Letter from the editors
Clemens Neudecker, Gregory Markus
Newspapers are very abundant everyday objects, yet their significance is unbounded. For one, they are highly valued by researchers. Their contents can be as complex and multifaceted as our daily lives that they try to cover. From lead articles to (personal) ads and obituaries, photographs and cartoons, opinion and satire, weather and financial trends; there has always been diversity in information as well as presentation. To fully capture these contents and make them digitally available in a structured way still involves many difficult technical challenges. But the growing amount of historical newspapers being digitised also opens up new ways to study the past.
In 2014, Europeana Newspapers and The European Library (TEL) launched one of the first transnational digitised historical newspaper collections that included a full-text search of over millions of pages. Quickly this caught the attention of researchers who wanted to apply digital methods like text analysis and statistical data mining to do comparative studies. Soon enough, technical limitations became obvious: the bad quality of the OCRed text, multilingual metadata that was not interlinked - leading to new research in computer science, some of which is covered here.
This EuropeanaTech Insight Issue provides a selection from the kaleidoscope of technical topics and research questions currently revolving around digitised historical newspapers. There are articles describing the development of newspaper portals that meet the needs of the digital scholarly community, articles highlighting the possibilities for machine learning but also those showing the complexities of mapping newspaper metadata, and articles discussing the potential opportunities and methodological challenges of digitised newspapers for the digital humanities.
With this compilation of perspectives we aim to give a broad overview of the various areas of current digitised newspaper research. We hope this will stimulate your interest in these topics and contribute to more engagement with digitised newspapers across the EuropeanaTech community and the various research domains.
Newspaper Navigator: Putting Machine Learning in the Hands of Library Users
Benjamin Charles Germain Lee, Jaime Mears, Eileen Jakeway, Meghan Ferriter, Abigail Potter, Library of Congress
Background
In July 2019, Benjamin Lee submitted a concept paper to the open call for the Library of Congress Innovator in Residence Program. Lee proposed a two-phase project to apply machine learning techniques to Chronicling America, a database of digitized historic newspapers maintained by the National Digital Newspaper Program, a partnership between the Library of Congress and the National Endowment for the Humanities. The two proposed phases of the project consisted of:
- Extracting visual content, including photographs, illustrations, comics, editorial cartoons, maps, headlines, and advertisements from the 16+ million digitized pages in Chronicling America.
- Building an exploratory search interface to enable the American public to navigate the extracted visual content.
Over the past 15 months, this project has evolved into Newspaper Navigator. The first phase resulted in the Newspaper Navigator dataset, which we released in April 2020. The second phase resulted in the Newspaper Navigator search application, which we launched in September 2020. In this article, we will provide a technical and organizational overview of Newspaper Navigator and situate the project within a rich body of work being done to enable computational access to digital collections at the Library of Congress.
Organizational Context
LC Labs, under the Library of Congress’s Digital Strategy Directorate, is the home of the Innovator in Residence program that supports Lee’s work. From an institutional perspective, Newspaper Navigator is one of many collaborative efforts to research and test potential approaches and methods in support of the Library of Congress Digital Strategy. The Digital Strategy lays out a 5 year vision for realizing a digitally enabled Library of Congress that is connected to all Americans, aligned with the Library’s Strategic Plan. The Digital Strategy promises to throw open the treasure chest, connect, and invest in the Library’s future.
LC Labs created an annual Innovator in Residence Program in 2017 to host experts from a variety of disciplines to creatively reimagine or reuse the Library’s digital collections in a project that engages the American public. As a research and development-focused residency, the program gives Innovators an opportunity to produce experiments that showcase current and future possibilities. Just as importantly, it creates a low-risk environment for Library staff to gather information about developing and supporting new modes of service, including possible challenges and their solutions. The program also reflects the Library’s commitment to transparent, open-source, and free-to-reuse experimentation and documentation where appropriate. All of the code for running the Newspaper Navigator pipeline and creating the application can be found in the Library’s Newspaper NavigatorGitHub repository and can be repurposed for other datasets of digitized newspapers or otherwise visually-diverse digital collections.
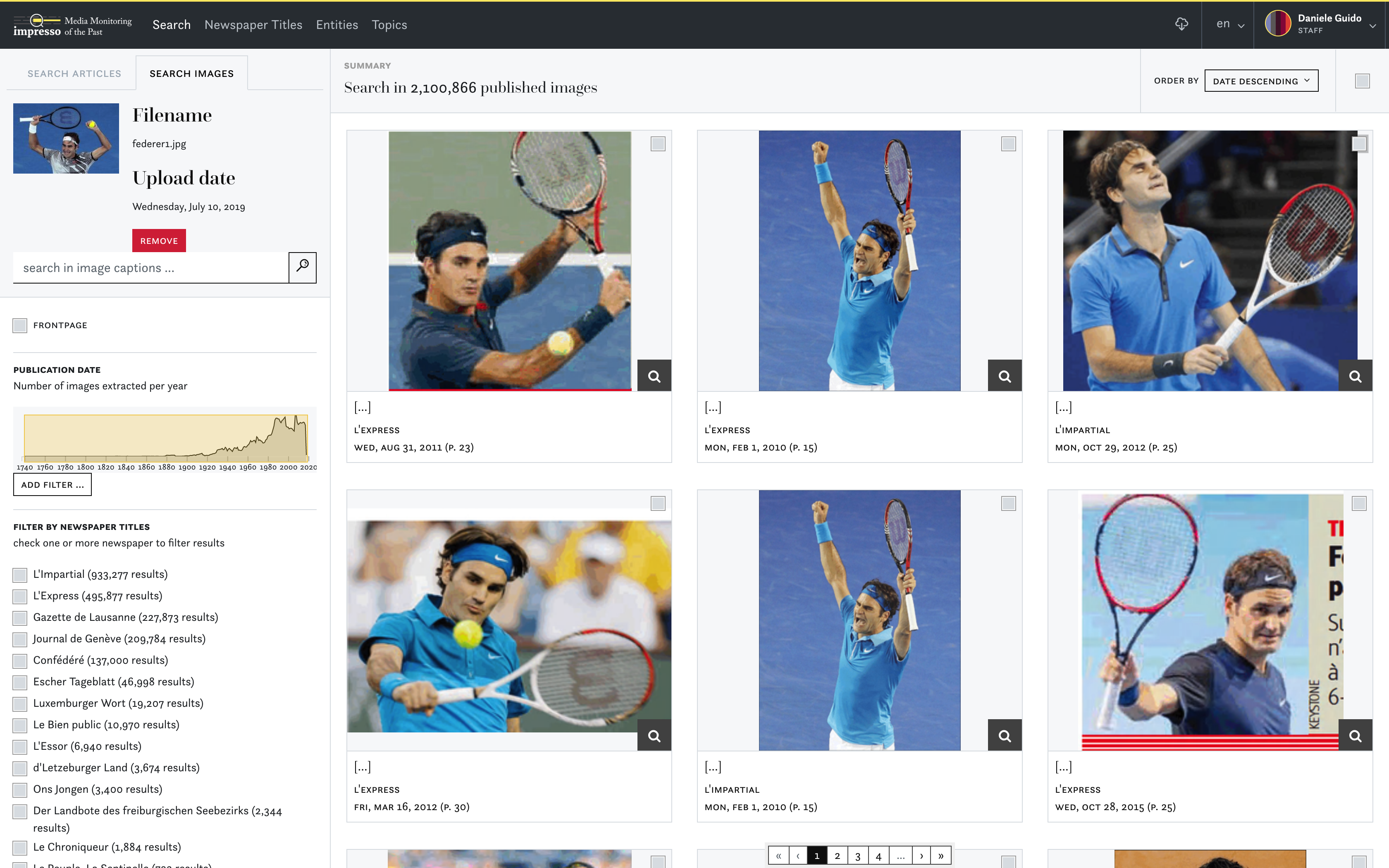
The Newspaper Navigatoruser interface demonstrates creative reimagining, reuse and transparent experimentation, and innovative approaches to digital discovery. A user of the Newspaper Navigator UI can visually browse over 1.5 million photographs from the Library’s historic newspapers using the affordance of visual similarity search and on-the-fly training. The interface and additional ML-derived metadata support serendipitous browsing, through which a user can fluidly refine their focus based on results and, at any point during the investigation, jump to the fuller context of a particular image within Chronicling America.
Technical Overview
In 2017, the LC Labs team launched the Beyond Words crowdsourcing experiment with Information Technology Specialist Tong Wang during a collaborative staff innovator detail. The goal was to engage the American public through the rich visual content in WW1-era pages in Chronicling America and learn about user interests and workflow capacities that could inform future crowdsourcing efforts. Volunteers were asked to draw bounding boxes around photographs, illustrations, comics, editorial cartoons, and maps, as well as transcribe the corresponding captions. To construct the Newspaper Navigator dataset, Lee saw an opportunity to use the Beyond Words data as a source of training data for a machine learning model to learn how to detect visual content on a newspaper page. More specifically, Lee fine-tuned a Faster-RCNN object detection model from Detectron2’sModel Zoo that had been pre-trained on the Common Objects in Context (COCO) dataset using the Beyond Words bounding box annotations, as well as additional annotations of headlines and advertisements. This finetuning required approximately 19 hours on a single NVIDIA T4 GPU.
Throughout the development of Newspaper Navigator, collaborating with the staff of the National Digital Newspaper Program (NDNP) was essential, from understanding the technical aspects of computing against Chronicling America at scale to refining the search interface to best support user needs. Furthermore, Newspaper Navigator relied on Chronicling America’s structured data, standardized batch indexing, and API in order to run the pipeline and serve the photographs in the search application. Perhaps most significantly, Newspaper Navigator benefits from the decades-long genealogy of hard work at the Library of Congress and the National Endowment for the Humanities to digitize and make available a diverse range of American newspapers of historic significance.
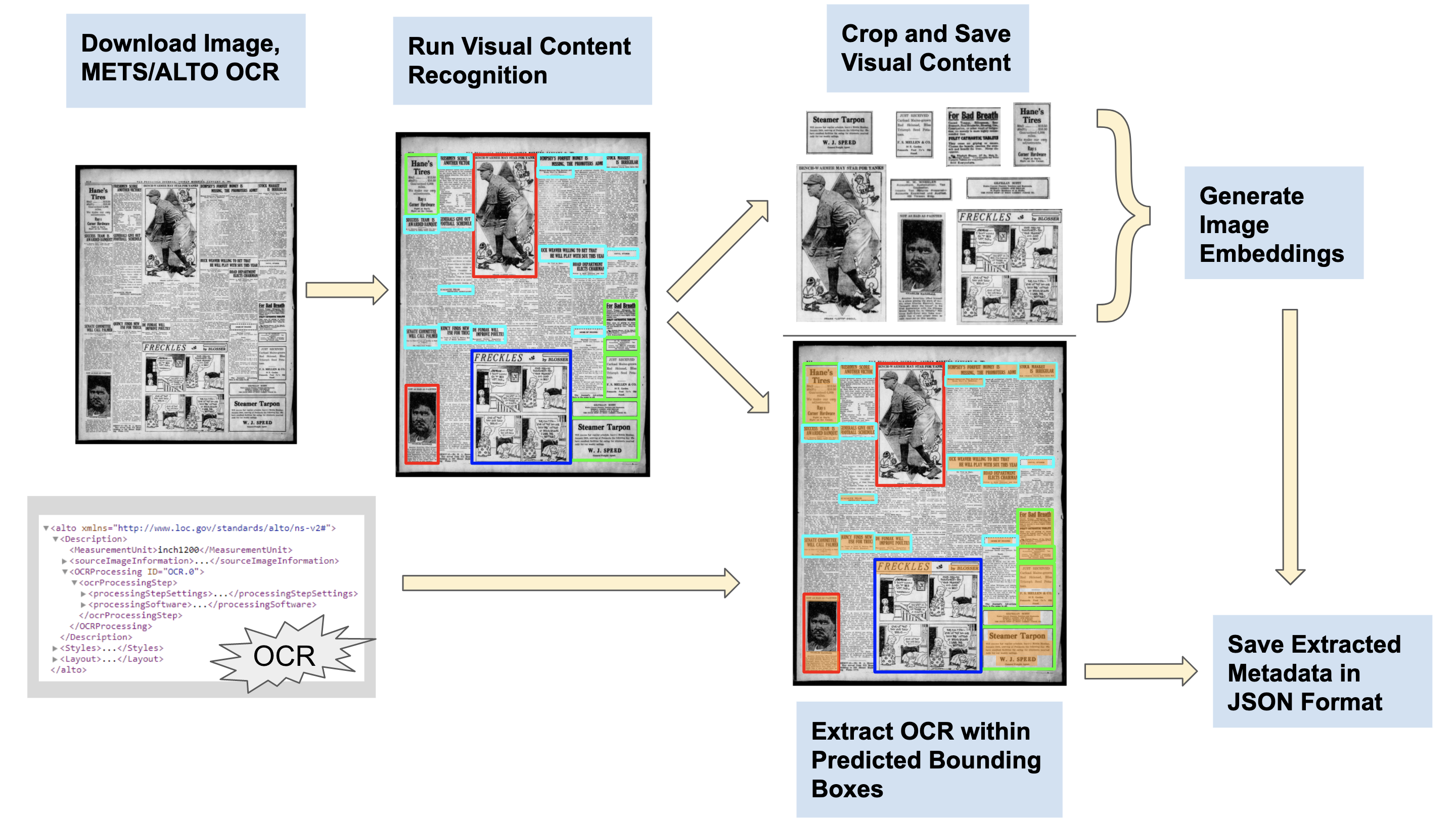
With the visual content recognition model finetuned, Lee then ran the full Newspaper Navigator pipeline, as shown in Figure 1. The pipeline consisted of the following steps for each Chronicling America page:
- Pulling down a high-resolution image of the page, as well as the corresponding METS/ALTO OCR, using the bulk data API for Chronicling America.
