring 67% of the records in other languages that are likely to be correct. More worrying, a second manual evaluation hints that in the current experimental setup, 51% of the results are likely to be noisy.
More evaluation was needed, though, as a meaningful comparison between original results and these using translation was possible only for five languages. Hence, we manually assessed the quality of automatic translations for queries. Our first finding is that the translation system mostly struggled to handle the queries that should be left untouched, notably the ones for named entities (persons, places…), including some lesser-known WWI soldiers. A second lesson learnt (or more precisely, confirmed) is that Europeana has to handle a big and long tail of queries, which is a great challenge for query translation. That tail is blurry, too: in some cases, there are typos in the query term or the information need behind a query is not obvious. Another hurdle is wrong language assumption: as our above mentioned user survey indicates, users may query in a language that is not the one we would expect based on the language version of the portal that they use. The case of the query “avion”, found on the Italian version of the portal, is a great example of such issues: has someone used the Italian portal for searching in French for documents about planes, or were they interested instead in the French town spelled Avion in French and in Italian?

These issues confirm the need – encompassed in Europeana’s multilingual strategy – for larger-scale experimentation and validation of the various steps and technologies that will contribute to making Europeana even more multilingual.