Issue 13: OCR
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community
Optical Character Recognition is an essential resource for cultural heritage institutes working to make their text content available for users. OCR in this regard is, in its simplest terms, the process of converting digital scans of historical documents into full-text. It then allows for full-text search, making exploration and searching material much more accessible for users thus making it easier to find what they’re looking for.
Yet despite how far OCR has come, there are still many challenges institutes face including non-latin alphabets and article detection. With this issue of EuropeanaTech we highlight three use-cases related to OCR and show the types of problems different organizations encounter and how they work to solve them.
The inspiration for this issue of EuropeanaTech Insight came from the 2019 DATeECH conference attended by EuropeanaTech Steering Group chair, Clemens Neudecker. The event was an incredible showcase of projects working to improve the creation, transformation and exploitation of historical documents in digital form.
For Europeana, OCR has been integral perhaps most visibly in the Europeana Newspapers and DM2E (Digital Manuscripts to Europeana) projects. Both projects delivered millions of text records to Europeana and each encountered many challenges related to OCR including just understanding how accurate the automated OCR actually is. If the OCR is inaccurate, then additional features such as Named Entity Recognition are made increasingly more difficult. But the consortium has continued to grow and improve the initial work done by the Europeana Newspapers project resulting in a new presentation of this material online.
Just over a month ago, the new Europeana Newspapers Collection was published on Europeana. Users can explore millions of pages from over hundreds of newspapers from around Europe. Most of the texts have been OCRed making it very easy for users to search and browse through the portal or for researchers to get full-text extractions via the API. Both of which you can do now at: https://www.europeana.eu/portal/nl/collections/newspapers
We hope you find the below articles insightful and if you or your institute are working on OCR or presentation and access to textual resources, let us know. We’d love to share your work as well!

The digitisation of books, newspapers, journals and so forth. must no longer stop with the scanning of said documents - nowadays users and researchers demand access to the full text, not just for search and retrieval but increasingly also for purposes of text and data mining. However, Optical Character Recognition (OCR) - the process of having software automatically detect and recognize text from an image - is still a complex and error-prone task, especially for historical documents with their idiosyncrasies and wide variability of font, layout, language and orthography. In the past, various projects and initiatives have been working on improving OCR for historical documents, e.g. the METAe and IMPACT projects in the EU or the eMOP project in the US. Yet, despite these efforts, many areas of OCR are still lacking the desired performance, as an OCR research agenda from Northeastern University again confirmed.
"Optical character recognition is... a very difficult problem" is the truest thing I've heard all week.
— Hannah Alpert-Abrams (@hralperta) July 12, 2019
Fortunately, recent breakthroughs in machine learning technologies like deep recurrent and convolutional neural networks now allow for the production of high quality text recognition results from historical printed materials via OCR whenever sufficient training material is available for a given document type. In particular, the availability of open source OCR engines that utilize deep neural networks has benefitted with “classic” OCR engines Tesseract and OCRopus being complemented with other new OCR tools like Kraken or Calamari (both originally based on OCRopus).
Nevertheless, OCR is a comprehensive process that typically includes a sequence of multiple steps in the workflow: in addition to the pure recognition of letters and words, techniques such as pre-processing (image optimization and binarization), layout analysis (detection and classification of structural features such as headings, paragraphs, etc.) and post-processing (error correction, voting) are applied. While most of these steps can also benefit from the use of deep neural networks, no free and open standard tools and related best practices have emerged so far.
This is where the work of the OCR-D project, funded by the German Research Foundation (Deutsche Forschungsgemeinschaft, DFG) comes in. The main aims of OCR-D are to examine OCR tools and recent literature and to describe how these findings can improve workflows for mass-digitization of printed historical material to produce texts of sufficient quality for scholarly analysis.

To accomplish this, a coordination group was assembled comprising of a major digital humanities partner, the Berlin-Brandenburg Academy of Sciences and Humanities, who also operate the German Text Archive (Deutsches Textarchiv, DTA), two libraries with comprehensive holdings of historical prints, the Herzog-August Library Wolfenbüttel and the Berlin State Library as well as the Karlsruhe Institute of Technology who contribute their ample experience in big data processing. Together, these institutions performed a gap analysis that led to the funding of overall eight separate OCR-D module projects that develop open source components for various steps of an OCR workflow.