- Running the visual content recognition model on the page.
- Cropping and saving the identified visual content in an S3 bucket.
- Extracting the OCR falling within each bounding box as textual metadata.
- Generating ResNet-18 and ResNet-50 embeddings for the extracted visual content (except headlines).
- Saving the metadata in JSON format to an S3 bucket.
In total, the Newspaper Navigator pipeline processed 16,368,041 out of the 16,368,424 Chronicling America pages available at the time of running the pipeline (99.998%). The pipeline required 19 days of runtime on two Amazon AWS g4dn.12xlarge instances, for a total of 96 CPU cores and 8 NVIDIA T4 GPUs. The resulting Newspaper Navigator dataset indexing mirrors the Chronicling America batch structure for ingesting pages, meaning that computing against the dataset should be intuitive for those familiar with the Chronicling America bulk data.
The resulting Newspaper Navigator dataset is entirely in the public domain and can be found at: https://news-navigator.labs.loc.gov/. Researchers can directly compute against the dataset using HTTPS or S3 requests. While the Library of Congress is responsible for storing the dataset, advanced computing has been configured as a “requestor pays” model with S3, meaning that researchers are responsible for covering the cost of data transfer and computing instances. The Library is testing this capability for the first time with this project, as a lead in to the Computing Cultural Heritage in the Cloud project currently investigating possible service models for access to collections in a distributing computing, or “cloud,” environment.
As another mode of access, the dataset has been made accessible in the form of hundreds of pre-packaged datasets according to visual content year and type. To learn more about the construction of the dataset from a technical perspective, please reference the technical whitepaper, “The Newspaper Navigator Dataset: Extracting and Analyzing Visual Content from 16 Million Historic Newspaper Pages in Chronicling America.”
Coinciding with the public launch of the Newspaper Navigator dataset, LC Labs and Lee hosted a virtual data jam, during which 135 participants learned about the dataset and explored it. Participants’ creations ranged from visualizations of thousands of photographs to Jupyter notebooks for processing the pre-packaged datasets to collages of illustrations. The data jam was recorded and is available on the Library’s website.
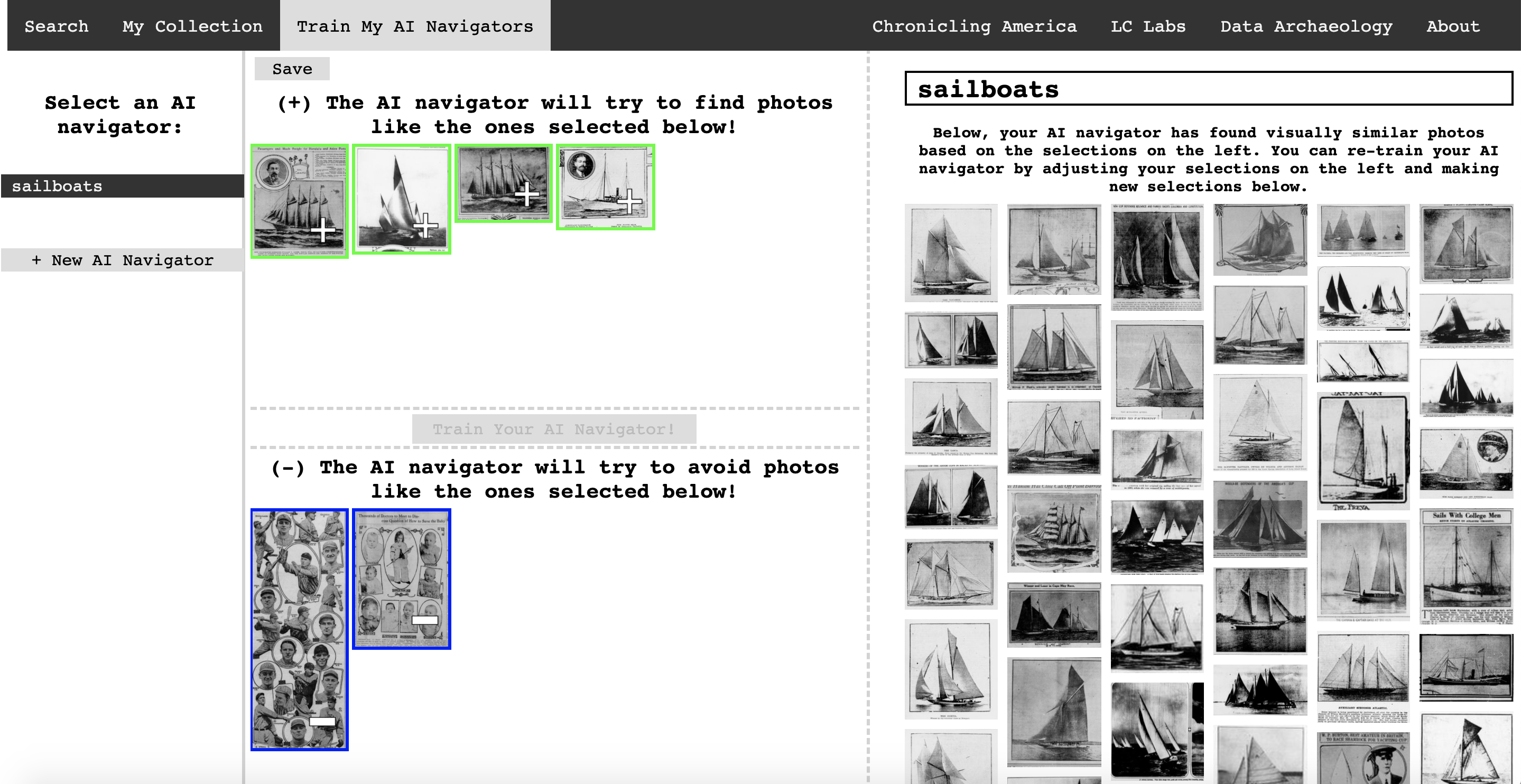
In the second phase of Newspaper Navigator, Lee built a search user interface for 1.56 million photos from 1900 to 1963 in the Newspaper Navigator dataset. In addition to supporting keyword search over the photographs’ captions extracted from the METS/ALTO OCR, the search interface empowers visitors to the site to train AI navigators to retrieve visually similar content on the fly, as shown in Figure 2. In particular, visitors can select positive and negative examples, train an AI navigator, consult the returned results, select or deselect positive and negative examples again, and iteratively train the AI navigator to return better results.
The AI navigators are powered by the 512-dimensional ResNet-18 embeddings that were pre-computed during the construction of the Newspaper Navigator dataset. With each training request, the search app trains a linear model using scikit-learn on the selected positive and negative examples, as well as a thousand negative examples randomly drawn from the unlabeled pool of examples. Lee wrote the application in Python, Flask, scikit-learn, HTML, CSS, and vanilla Javascript, and the application is fully containerized with Docker. For more information, see the code for the search application.
Access to Data
Both the Newspaper Navigatorsearch application and dataset provided the additional opportunity to test technical solutions for providing access at scale to the Library’s free to use content. At roughly 10 TB, the dataset is one of the largest single datasets the Library has ever made available online for public use. Although a version of the dataset is available through direct download through HTTPS and S3 requests, the memory, tools, and computing requirements to download, store, and use a dataset of this size are not widely available on personal computers.
Given these barriers, Lee and LC Labs worked with the Library of Congress Information Technology Design and Development staff to deploy two additional options for access. First, Lee re-processed the dataset and implemented structured URLs so that images with over 90% confidence score could be downloaded along with corresponding metadata (in JSON and CSV format) by type (photographs, advertisements, etc.) and year just by manipulating the URL. The file names are structured as prepackaged/[year]_[visual content type]. For example, to download all of the photos from the year 1905 in JPEG format, a user would construct the url path https://news-navigator.labs.lo.... To download the relevant metadata, one would manipulate the url to https://news-navigator.labs.lo... or .csv to retrieve the JSON or CSV files containing “1905.” Lee and the LC Labs team were able to test this access method during an online data jam in April 2020. During the event, users of varying technical backgrounds were able to use the structured URLs to download, browse, and create with the data sets.
The full 10TB dataset is publicly available in an AWS S3 bucket as an additional access option. With the affordances of the cloud environment and AWS’s “requestor pays” fee structure, users can compute against the dataset without needing to bring it in to their local environment if this method is preferable. This method of access is novel at the Library of Congress and will be explored further with a cohort of researchers over the next two years during the Computing Cultural Heritage in the Cloud (CCHC) project, funded by the Andrew W. Mellon Foundation. As with all LC Labs projects, the results and lessons from CCHC will be shared widely.
Explore, Refine, and Document the Machine Learning
The Newspaper Navigatorsearch application represents the first machine learning application deployed for use by the public by the Library. To successfully launch the search app, Lee and LC Labs again collaborated with colleagues in the Library’s software development and devops organizations to implement a workflow of containerizing the application within Docker, pushing the container to Amazon’s Elastic Container Service, and hosting the application using AWS Fargate. This route toward production eliminated any need to configure or scale virtual machines; it proved to withstand the spike in traffic that accompanied the application’s launch. The containerized search application code can be found at the Newspaper Navigator GitHub repository.
Earlier in this paper, the importance of the Beyond Words crowdsourcing experiment as the training data for the Newspaper Navigator algorithm was highlighted. Lee’s approach to this project was also in dialogue with a series of reports commissioned by LC Labs to consider the implications of adopting machine learning methods for enhancing access to or processing its collections. Both Ryan Cordell’s report “Machine Learning + Libraries: A Report on the State of the Field” and the University of Nebraska-Lincoln AIDA collaboration’s report “Digital Libraries, Intelligent Data Analytics, and Augmented Description: A Demonstration Project” recommended that the Library continues to investigate the impact of machine learning on cultural heritage materials through scoped, demonstrative technical pilots and research collaborations that transparently surface and articulate challenges for consideration before operalization across the organization. The demonstration projects carried out by the Project Aida team constitute the first examples of such lightweight pilots. Operating on a longer timeline and larger scale, the approaches and outcomes of the Newspaper Navigator project build on these methodologies and recommendations. In addition to making all the code for the project publicly available, Lee thoroughly documented his process through white papers and blog posts. Furthermore, he published a data archaeology that traces the implications and limitations of using machine learning for search and discoverability with cultural heritage data.
Conclusion
Newspaper Navigator invites historians, genealogists, educators, students, and curious members of the American public and world to discover a visual history of the United States of America via the rich images preserved within the digitized newspaper pages in Chronicling America. It is our hope that this project also empowers its users by exposing how machine learning works and inspires other projects at the intersection of machine learning and digitized newspapers to be committed to thorough documentation, transparency, and honesty about the technology’s limitations, despite its many promising applications.
Resources
- The Newspaper Navigator search interface (https://news-navigator.labs.loc.gov/search)
- The Newspaper Navigator dataset (https://news-navigator.labs.loc.gov/)
- A technical whitepaper (https://dl.acm.org/doi/10.
1145/3340531.3412767 ) describing the creation of the Newspaper Navigator dataset, which appeared at CIKM 2020 - The Newspaper Navigator data archaeology (http://dx.doi.org/10.17613/k9gt-6685)
- A recording (https://www.loc.gov/item/webcast-9253) of the Newspaper Navigator data jam
- The Newspaper Navigator GitHub repository (https://github.com/LibraryOfCongress/newspaper-navigator)
- LC Labs reports page (https://labs.loc.gov/work/reports/)
Mapping digitised newspaper metadata
M. H. Beals, Loughborough University; Emily Bell, University of Leeds
From 2017 to 2019, a group of researchers from six nations and eleven institutions, funded by the Transatlantic Partnership for Social Sciences and Humanities 2016 Digging into Data Challenge, came together to form Oceanic Exchanges, a project to trace global information networks and examine patterns of information flow across national and linguistic boundaries through the computational analysis of digitised historical newspaper repositories. The project was divided into a dual layer structure, composed of both project-based and national teams. This structure allowed flexibility in the distribution of labour and resources while bringing together a range of expertise—disciplinary and linguistic—across institutions. Among these project teams was the Ontology team, led by M. H. Beals of Loughborough University in the United Kingdom, which catalogued the data and metadata available across these collections, undertook detailed interviews with data providers and libraries, and developed a robust taxonomy for discussing the digitised newspaper as a research object in its own right. Key among the results of this collaboration was the Atlas of Digitised Newspapers and Metadata, a 180-page report that is fully open access and brings together, for the first time, fully comparable histories and detailed descriptions of the contents of ten large-scale newspapers datasets from around the world: the British Library 19th Century Newspapers, Chronicling America, Delpher, Europeana, Hemeroteca Nacional Digital de México, Papers Past, Suomen Kansalliskirjaston digitoidut sanomalehdet, the Times Digital Archive, Trove and ZEFYS.
The Atlas of Digitised Newspapers and Metadata arose pragmatically out of the need for the data from different datasets to be transformed into a single unitary standard that could be put into project workflows across Oceanic Exchanges. Although the basic bibliographical and content fields of a database could be quickly identified, a deeper understanding of the meaning of the metadata—and therefore its full potential for digital research—was difficult to obtain. The nineteenth-century newspaper was a messy object, filled with an ever-changing mix of material in an innumerable number of amorphous layouts; digitised newspapers are no different. Each database contains a theoretically standardised collection of data, metadata, and images; however, the precise nature and nuance of the data is often occluded by the automatic processes that encoded it. Moreover, although there are key projects that have made it possible to bring together different collections, such as Europeana and impresso, no true universal standard has been implemented to facilitate cross-database analysis, encouraging digital research to remain largely within existing institutional or commercial silos. To overcome this, researchers must solve several technical and philosophical challenges.
First, each database uses different language to describe physical objects (for example a newspaper issue, edition or volume), layout terminology (article or advertisement, title or heading), and more abstract concepts (genre, document type). Moreover, each database organises these terms into different hierarchies of classification. Layers of nested items, containers, and technical metadata unique to different standards (and often unique to specific repositories) raise challenging questions about what data matters and what data can be dismissed as too technical to be of interest to the digital humanities researcher. Finally, although there is some truth to the claim that “everyone uses METS/ALTO”, or something very similar, when encoding digitised newspapers, this surface level consistency lulls us into a false sense of security. We are rarely comparing apples to apples—sometimes we are not even comparing fruit to fruit. However, it was not the aim of the Atlas to provide a single “better” standard for digitised newspaper data, a catalogue of what should be across all collections. Instead, our aim was to provide the practical means for comparing and contrasting the data in these collections in a way that makes use of the rich variety of machine-readable and narrative context at our disposal, and allows for new and unexpected connections and mappings to be made in the future. In order to achieve this, the Ontology team pursued two goals: to fully map the metadata—field for field—across these ten collections, and to provide narrative documentation to situate that mapping within the historical and technical context out of which it arose.
Mapping Metadata Across Digitised Newspaper Collections
When we first began mapping the JSON, XML and directory structures of the collections, our plan was to create an ontology and publish it in Web Ontology Language (OWL), a semantic web language that facilitates the machine-readable representation of relationships between things and groups of things. This, we hoped, would assist users in searching across collections by automating some of the process of identifying similar metadata fields. In order to devise the best way of categorising the fields, we attempted to map the metadata into four broad categories: metadata about the physical object, metadata about the digital object, metadata pertaining to both, and text metadata. We added each collection to a visualisation using draw.io (figure 1). Document Type Definitions (DTDs) were particularly useful, as was the Europeana ENMAP profile—not only for understanding the Europeana metadata but also to help infer the parameters of fields in other collections. A closer look at the metadata of our ten collections, however, showed that the standards and documentation were rarely implemented the same way. Rather than entirely unique approaches, what we found were very subtle variations between collections, from basic bibliographic information like publisher, title or date—which might be in a standardised form or taken from the printed object—to more complex content issues such as article genres (whether distinguishing an article from an advertisement or an image, or different types of article) and authorship (which we thought might vary depending on the pen name as printed, a pseudonym used by many people for a specific column, or a named author, but ultimately was a very rare field in any collection).
In creating our dataset, which is freely available to download and contains over 3300 lines representing all possible fields in the ten collections we worked with, we also found that we were replicating this input inconsistency within our team. Our team consisted of fourteen researchers in six countries, each entering the fields, indicating their relationships to each other, and providing a definition drawn either from the documentation or from inference based on the standards, our conversations with archivists, and other grey literature such as reports or conference proceedings. Different team members interpreted this task differently and inputted starkly different levels of detail into the definitions. Ultimately, we needed to employ a stronger editorial oversight than would be possible for metadata entry for a collection with millions of newspaper pages digitised over many years by many different people.
Our dataset includes a unique identifier for every possible metadata field in an XML or JSON file as well as for each layer of the directory structure when these structures served as metadata fields, such as Chronicling America and Papers Past. Based on the existing hierarchy of that metadata and our own historical understanding of, and research into, the history of the newspaper, we devised categories and sub-categories to which the most significant metadata fields are assigned; not all containers have been given a category as we focused on what would be most useful to researchers, beginning with those fields that contained content. These categories are fuzzier than an OWL ontology and take into account subtle variations rather than attempting to provide a primarily machine-readable categorisation. We then give the collection name, the XPath, and information about the format and content type. Example content and multiple-choice values are supplied where relevant and identifiable, and a definition is given. Field and element types are identified, and then, based on the identifier, each field is placed in relation to the other fields within the data file.
Creating an Atlas of Metadata Maps
Thus, what we have created is not primarily a machine-readable hierarchy, though we have also developed a prototype SKOS dataset of the categories so that users might be able to get a sense of how the metadata relates to the structure of the physical newspaper. Instead, we primarily focused on creating user-friendly documentation that can be consulted by researchers inside and outside of the academy in order to find out what data there is within collections and therefore which research questions they might be able to ask of that data.
The Atlas of Digitised Newspapers and Metadata aims to provide this vital context to researchers within a single, dynamic document. It begins with an introduction and our methodology. This is followed by the heart of the report: the histories of each of the ten databases we worked with, based on interviews, documentation and close collaboration, and a glossary that offers a guide to the metadata fields—our metadata ‘maps’. These database histories list the libraries consulted as well as the microfilming projects, digitisation projects and preservation processes that fed into the online collections, in order to illuminate the shape of a digitised collection and the decision-making processes behind it. This is followed by a description of the composition of the digitised collection itself, the data quality, metadata schema, backend structure and user interface, as well as rights and usage. The aim is for researchers to gain a greater understanding of the ideological underpinnings of the collections, as well as their funding and access conditions, becoming aware not only of what is present but also what might be absent.
Our metadata maps are based on the categories our team devised, drawing on expertise in literature, history, periodicals, and data and library science. For each category (such as publication title or issue date), we provide language variants, a technical definition, and usage notes that explain the historical development of the term where relevant, and/or the way that different database providers might understand the term. We also provide examples drawn from scholarly literature and contemporary accounts, to show how the newspaper terminology is understood more broadly, and where there might be ambiguity or variation. Category notes are given to explain how the term is specifically used within the metadata, and individual collection notes discuss the idiosyncrasies of specific collections that users might want to be aware of, such as connections and dependencies with other fields. Finally, the full XPaths for the relevant fields in each collection are included. The structure of each map in the Atlas is designed to provide researchers from different backgrounds with a reference guide that contains the information they might need to make decisions about what fields are relevant to their work and what it will be possible for them to find, bringing together historical context, technical understanding of metadata and file structures, and specific file paths.
Looking Towards Future Newspaper Digitisation and Research
In the development of the Atlas as a narrative resource, and in the hosting of several post-launch workshops with librarians, academics and independent researchers, the Ontology team discovered many examples of best practice, missed opportunities, and tantalising possibilities for the future.
The most important lesson learned was the absolutely necessity for clear, detailed and accessible documentation. In order to create comparable histories and content descriptions of these collections, we needed to bring together a wider range of material including official external-facing documentation—such as that provided by Europeana (data) and Trove (API)—as well as unofficial guides by advanced users, internal (or ad hoc) documentation provide to data entry providers, lengthy interviews with curatorial staff and significant material from academic and industry conferences. This latter material—often speculative or preliminary—was the main source of information about the development of digitisation projects, as legacy documentation on earlier data entry or selection rationales rarely survived into the most recent official documentation. Even so, the Ontology team had to rely at least in part on inference and reverse-engineering of data entry protocols in order create like-for-like documentation throughout—representing an unnecessary, significant and (given the fallibility of human memory and the frequency of staff turnover) irrevocable loss of vital contextual information.
With regard to the use of the Atlas as a user guide and research tool, our workshops made it clear that it currently provides two layers of practical use. On one level, it provides prospective users of these collections—whether through the raw data or the web interfaces—an overview of the possibilities and problematics of these collections. While many users found the level of detail overwhelming, and perhaps not immediately useful to their personal inquiries, the general understanding they gleaned from the very need to document the complex nuances of this field better prepared them to approach these collections with a critical eye. On a more detailed level, it brought to the fore the degree of ambiguity and inconsistency between collections, raising questions of which fields it was possible—in terms of information but also labour costs—to include in various collections and how additional contextual metadata might someday be roundtripped from users back into the collections themselves. Only by laying these out in a complete and detailed manner are we able to accurately judge the extent which have, can or should engage with certain layers of metadata.
As the formal project draws to a close this autumn, with a number of library and user workshops planned for 2020-21, the Oceanic Exchanges team members looks forward to working with additional collection holders to build upon the work represented within the Atlas, either through its direct expansion to include new databases or by linking to additional projects that digital newspaper collections and therefore create a central repository for legacy and dynamic documentation, external metadata and derived datasets. Information about new developments, blog posts with summaries of discussions in our workshops, and use cases for the report can be found on our website.
The German Newspaper Portal: A National Aggregator for Digitised Historical Newspapers
Patrick Dinger, Lisa Landes, Deutsche Nationalbibliothek
Background
Historical newspapers constitute an important source of scientific research in different disciplines – especially in Germany where the newspaper sector was and is particularly diverse and extensive. In recent years, there has been a coordinated approach to digitise many of those newspapers thanks to a funding initiative by the German Research Foundation (Deutsche Forschungsgemeinschaft, DFG). As a part of this funding initiative the German Digital Library (Deutsche Digitale Bibliothek, DDB) is currently developing a national newspaper portal that aims to combine all available digitised newspapers in one platform.
The German Newspaper Portal - A “Sub-Portal” of the German Digital Library
Work on the German Newspaper Portal (Deutsches Zeitungsportal) began in January 2019. Project partners are the German National Library, the Berlin State Library, the Saxon State and University Library Dresden and FIZ Karlsruhe - Leibniz Institute for Information Infrastructure. The aim is to launch a first version of the newspaper portal in March 2021. The most important feature will be a full-text search but there will also be search entry points via calendar, place of publication and newspaper title. An integrated viewer will be used so users can access all content directly in the portal. Rounding off the list of features are stable URLs for each newspaper issue so they can be quoted and linked to reliably.
Germany is a federal state, which is particularly relevant when it comes to culture and cultural heritage. In contrast to other national libraries, the German National Library does not possess extensive holdings of historical newspapers. Instead, this content is found in many different libraries and archives. What the German National Library does possess, however, is experience with building an infrastructure for the nation-wide aggregation of cultural heritage content. Together with 13 partners (among them the project partners of the newspaper portal) it has been developing and running the German Digital Library for more than a decade and the national newspaper portal will be developed as a “sub-portal” of the German Digital Library. This offers many advantages:
- Infrastructure can be reused and workflows can be adapted from existing solutions
- Many institutions who will provide content to the newspaper portal have long been content providers of the German Digital Library so workflows and contracts are already in place
- Most importantly: long-term availability. Steady funding for the German Digital Library has been guaranteed since 2018 and as a sub-portal the newspaper portal will also profit from this.
The Portal and It‘s Users - User Studies and User Feedback Shape the Development of the Newspaper Portal
Scientific Community
As mentioned above, the initial impulse - and funding - to develop a national newspaper portal was given by the scholarly community, especially the (Digital) Humanities. Since students and scientists will be one of the main user groups of the newspaper portal, their needs and expectations were a central driving force: the four core features described above and thus the main work programme of the first phase of the project, were the result of a workshop in 2014 where scientists from various fields discussed the major requirements for a national newspaper portal. Since work on the newspaper portal began in January 2019 a scientific advisory board made up of 14 international experts in the fields of newspaper research and Digital Humanities has supported the project partners with their expertise and feedback. In the summer of 2019 there was another two-day workshop where the advisory board reaffirmed and expanded on the requirements, by highlighting, for example, the need for a feature that allows the compilation and downloading of individually compiled corpora. Further feedback from the scientific community is being gathered by participating in relevant working groups and presenting the project at scientific conferences like the annual conference on Digital Humanities in the German speaking countries (DHd).
General Users
However, the scientific community will not be the only user group interested in a national newspaper portal. Due to the all-encompassing content typically found in newspapers - from political news, to articles on cultural events; from notifications of births, marriages and deaths to information about sports events; from advertisements to classified ads - there will be a lot to interest a more general kind of user as well.
To find out more about this kind of users we conducted two user studies early on in the project. In March/April 2019 there was an online survey (quantitative user study) which was followed in May 2019 by a usability test (qualitative user study).

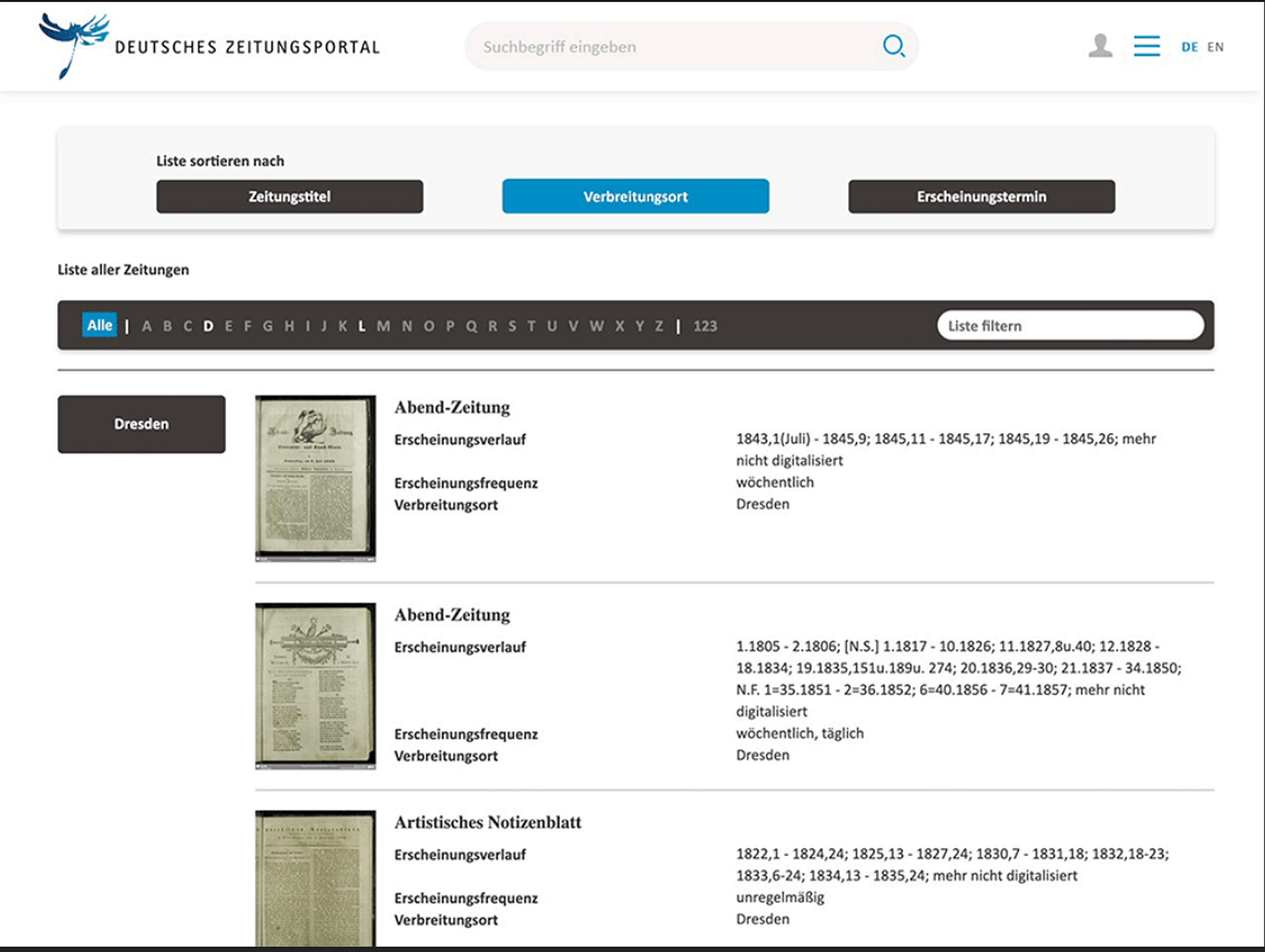
Online Survey
The online survey consisted of 23 questions on subjects like: Who are the users of a national newspaper portal? What kind of content are they looking for? Which features do they consider especially important? It was distributed in March and April 2019 via the websites of the project partners and 30 other relevant channels (blog posts, social media accounts, newsletters, mailing lists). 2,422 completed surveys were received and analysed. Some of the main findings are:
- Among participants there were more men (61%) than women (37%), the majority were from a higher age bracket (more than 60% were over 50 years old). Ca. 75% had a university degree.
- A third of the users would use the portal for personal research (main interests are anything concerning genealogy/local history and specific historical events), another third for job-related research (main interest are newspapers as primary source material) and the final third for both kinds of research.
- Full-text search, filter and browsing functionalities are regarded as the most important features.
Usability Tests
In May 2019 we conducted usability tests based on the then-available click dummy of the newspaper portal. 15 test subjects (5 students, 5 persons form an interested public, 5 persons without any special interest or relevant know-how) had 60 minutes to interact with the click dummy during which they were questioned about their usuals methods of research and given (simulated) research tasks. Some of the results of the online survey could be confirmed by the usability test such as the interest in newspapers as primary source material and the need for easy to use browsing functionalities. Some further results are:
- Most users used Google or university catalogues as entry points for their research
- A substantial amount of searches follow no specific reason, they result from a general curiosity, often triggered by images or randomly acquired information
- Information related to locations (of specific events, of places of publication) was of a high interest to users
- Technical language in the user interface is prone to be misunderstood and acts as a barrier to good usability
Interaction with both user groups - scientific community and general users - has brought us many insights about their requirements which we take into account as far as possible while implementing the newspaper portal. Some points, for example getting rid of technical jargon, will be dealt with in the first project phase, others, like the feature for personal corpora, will be addressed in the second phase.
One Portal - Lots of (different) Metadata
Balancing out the needs of scientific and general users is just one part of the challenge in building a national newspaper portal. Another challenge lies in the homogenisation of the metadata that has to be imported. As mentioned above, the newspapers that will make up the portal come from many different institutions, the so-called “data partners” (mostly libraries and archives), but their metadata must all fit, or be made to fit, the same backend.
Luckily, two important pillars of standardisation have long been in place in Germany: the German Union Catalogue of Serials (Zeitschriftendatenbank, ZDB) and the Practical Guidelines on Digitisation published by the German Research Foundation.
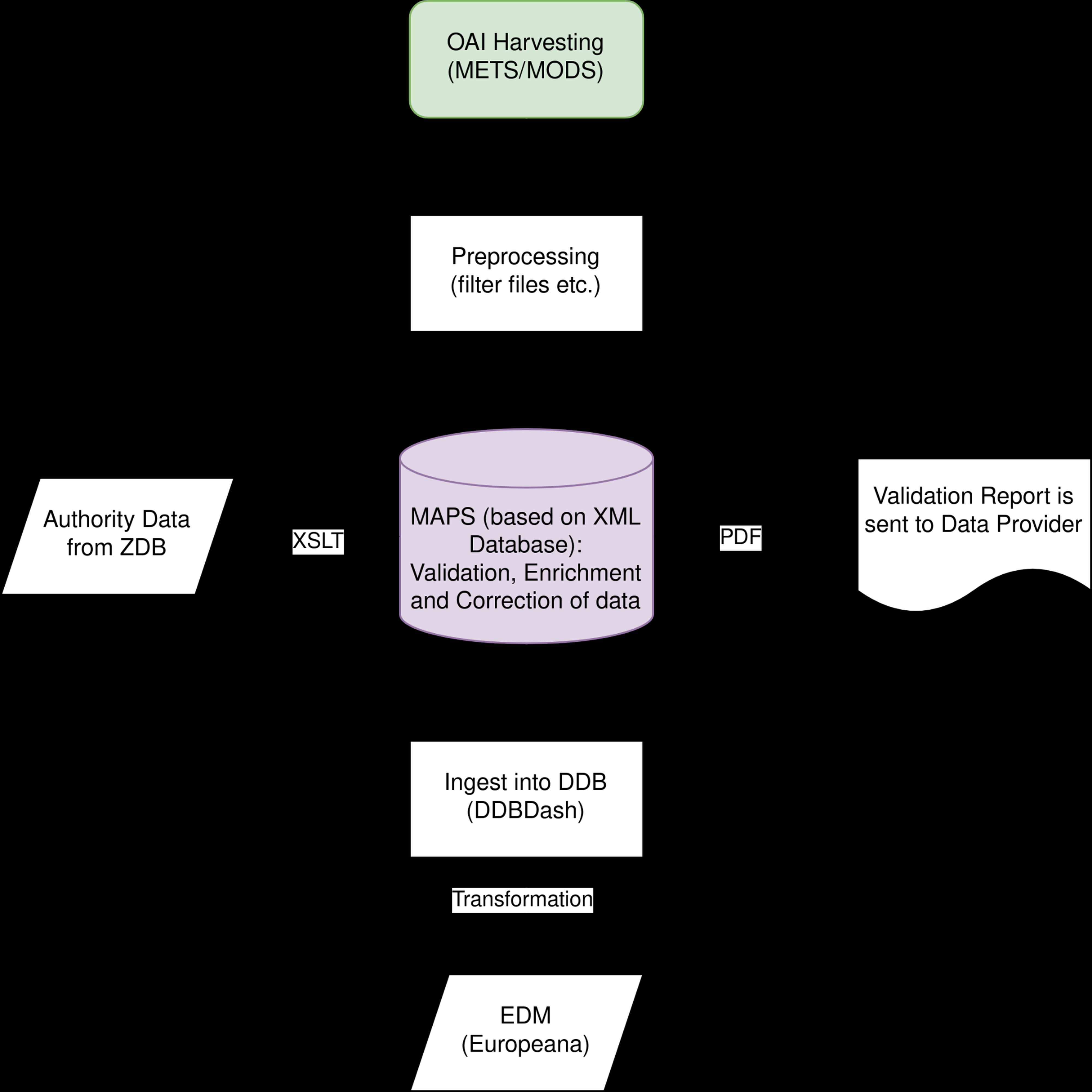
The German Union Catalogue of Serials is one of the world’s biggest databases for periodicals, more than 4,200 libraries in Germany and Austria enter records about the journals and newspapers in their holdings into the database. As it is run by the German National Library and the Berlin State Library, two of the partners building the national newspaper portal, the ZDB is closely connected with the newspaper portal and it plays a key role in the metadata structure of the German Newspaper Portal. Using the ZDB’s persistent identifiers we extract some standardised metadata fields directly from the ZDB database such as the title, place of publication and periods of publication. At the moment this is handled using a data dump but we aim to employ a SRU interface in the future. Besides the ZDB-extracted standardised title information, we use METS/MODS records from the data partners which must comply with the DFG guidelines. However, although the metadata provided by the libraries roughly adheres to these guidelines, the devil is in the details: What do you do, for example, if there are newspapers where a date of publication (which is needed to integrate newspapers into the calendar feature) is missing? Some newspapers lack information about the title in the data for individual issues, the way supplements are assigned to newspapers is handled differently, the list goes on. To deal with these kinds of problems one of the first steps of our data team was to develop and publish a METS/MODS application profile for newspapers and to build a validating software that checks all incoming metadata and automatically generates reports about different categories of issues detected in the metadata. Now, all data partners who supply data (via OAI-PMH Harvesting) receive such a report that gives clear information, if/how their data has to be corrected. Some corrections need to be done by the data providers, some can be taken care of by the data team at the German Digital Library. After the necessary improvements have been made the data is enriched with the information from the ZDB and delivered via our ingest tool “DDBdash” to FIZ Karlsruhe where it is transformed into the different formats necessary for the newspaper portal.
However, despite the available tools and guidelines, working with metadata from a lot of different sources still requires a lot of manual work owing to the various interpretations of such guidelines - it remains one of the biggest challenges in building a national newspaper portal.
The German Newspaper Portal as an Aggregator for Europeana
Once the content from many different libraries has been incorporated into the German Newspaper Portal, however, it has been normalised and standardised and is, thus, in principle also ready for delivery to Europeana. Europeana has launched its own thematic newspaper collection, Europeana Newspapers in 2019 (following a long and complex migration from the service earlier provided by the discontinued TEL - The Europeana Library). Initially, the first Europe-wide digitised historical newspaper collection with full-text was established in the Europeana Newspapers project, for which the Berlin State Library acted as coordinator and has since been responsible for the curation of the thematic newspaper collection in Europeana, putting us in an ideal position for collaboration.
Unfortunately, while Europeana has launched its newspaper collection with the content from TEL, it has not yet built all necessary software components to fully integrate full-text content with the Europeana platform and additional work still needs to be done to re-enable full-text search for the newspapers in Europeana. While this and other required features are added and the newspaper collection stabilized, there is currently no ingestion workflow in place for newspapers with full-text.
Therefore, it is not currently possible for us to deliver our German newspaper collection to Europeana. To integrate the collection of German newspapers, which will soon be available, there are things to be done: First and foremost, METIS, Europeana’s ingest tool, needs to be further developed and adapted for full-text objects. Since the German Digital Library was involved in earlier stages of the METIS development, this will be an opportunity for further collaboration on the ingest infrastructure. Secondly, the Europeana Infrastructure must be ready for the new full-text content with regard to the adaptation of its search, faceting and presentation functionalities.
Things To Come
At the moment our focus is on launching the newspaper portal by March 2021, capping off two years of intensive work. However, the idea was always that a second project phase would be necessary to fully develop a national newspaper portal. Therefore, we submitted our application for two more years of funding to the German Research Foundation in June. If our application is approved, the years 2021-2022 will see the development of advanced features. Besides the possibility for users to compile their personal research corpora mentioned above, we plan to upgrade the portal to enable functions based on article separated data, there will be new interfaces to forward and download the content and we will look at suitable IIIF functionalities, the improvement of existing OCR-files and NER enrichments. And - last but not least - we hope the second project phase will see a successful data delivery from the German Newspaper Portal to Europeana Newspapers, so that the fruit of long years of newspaper digitisation efforts in Germany can also be enjoyed by an international public.
The impresso system architecture in a nutshell
Matteo Romanello, Maud Ehrmann, Simon Clematide, Daniele Guido
Introduction
The decades-long efforts of libraries and transnational bodies to digitize historical newspapers holdings has yielded large-scale, machine readable collections of digitized newspapers at regional, national and international levels [1,2]. If the value of historical newspapers as sources for research in both academic and non-academic contexts was recognized long before, this “digital turn” has contributed to a new momentum on several fronts, from automatic content processing to exploration interfaces and critical framework for digital newspaper scholarship [3]. Beside the multiplication of individual works, hackathons and evaluation campaigns, several large consortia projects proposing to apply computational methods to digitized newspapers at scale have recently emerged (e.g. Oceanic Exchanges, NewsEye, Living with Machines).
Among these initiatives, the project impresso - Media Monitoring of the Past tackles the challenge of enabling critical text mining of large-scale newspaper archives and has notably developed a novel newspaper exploration user interface. More specifically, impresso is an interdisciplinary research project in which a team of computational linguists, designers and historians collaborate on the semantic indexing of a multilingual corpus of Swiss and Luxembourgish digitized newspapers. The primary goals of the project are to improve text mining tools for historical text, to enrich historical newspapers with automatically generated data, and to integrate such data into historical research workflows by means of a newly-developed user interface. The impresso app is a full-fledged, in production newspaper interface with powerful search, filter and discovery functionalities based on semantic enrichments together with experimental contrastive views.

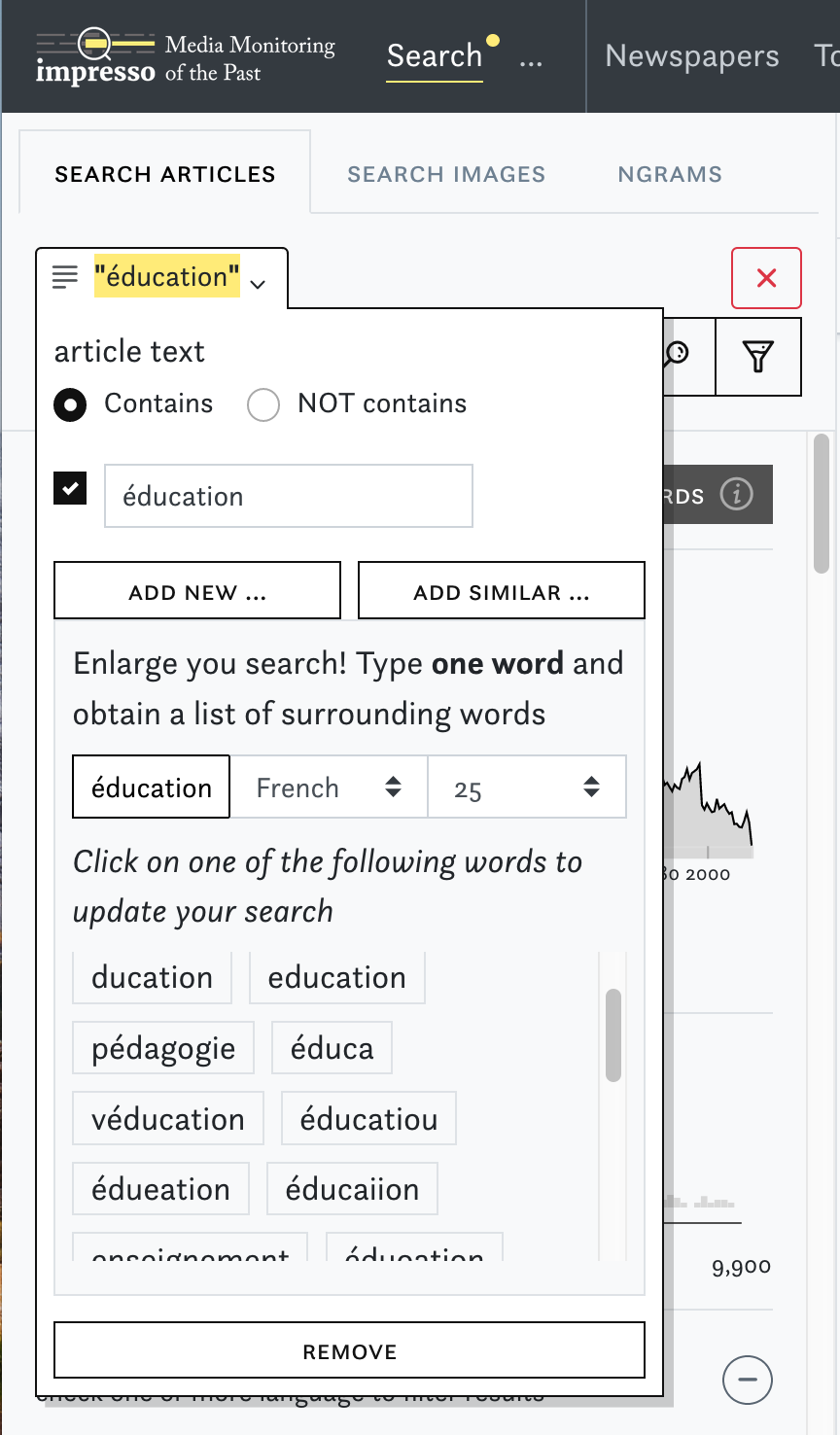
In order to situate the impresso app within the landscape of newspaper interfaces, we can recapitulate different newspaper interface generations identified by [4], based on the survey of 24 interfaces and the analysis of ca. 140 features: the first generation focuses primarily on making content available online, the second on advanced user interaction with the content, the third on automated enrichment, and the fourth on personalization and increased transparency. Fourth-generation interfaces are under development in research projects and the impresso one belongs to this group. Taking a closer look now, the impresso interface leverages a broad range of automatically generated semantic enrichments and allow manifold combinations of the following features: creation and comparison of user-generated collections (cf. screenshot 4 below); keyword suggestions (cf. screenshot 2 below); content filters based on topic models, named entities and text reuse (cf. screenshot 3); article recommendations; exploratory interfaces for text reuse clusters, n-grams and topics; image similarity search (cf. screenshot 5); visualisations of gaps, biases in the corpus and quality scores for OCR and entities. With co-design and experimentation among our core working principles, the interface was inspired by user feedback collected during multiple workshops, and motivated by the overarching goal to seamlessly shift between close and distant reading perspectives during the exploration of a large newspaper corpus. For further information on the project and the interface functionalities we refer the reader to the impresso clip and application guided tour. A more complete overview will be published in [5].
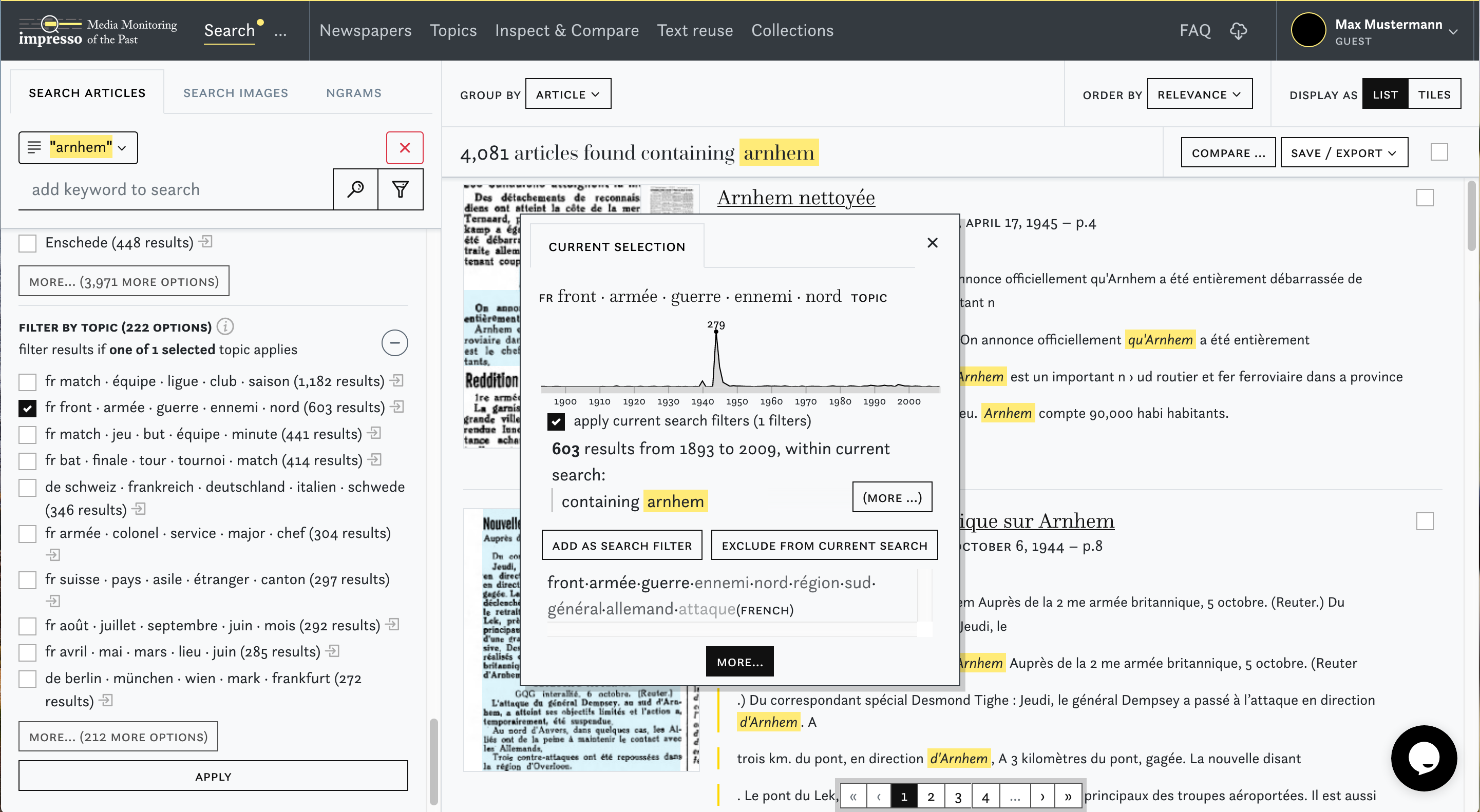
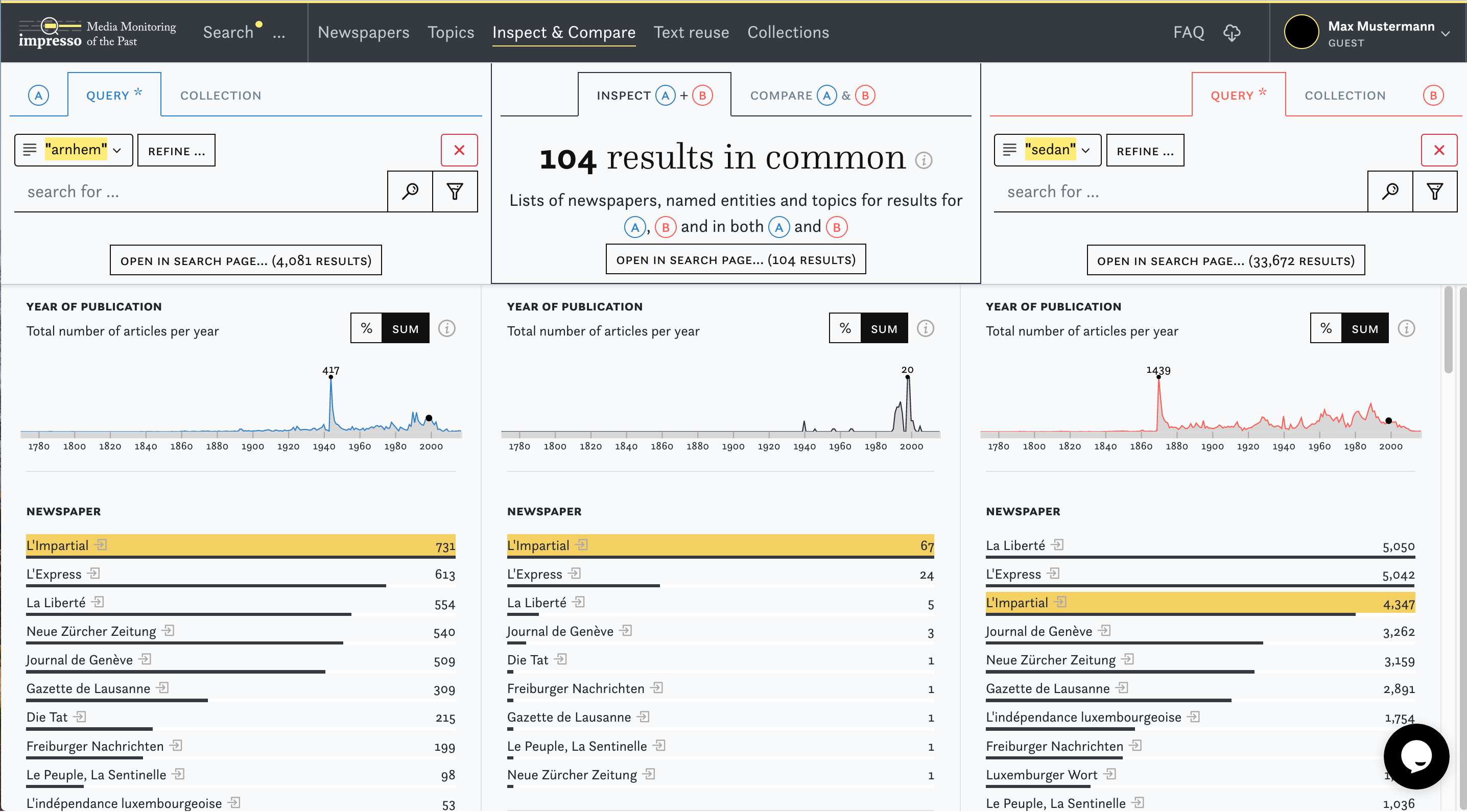
Our objective with this interface is, beyond enhanced access to sources which other portals also provide, to find how to best combine machine and human work. The impresso app targets first and foremost digital scholars and provides tools for the mediation with computationally enriched historical sources. In this sense, the overall purpose is less to enable the discovery of statistically relevant patterns, but rather to facilitate iterative processes characterised by searching, collecting, comparing and discovering which yield insights into historical sources and thereby inform further exploration. The impresso app should be seen as a research prototype, built in the context of a research endeavour and not as an infrastructure project.
That being said, building such an application requires the design and implementation of a solid system architecture. With designers, developers and computer scientists, the impresso team was well prepared for this, but had to face several challenges. Although technical considerations and operations compose the foundations of many cultural heritage-related projects and greatly contribute to shaping their outcomes, they are rarely under the spotlight. With this blog post we wish to do justice to these undertakings, and propose to briefly present the challenges we faced, the solutions we adopted, and the lessons we have learned while designing and implementing the impresso application.
A complex construction site
The development of the impresso app was informed by an array of needs, constraints and activities stemming from different groups of actors, and often looked like a lively but also complex construction site. We consider the entirety of the impresso application, including backend (data storage, pre-processing and processing), middle-layer (API) and frontend. In the following we outline the main centres of influence which shaped this endeavor, whose elements might sometimes overlap.
1. Data (or what are we working with) corresponds to original data or derivative data. Original data is provided by libraries and archives and consists in our case of three types of objects: image scans, optical character recognition (OCR) and optical layout recognition (OLR) outputs, and metadata. Derivative data is the output of various processes applied to original data and corresponds to normalized original data and semantic enrichments of various kinds.
These data feature characteristics which often translate into needs:
- Original data is dispersed on various institutions’ premises, which entails the need to physically acquire and store it (in order to process it), or to have a way to query it, typically via an API. In terms of system architecture and software design, this impacts the initial setup, with the need for storage facilities and/or integration of decentralized data access points, as well as the maintenance, especially with data updates in a distributed context (e.g. change of the IIIF URL scheme by a library).
- Original data have different legal statements, which impacts which and how different parts of the corpus can be used and shared. Beyond the administrative work of copyright clearance, this implies the definition of a data access policy as well as the implementation and management of user login reflecting different data access levels.
- Original data comes in a variety of legacy formats, which entails the need to normalize items (images, OCR outputs, metadata) towards a common format efficient for storage but mostly easy to manipulate and ‘compute on’ in distributed processing environments.
- Original data is often noisy, with respect to both its contents (imperfect OCR) and shape (missing, corrupted or inconsistent collection parts). This requires the development of robust text processing tools, as well as thoughtful and numerous data sanity checks.
- Original and derivative data correspond to huge volumes, with e.g. 70TB for the whole impresso original data, and more than 3TB of compressed textual data (stripped from unneeded information). Beyond storage, such volumes require distributed computing capacities (for processing) as well as hardware and software settings ensuring a good responsiveness.
- Original data can grow, when e.g. a new collection is planned for ingestion, which entails the need for scaling up capacities.
2. Actors/Stakeholders (or who interact with the interface and/or data) are diverse and this entails the consideration of various types of needs or interests. Actors include:
- Scholars, and particularly historians, who compose impresso app’s primary user group. Among many needs related to historical research (which were addressed throughout the project), one point which impacted most infrastructure and processes is the need for transparency, especially concerning the gaps in the newspaper corpus. Besides paying special attention to the treatment of corpus ‘holes’ and inconsistencies, transparency also demands the ability to use versioning to indicate which version of a) the data and b) the platform was used at a given point in time.
- Libraries and data providers in general compose another group, interested in probing new ways to enhance their holdings, in testing their data access points (mainly IIIF et metadata APIs), and in benefiting from – and eventually recover – tools and semantic enrichments. In concrete terms, these interests translate into integration of external services, code and architecture documentation as comprehensive as possible, and derivative data serialisation and packaging.
- Data scientists and NLP researchers, who are mainly after programmatic access to data, which requires a secured and documented API.
Besides continuous dialogue, the presence of various actors often requires different recipes to answer the same need, e.g. access to enrichments via, schematically, a user interface for scholars, an API for data miners, and dumps for libraries.
3. Activities (or what do we do with the interface and/or data). Abstracting away from objects at hand and actors, another perspective which helped formulating requirements corresponds to activities. Without going in too much details, we identified:
Data-related activities:
- search, access and navigate;
- research and study;
- transform, enrich, curate;
- cite.
System-related activities:
- store;
- compute;
- deliver;
- visualise.
Overall, data, actors and activities contribute a diverse set of requirements and compose the variegated landscape we evolved in while building the impresso app. If none of the questions, needs or requirements, taken in isolation, correspond to an insurmountable challenge, we believe that their combination introduces a substantial complexity. Challenges include conflicting requirements, with e.g. the need for both transparency and robustness, and conflicting “timing”, with the need to develop while having the interface already used in production. Beyond this brief overview, the definition of these “centres of influence”, the categorisation of needs and their mapping to concrete requirements deserve further work which is beyond the scope of this post. It is now time to dig into more concrete aspects.
The impresso system architecture
In this section we “dissect” the impresso app along three axes: data, system architecture, and processes.
Data
- As per storage, working copies of original data (images and OCR outputs) are stored on a centralized file storage service (NAS), with redundancy and regular snapshots and secured access reserved to project collaborators.
- Copyright and reuse status of data is managed at two levels. First, via a set of data sharing agreements between content providers and impresso partners (EPFL, C2DH, UZH). Second, users have to sign a non-disclosure agreement (NDA) to gain full access to the impresso collection. Impresso newspapers are either in the public domain and can therefore be used without restrictions (and accessed without login), or are still under copyright and can only be used for personal and academic use (login required). Rights are specified at a year level by data providers, and encoded at the article level in the impresso app. User NDA is accessible on the home page, and the terms of use documented in the app's FAQ.
- Original newspapers data come in a wide variety of OCR formats: 1) the Olive XML format (proprietary); 2) three different flavours of METS/ALTO; 3) an ALTO-only format; 4) the XML-based TETML format, output by the PDFlib TET (Text and Image Extraction Toolkit) which is used to extract contents from materials delivered in PDF format. These heterogeneous legacy formats are reduced to a “common denominator”, namely a JSON-based schema, developed by the impresso project and openly released (see Impresso JSON schemas). Such a schema was designed to respond to the need for a simple, uniform, storage-efficient and processing-friendly format for the further manipulation, processing and enrichment of newspaper data.
System Architecture
- Text data are stored on a cloud-based object storage run by an academic network, accessible via the Simple Storage Service (S3) protocol, which is particularly suitable when distributed processes need read/write access to data. This S3-based storage is used both for the canonical data and for intermediate data that are the result of automatic processing.
- Image data are served by image servers which implements the International Image Interoperability Framework (IIIF) protocol. They are hosted either at the libraries’ premises or on a project’s image server. At the time of writing, the over 54.3 million page images that are searchable via the impresso app are spread over four different IIIF-compliant image servers.
- Indexing of newspaper data (text, images and metadata) is powered by Solr, an open source indexing and search platform. We ingest into Solr both the canonical (textual) data as well as the output of enrichments (topic modelling, named entity recognition and linking, text reuse detection, etc.). The impresso Solr instance contains several indexes (Solr collections) whose elements relate to each other, mainly on the basis of content item IDs (the basic unit of work, either article if OLR was performed, or page otherwise). A Solr plugin was developed to enable efficient numerical vector comparison.
- Finally, a MySQL database is used to store:
- metadata that are not indexed for faceted/full-text search (e.g. descriptive metadata about newspapers, issues and pages);
- user-related data such as login credentials, user-defined collections, etc.
Processes, or Data transformations.
What lies behind the impresso app interface is a complex flow of processes that manipulate, transform, enrich and finally deliver impresso’s newspaper data to the frontend. These processes—most of the times transparent to end users—profoundly shape the data that can be searched and explored via the application:
- Ingestion is the process that consists in reading original data from the NAS storage and ingesting them into different parts of the backend, depending on their type. Text (OCR) is converted into impresso’s JSON canonical format defined in the JSON schemas, and subsequently stored on S3. At this step each content item receives a unique identifier. Images are either accessed directly via content providers’ IIIF endpoints, or converted to JPEG2000 and ingested into the project’s image server.
- Rebuild corresponds to the process of converting text-based data into different shapes, suitable for specific processes. These rebuilt data are transient as they can be regenerated programmatically at any time, and should be thought of as intermediate data that fulfill a specific purpose and whose shape is dependent on the process or tool that is supposed to act on them. For instance, as part of the ingestion process, canonical data are rebuilt into a JSON format that is optimized for ingestion into Solr.
- Data sanity check is meant to verify and guarantee the integrity of ingested data by checking e.g. the uniqueness of canonical identifiers used to identify and refer to newspapers data at different levels of granularity (issue, page, content item), or the fact that a page belongs to an issue (no orphaned items).
- NLP enrichments: original and unstructured newspapers data are enriched through the application of a series of NLP and computer vision techniques which add various semantic annotation layers. These enrichments are: language identification, OCR quality assessment, word embeddings, part-of-speech tagging and lemmatisation for topic modelling, extraction and linking of named entities, text reuse detection, image visual signatures. Since understanding the basics of each enrichment is essential for end users to be able to fully understand how to use the impresso app for their research, a wide array of pedagogic materials was created to this end [6,7], as well as extensive documentation in the application itself (i-buttons and FAQs).
- Middle layer API: It is a software component sitting between the frontend (user interface) and backend API that delivers JSON data to the front-end. It fetches data from different backend components (Solr, MySQL, image servers) and combines them. It also does some intermediate caching in order to speed up performances and enhance the application’s responsiveness. It manages (via processing queues) asynchronous operations that are triggered by user actions (e.g. the creation of user collections) and stores the results of these operations to the backend.
All code is (being) released under the AGPL 3.0 license and can be found on impresso’s GitHub organization page. Code libraries, processes and architecture will be documented in the “impresso cookbook” (in preparation). Derivative data are (being) released as described in [8].
Open challenges
As far as the system architecture is concerned, there remain two main open challenges that will need to be addressed by future research. The first one has to do with dynamic data, i.e. those enrichments such as topic modelling or text reuse that create “entities” that can be referenced via the impresso app. Topic modelling produces topics, each provided with a URI (e.g. https://impresso-project.ch/app/topics/tm-fr-all-v2.0_tp22_fr) and a dedicated topic page; similarly, text reuse yields clusters such as https://impresso-project.ch/app/text-reuse-clusters/card?sq=&clusterId=tr-nobp-all-v01-c111669150764. The problem is that these entities and their identifiers will disappear the next time the NLP processing of the corpus is executed (which happens every time new data are added to the corpus). Currently, the application does not support the co-existence of multiple versions of topic modelling or text reuse outputs, as this would have a substantial impact on the backend storage. Another possibility, which to date remains unexplored, is trying to align with one another successive versions of the same enrichment in order to support some kind of redirection mechanism.
The second open challenge lies in supporting incremental updates to the corpus. Currently, adding new or updated data triggers a complete reingestion and reprocessing of the entire corpus. This situation is relatively frequent as new material is acquired, and content providers may provide updated versions of already delivered content. However, given the multiple backends where data are stored and indexed, as well as the chain of NLP processing that is performed on top, supporting such incremental updates is far from being a trivial task from a system architecture point of view.
References
Hildelies Balk and Conteh Aly. 2011. “IMPACT: Centre of Competence in Text Digitisation.” In Proceedings of the 2011 Workshop on Historical Document Imaging and Processing, 55–160. HIP ’11. New York, NY, USA: ACM. https://doi.org/10.1145/2037342.2037369
Clemens Neudecker and Apostolos Antonacopoulos. 2016. “Making Europe’s Historical Newspapers Searchable.” In 2016 12th IAPR Workshop on Document Analysis Systems (DAS), 405–10. Santorini, Greece: IEEE. https://doi.org/10.1109/DAS.2016.83
Mia Ridge, Giovanni Colavizza, Lauren Brake, Maud Ehrmann, Jean-Philippe Moreux and Andrew Prescott. 2019. “The Past, Present And Future Of Digital Scholarship With Newspaper Collections”. Multi-paper panel presented at the 2019 Digital Humanities Conference, Utrecht, July 2019. https://infoscience.epfl.ch/record/271329?ln=en
Maud Ehrmann, Estelle Bunout, and Marten Düring. 2019. “Historical Newspaper User Interfaces: A Review”. In IFLA WLIC 2019 - Athens, Greece - Libraries: dialogue for change. https://doi.org/10.5281/zenodo.3404155
Impresso team (2021, article in preparation). “Impresso: Historical Newspapers Beyond Keyword Search”.
Estelle Bunout . 2019. “A guide to using collections of digitised newspapers as historical sources”, Parthenos Platform [link].
Estelle Bunout, Marten Düring and C2DH. 2019. “From the shelf to the web, exploring historical newspapers in the digital age”. https://ranke2.uni.lu/u/exploring-historical-newspapers/
Maud Ehrmann, Matteo Romanello, Simon Clematide, Phillip Benjamin Ströbel, and Raphaël Barman. 2020. “Language Resources for Historical Newspapers: the Impresso Collection”. In Proceedings of The 12th Language Resources and Evaluation Conference. https://www.aclweb.org/anthology/2020.lrec-1.121
Who’s in the News? Methodological Challenges and Opportunities in Studying 19th-Century Writers in Historical Newspapers
Jana Keck, Univ of Stuttgart (Institute of Literary Studies); German Historical Institute Washington DC; Moritz Knabben, Univ of Stuttgart (Institute for Visualization and Interactive Systems); Sebastian Pado, Univ of Stuttgart (Institute for NLP)
Introduction
In recent years, two developments have come together: on the technical level, there have been innovations in applying Optical Character Recognition (OCR) to historical texts at scale. At the political and scholarly level, we are seeing an increase in regional and national measures to preserve cultural heritage and to make it accessible to the public. Together, both developments have enabled the mass digitization of historical newspaper collections. For scholars, these digitization efforts enhance opportunities to study newspapers as primary texts for the analysis of historical events, figures, or concepts and to combine quantitative and qualitative methods under the umbrella of Digital Humanities (Sá Pereira 2019), bringing together humanities areas such as literary studies and cultural history and computer science disciplines like visualization and natural language processing (NLP).
Even though creating big data for cultural heritage sounds promising, it triggers computational challenges, since NLP models are predominantly developed and tested on contemporary English-language datasets. Thus, when using methods for data extraction, linking or exploration for digitized historical datasets, several obstacles have to be considered such as noisy OCR, diachronic language change or inhomogeneous metadata schemes.
This article discusses some methodological challenges and opportunities of historical newspaper research on the example of characterizing the reception and impact of 19th-century German-speaking writers using a German-language newspaper corpus based on Europeana. The study is part of the international research project Oceanic Exchanges: Tracing Global Information Networks in Historical Newspaper Repositories, 1840-1914 (OcEx) funded by the DFG, which studies structural, textual, and conceptual network systems of digitized historical newspaper collections.
Case Study: Tracing German-Speaking Writers in 19th-Century German-Language Newspapers
Research Goal
Contemporary authors such as Teju Cole or Stephen King are not only public figures due to their best-selling books, but they also write for newspapers and magazines on personal, social or political topics or raise their voices via social media platforms. As it turns out, this is not a modern development: Already in the 19th century, Mark Twain took on different roles, as a celebrated author of fictional and non-fiction texts, as a travel reporter and as a newspaper publisher and editor. Was he a special case, or was this true for popular authors at large? Our research goal is to develop a method for studying 19th-century authors not from the point of view of their writing, but from the point of view of their reception in the public eye: which authors can be detected in newspapers? How often and in what contexts are they mentioned?
In line with this research goal, we base our investigation on a list of 19th-century authors from Deutsche Biographie. In contrast to shortlists of “canonical” famous literary writers, the Deutsche Biographie list offers an inclusive and heterogenous picture covering over 19,000 literary, political, religious and scientific 19th-century writers, both highbrow and lowbrow.
Processing historical Newspapers
We use issues of a set of 110 German-language Europeana newspapers, predominantly from Germany and Austria. This covers the years 1840 to 1913, corresponding to around 2.7 million newspaper pages with almost 6.3 billion tokens.
Figure 1 outlines a processing pipeline appropriate for investigating person-centric research questions such as author reception on such a corpus. Starting from the Europeana newspaper archive, we first determine relevant pages. Then we recognize all mentions of our set of relevant names using named entity recognition (NER) models. These mentions are further enriched with information -- in our case, with sentiment data, to characterize the type of reception the authors receive -- and statistical analysis can be carried out, ranging from simple ones like counts to sophisticated ones like, e.g., the analysis of the temporal development of person-sentiment correlations across newspapers.
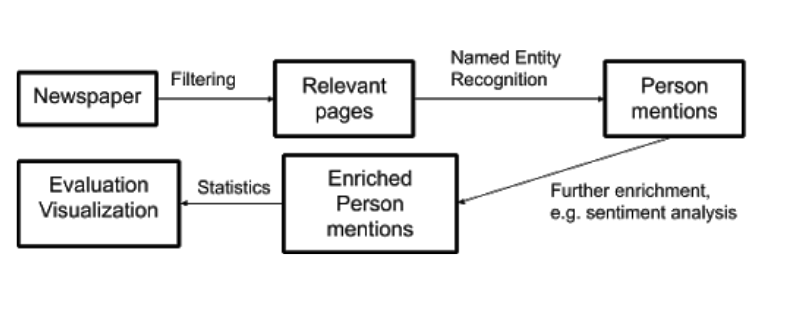
The first challenge of this processing schema is that most available NLP methods are developed for contemporary texts and the models do not take into account diachronic changes. Fortunately, this phenomenon is relatively limited when it comes to proper names (modulo changes in orthography), however, both the contextual features used for NER and lexicon-based sentiment analysis arguably require adaptation. The situation is further compounded by a second serious challenge, namely errors introduced by the OCR methods that are applied to historical newspaper texts at a large scale. The quality varies across pages due to the different physical conditions of the documents and digitization methods.
Regarding NER, we use the system developed by Riedl and Padó (2018). This system is optimized for dealing with historical German texts. It uses subword embeddings, i.e. represents units below the word level, which makes it somewhat robust regarding both OCR errors and diachronic changes since the context words do not have to appear in exactly the same form as in contemporary texts; instead, partial overlap is often enough. In addition, the model is developed using transfer learning: it is first trained on comparatively large amounts of current data with NER annotation and then adapted to 19th century German by continued training on smaller historical corpora with NER labeling (Neudecker 2016).
As for sentiment analysis, we use a dictionary-driven approach based on the sentiment lexicon developed by Waltinger (2010). This lexicon partially includes probabilities for word-sentiment pairs and we use only such pairs for our predictions where the probability is non-zero and there are no polarities with a high probability. This encourages, even though the lexicon was developed on contemporary text, a high-precision analysis with few false positives. We expect that due to the large amount of newspaper data that we are dealing with, even a focus on high precision will leave us with a sufficient number of occurrences of the sentiment-bearing words together with proper names of interest. Another advantage of a dictionary-based approach is that the contextual keywords allow for an immediate manual inspection, in contrast to classifier-based approaches (see also below).
Concretely, we count a mention of a proper name as positive or negative if the name occurs in the same sentence as a positive or negative sentiment marker, respectively. This choice of the sentence level as context is debatable: It is possible that proper names are wrongly counted as, for instance, positive even though the sentiment marker occurs in a different part of the sentence. Conversely, sentiment markers that occur in sentences which contain only pronouns or definite descriptions referring to persons are lost. However, in our experience, in the absence of reliable deeper analysis methods for historical texts such as coreference resolution, the sentence level is a reasonable compromise for the attribution of sentiment.
Results
The interactive data exploration starts with investigating names which have the most occurrences in the time frame 1840-1914. As Table 1 illustrates, there is one name who dominates the picture as regards both positive and negative sentiment counts. It is not one of the usual suspects, not a canonical author like Schiller or Goethe, but a certain Rudolf Mosse.
Mosse is an interesting example not only because the set time frame covers his lifetime (1843-1920), but above all because he was an important figure in the development of the German printing landscape in the 19th century. He was a pioneer in newspaper marketing and the publishing business, being one of the first people to push for advertising in papers, new fonts and layouts (Kraus 1999). His publishing house founded more than 130 papers such as the Berliner Tageblatt (since 1871), the Berliner Morgen-Zeitung (1889) and the Berliner Volks-Zeitung (1904). Before his success as publisher, he was working for several daily, satirical and literary journals such as, for instance, Die Gartenlaube, which was the first successful mass-circulation German magazine and a forerunner of all modern magazines reaching subscribers as far as the German colonies in Africa and German-speaking groups in the Americas.
These activities show that he influenced the German printing sphere behind the scenes, but how come that Mosse turns up as the most frequent author? He is listed in the Deutsche Biographie as such, but most of the occurrences in our newspaper corpus stem from his role as publisher through which he is listed on tens of thousands of title pages (see red boxes in Figures 3+4); he did continue to work as a journalist and writer, though.


Can sentiment analysis provide us with further insights regarding Mosse? In our study, the classification into positive and negative instances turned out to be less useful than we had hoped, not least due to ambiguity: For example, the German word “Druck” is listed as a negative cue due to its sense of “(under) pressure”, while occurrences in newspapers often use its neutral sense of printing.
Nevertheless, sentiment analysis turned out to be valuable as a way to identify relevant (since potentially evaluative) textual contexts in which Mosse's name occurs. In this way, it essentially serves as a rung on a “scalable reading” (Mueller 2013) ladder. For example, this type of analysis has enabled us to categorize Mosse’s different professions, revealing that he also occurred as a public person due to his success as businessman, writer, and philanthropist and as an advocate for liberal conservatism and Jewish matters. Due to the abovementioned OCR problems, it is crucial to retain links to the online archive in the metadata so that close reading can proceed on the digital facsimile.
Even though Friedrich von Schiller has by far not as many hits as Mosse, in his case the classification into positive/negative served as a useful approach to differentiate between texts about his works and his persona. Negative instances such as “Drama,” “Tragödie,” “Trauer,” “Trauerspiel,” “düsteren,” “Schrecken,” “Blut,” “Räuber,” “Gefahr,” or “Eifersucht” were useful to find passages about his works as well as their performances and reception. “Parasit,” for instance, is categorized as negative and guides us to an advertisement of an English translation of Schiller’s play Der Parasit und Neffe als Onkel. The positive sentiments such as “Romantik,” “lieb,” “schönen,” “hochgestellte,” “Ruhm,” “Wiederkehr,” “Recht,” “Bildung,” “Kraft,” “Dichtkunst,” “Verehrung,” “berühmt,” “bekannt,” “Größe,” “poetisch,” on the other hand, lead us to texts, which report on Schiller’s talent and his success such as the article in the Kronstädter Zeitung which describes the proceedings of a Schiller festival in Hermannstadt to praise the writer‘s Dichtkunst and his contribution to nationalistic poetry.
The Mosse and the Schiller case studies open up several structural and methodological, but also theoretical questions as to the setup of our list: who is categorized as a writer in the list? Even though literary canonical writers can be identified in our dataset, these are not the writers who appear most often and continuous in the newspapers. For scholars in the humanities, this approach offers new empirical ways to address questions as to the notion and concept, but also as to the profession and reception of writers in the long 19th century.
Conclusion
The increasing availability of large amounts of digitized historical newspapers from libraries and archives opens the door to exciting new research opportunities. At the same time, digitization introduces its own set of new problems. In our case study, we have identified noisy OCR and diachronic language change as two major problems for linguistic preprocessing.
One problem that we did not touch on in this article is the standardization of metadata across repositories (Beals & Bell 2020), which raises issues for more detailed analyses, e.g. in terms of newspaper sections or publication types. Another problem is the use of keyword-based search to find relevant text passages. Not only is it often difficult to express information needs in the humanities as simple keyword queries, but even in our study, where we are specifically interested in person names, OCR errors presumably make us miss many author occurrences. Techniques like entity linking can offer a way to move beyond keyword search but need to be adapted to the specific domain (De Wilde 2015).
In sum, there is still substantial need for methodological innovations, acted upon by international collaborative research projects like Oceanic Exchanges, impresso and NewsEYE that are developing ways to combine quantitative and qualitative methods. In any case, researchers working with digitized newspapers need to critically reflect upon their methods and make these steps transparent in order to assess the reproducibility and the presence of bias in the results.
Acknowledgements
Oceanic Exchanges (OcEx) is funded through the Transatlantic Partnership for Social Sciences and Humanities 2016 Digging Into Data Challenge. We are grateful to Deutsche Forschungsgemeinschaft for support (grants PR 1080/5-1, PA 1956/3-1, KO 5362/2-1).
References
Melodee Beals and Emily Bell. 2020. The Atlas of Digitised Newspapers and Metadata: Reports from Oceanic Exchanges. Loughborough. 10.6084/m9.figshare.11560059. (http://www.doi.org/10.6084/m9.figshare.11560059)
Elisabeth Kraus. 1999. Die Familie Mosse: Deutsch-jüdisches Bürgertum im 19. und 20. Jahrhundert Munich.
Martin Mueller, 2013. Morgenstern’s Spectacles or the Importance of Not-Reading. In Scalable Reading (blog), 21.01.2013, https://scalablereading.northwestern.edu/2013/01/21/morgensterns- spectacles-or-the-importance-of-not-reading/.
Clemens Neudecker. 2016. An open corpus for Named Entity Recognition in historic newspapers. In Proceedings of LREC. Portorož, Slovenia, pages 4348– 4352.
Martin Riedl and Sebastian Padó. 2018. A Named Entity Recognition Shootout for German. In: Proceedings of ACL, Melbourne, Australia, pages 120-125.
Moacir P. de Sá Pereira. 2019. Mixed Methodological Digital Humanities. In: Debates in the Digital Humanities, chapter 34. https://doi.org/10.5749/9781452963785
Oceanic Exchanges Project Team. 2017. Oceanic Exchanges: Tracing Global Information Networks In Historical Newspaper Repositories, 1840-1914. DOI 10.17605/OSF.IO/WA94S.
Max De Wilde. 2015. Improving Retrieval of Historical Content with Entity Linking. In: Proceedings of New Trends in Databases and Information Systems, Poitiers, France, pages 498-504.
Ulli Waltinger, 2010. GERMANPOLARITYCLUES: A Lexical Resource for German Sentiment Analysis. In Proceedings of LREC. Valletta, Malta.
Doing historical research with digital newspapers – perspectives of DH scholars
Sarah Oberbichler, Eva Pfanzelter, Stefan Hechl; UIBK; Jani Marjanen; University of Helsinki
Introduction
Never before have historical newspapers from the 19th and 20th century been so accessible. Regional and national libraries such as the Austrian National Library (ONB), the Bibliothèque nationale de France (BNF) or the National Library of Finland, to name only a few, have engaged heavily in newspaper digitisation, and with the Europeana Newspapers thematic collection, there is now also a pan-European newspaper portal available that includes free digitized newspapers from 20 countries (including those above), dating from 1618 to 1996. This process of digitization has also shaped the practice of historians. New, digital methods have found their way into their daily practice and they essentially use them in four different areas:

Hence, text pre-processing as well as syntactic word representations, i.e. n-grams, lemmatization, word embeddings, or topic modelling, are becoming more and more important when working with digital newspapers, be it for the structuring (corpus building) or the analysis of historical data (network analysis, pattern or trend analysis, discourse analysis) (Kowsari et al., 2019). Some historians need to create collections for further qualitative analysis (e.g. Gabrielatos, 2007), some use text mining methods to identify linguistic patterns (e.g. Marjanen et al., 2019), others study geographically distributed phenomena (e.g. Borruso, 2008) and others again use digital tools to support their qualitative research questions (Brait/Oberbichler/Pfanzelter, 2020).
The following sections outline the historians' experiences from the NewsEye project in preparing, organising and evaluating historical newspapers and some lessons they have learned.
Source preparation (digitisation)
Source preparation containing all steps of digitisation is one of the starting points for Digital Humanities (DH) scholars when working with large amounts of historical documents. Some corpora already exist in digitised form, but one of the main problems researchers face when using this material is poor OCR quality. This long known problem also concerning digital newspapers affects the research process from the beginning to the end. However, bad OCR does not necessarily have to be accepted as an unchangeable fact. A number of tools exist that allow researchers to manually re-OCR documents. Transkribus, which recently won the EU Horizon Impact Award, is well suited for this task. Within the NewsEye project, a dataset of some 1.5 million pages from the participating national libraries of Austria, France and Finland was re-OCR’ed by the Transkribus team at the University of Innsbruck, using a specifically trained model that had been improved by computer scientists of the project at the University of Rostock. This led to strong improvements in OCR quality.
Although the upload to Transkribus can be time-consuming, the platform is an option available for researchers working outside large projects such as NewsEye or without access to large-scale computing infrastructure. Exploratory research by the NewsEye DH-team showed that even the standard OCR tool implemented in Transkribus (using Layout Recognition and then Abbyy FineReader) can greatly improve the quality of the recognized text for both the Gothic and normal typefaces in historical newspapers (figure 3).

A second approach that the NewsEye team is currently digging into is OCR post-correction. Computer scientists from the Universities of La Rochelle and Helsinki are researching automated tools and methods that do away with the time-consuming re-OCR process. The results so far are quite promising and definitely show the way for further research (Hämäläinen and Hengchen, 2019 and Vinh-Nam et al., 2020).
Searching, structuring, cleaning, categorising, organising and reducing digital newspaper collections
For most humanities scholars, keywords are still key in order to find specific newspaper articles, to limit collections to a topic of interest, or to structure both articles and collections. At the same time, keyword searching goes hand in hand with some serious weaknesses (Bair and Carlson, 2008). Even when taking the above-mentioned issues into account, many search requests are difficult to define conceptually and hard, if not impossible, to trace by a simple keyword search alone. Additionally, when building topic-specific corpora using queries, there is always a compromise between precision and recall, between creating a corpus that contains only relevant texts but not all relevant texts and, on the other hand, creating a corpus that contains all available relevant texts, but at the expense of including irrelevant texts (Gabrielatos, 2007 and Chowdhury, 2010).
Most newspaper interfaces allow advanced keyword searches with a range of search options, but they do not support finding similar or equally relevant keywords and they do not allow tracking changing word usage or spelling mistakes. With the NewsEye Platform (Jean-Caurant and Doucet, 2020), a prototypical interface for digitized newspapers, the partners from the Universities of La Rochelle and Helsinki created possibilities to support keyword searching with the help of word embeddings (so does the Impresso interface Media Monitoring of the Past). Word embeddings are based on the distribution of a particular word in a collection of texts and can be used to detect words that have similar aggregate distributions in large-scale corpora (see Wevers and Koolen, 2020).
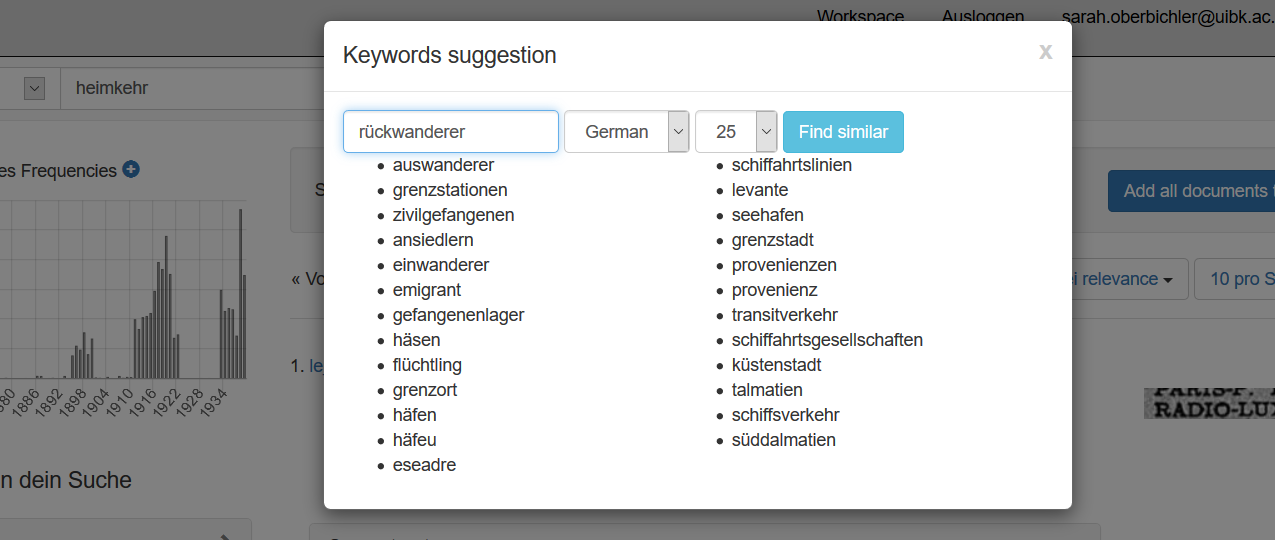
When it comes to the organisation and reduction of digital newspaper collections as well as the export of datasets, many existing interfaces do not support this research step that is, however, necessary for any qualitative approach generally used by historians. Interfaces like Impresso's Media Monitoring of the Past or the NewsEye platform have a strong focus on dataset or sub-corpus building supported by methods like multilingual Named Entity Recognition and Linking or Event Detection. Searches can be added to datasets and (re-)organized, scaled down and enlarged as well as exported to the private workspace. In addition, in the NewsEye platform, the borders of the automatically separated articles can also be adjusted manually if necessary, thus overcoming still ongoing issues with article separation and layout recognition.
NLP methods can also support the classification of relevant and non-relevant articles within a collection by taking the context of keywords into account. Using an approach combining Latent Topic modeling (LDA) and the Jensen-Shannon Distance (JSD) method, a collection on return migration including ambiguous keywords such as “Heimkehr” (returning home) or “Rückwanderung” (return migration) was automatically grouped into topic-relevant and topic-irrelevant articles (see Jupyter Notebook):

Finally, also text mining methods are promising for the structuring of text. For example, text classifiers can automatically analyze text and then assign a set of given categories based on the research topic. This automated classification (see Jupyter Notebook) of text into predefined categories is an important method for managing and processing a large number of newspaper clippings.
Evaluation of linguistic patterns
One clear trend in studying digitized historical sources is a renewed interest in language as an indicator of historical change. Machine-readability has led to searchability, but also allows for counting words, their co-occurrences, and comparing sub-corpora by analysing their word frequencies. Researchers use language data in newspapers as an entry point to studying historical processes that the newspapers reported on, but quite a few historians are also interested in studying the discourse in its own right, that is language itself. Understanding term frequencies and patterns in linguistic change are important in both cases, but especially for latter studies.
The way digital newspaper collections are available affects how researchers can assess term frequencies. With data dumps of full texts, the possibilities to quantitatively analyze and visualize frequency related issues are almost endless, but demand a lot of know-how. Interfaces that we know of provide varying possibilities for researchers to evaluate changes in term frequencies. First occurrences, periods of rapid increase or breaks in occurrences of words are difficult not to notice. But, reasons for changes in frequencies vary, and making sense of them often require possibilities to explore the frequencies from different perspectives (Pfanzelter et al., 2020). Most typically, it is necessary to compare absolute frequencies for different words and newspaper titles which is doable in some interfaces. However, the possibility to normalize frequencies (term frequency per the amount of terms in the corpus), is usually not given. For instance, comparing the occurrences of politically laden words in two newspapers is not very informative unless we can relate them to how many tokens the newspapers published all in all, because only this shows the relevancy of term usage in one particular medium.
There is an easy solution to this: providing the user the possibility of downloading absolute term frequencies as well as the number of all tokens in a search per year. This does not require a lot of effort from the side of the interface provider, but most importantly it does not clutter the interface for the majority of users who are not interested in frequencies. The frequencies themselves are then best analyzed using spreadsheets or scripting.
Term frequencies, absolute or relative, are very basic information when it comes to analysing masses of texts. This makes it incomprehensible why reliable and usable ways to explore frequencies in digital newspapers collections are not readily available. In many cases, more advanced methods are put into place before simple frequency tools. This is problematic because more elaborate methods, such as those relying on topic models or word embeddings, are always related to frequencies. To understand more complicated methods, we need to understand changes in frequencies.
Qualitative content and discourse analysis
Newly developed approaches can support historians in many research steps. This does not end when it comes to qualitative evaluation of newspaper reporting. Annotation is fundamental for content or discourse analysis. Recently developed interfaces for historical newspapers, such as Impresso's Media Monitoring of the Past or the NewsEye platform, show how enriched data and new methods could ultimately improve access to historical (newspaper) collections. But they do not offer any methods or functions to enable semi-automated annotation of the collections created. What they do offer, however, is a variety of download options to facilitate further processing. Qualitative analysis softwares such as MAXQDA, ATLAS.ti, or CATMA allow the import of such collections. Besides the versatility and flexibility, the strengths of these qualitative software products lie in their applicability for various methodological approaches and procedures, such as data connection, structuring and data output or the representation of conceptual contexts, for example in the form of semantic structures.

For historians, (semi-)automated methods will only have a significant impact and be relied upon if sound qualitative or discourse research is doable. Until then, the debates about whether “digital history” is merely an auxiliary science or will fundamentally change the discipline itself are bound to continue (Patel, 2011, Koller, 2016 and Burkhardt, 2020).
Conclusion
No matter if digital methods are applied for quantitative or qualitative evaluations, the tools as well as the outcomes should be critically tested and reflected. Digital source and tool criticism – the reflection on the impact of digitization and tools on the knowledge production – therefore has to become an integrative practice for digital historians (Pfanzelter, 2015). Although users often find it difficult to understand how tools or methods work exactly, they should be (made) aware of how the tools interact with their research data in order to be able to rely on the results. Interfaces provided by libraries or archives, which are not tailored to the needs of historians, make source, tool and corpus criticism often difficult, which is why it is important to increase cooperation between different disciplines and institutions. The advantages of multidisciplinarity can clearly be seen in one of the prototypes of the NewsEye project, the platform, which gives a glimpse into different handlings of historical source material by historians, linguists, computer scientists, librarians and many others.
Acknowledgment
This work has been supported by the European Union’s Horizon 2020 research and innovation programme under grant 770299 (NewsEye).
References:
Sheila Bair and Sharon Carlson, “Where Keywords Fail: Using Metadata to Facilitate Digital Humanities Scholarship,” Journal of Library Metadata 8, no. 3 (October 8, 2008): 249–62, https://doi.org/10.1080/193863....
Emanuela Boros et al., “Robust Named Entity Recognition and Linking on Historical Multilingual Documents” (Working Notes of CLEF 2020 - Conference and Labs of the Evaluation Forum, Thessaloniki, 2020).
Giuseppe Borruso, “Geographical Analysis of Foreign Immigration and Spatial Patterns in Urban Areas: Density Estimation and Spatial Segregation,” in Computational Science and Its Applications – ICCSA 2008, ed. Osvaldo Gervasi et al., Lecture Notes in Computer Science (Berlin, Heidelberg: Springer, 2008), 459–74, https://doi.org/10.1007/978-3-....
Daniel Burckhardt et al., “Distant Reading in der Zeitgeschichte. Möglichkeiten und Grenzen einer computergestützten Historischen Semantik am Beispiel der DDR-Presse,” Zeithistorische Forschungen, no. 1 (2019): 177–96, https://doi.org/10.14765/ZZF.D....
Andrea Brait, Sarah Oberbichler and Eva Pfanzelter, “Annotieren – visualisieren – analysieren. Computergestützte qualitative Methoden für die Zeitgeschichte”, Sonderheft, zeitgeschichte, no. 4 (2020), 435–519.