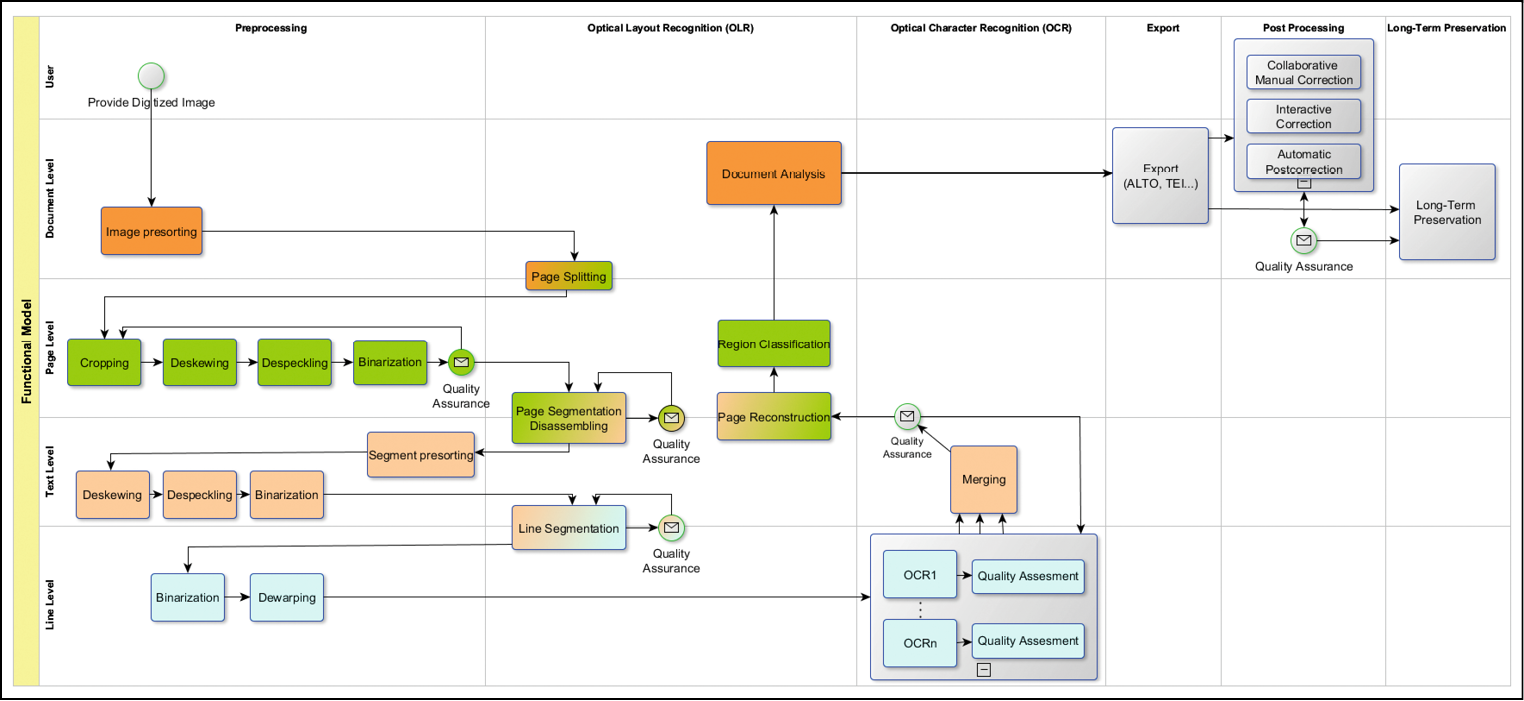
In order to ensure the useability and interoperability of the diverse OCR components developed by the module project partners, the OCR-D coordination group defines a set of specifications based on established standards and also provides a reference implementation in Python.
First and foremost, OCR-D decided to employ the METS metadata container format as the main means for data encoding and process communication. METS is a long standing and widely used standard for encoding descriptive, administrative, and structural metadata about digital objects. Furthermore, all digitization projects funded by the German Research Foundation have to deliver a standardized METS file anyway for each digital object in order to be compatible with the DFG-Viewer, a remote presentation system for digital objects. OCR-D utilizes this METS and extends upon it in some ways to allow e.g. the capture of provenance information.
The actual full text obtained by OCR is then encoded in the PAGE-XML format, which has been established as the richest format in the pattern recognition community by means of its use in scientific competitions and various research projects. PAGE-XML can encode more information about the text than e.g. ALTO - however, for purposes of presentation, OCR-D will work on crosswalks between the PAGE-XML and ALTO formats. All the software modules developed in the wider context of OCR-D need to be described in a JSON Schema file. This holds the information about the required (and optional) parameters for a tool, as well as information like version number, model used etc. All OCR-D software tools also need to provide a Dockerfile that makes it easy to install and deploy the tool across a range of IT environments.
Finally, to support the standardized exchange of data between tools, data and repositories as well as for archiving purposes, an OCRD-ZIP format has been specified which builds on the BagIt standard.
In order to decrease the effort for developers of algorithms for OCR, OCR-D also maintains a reference implementation of the specifications in the Python programming language.
Another central task within OCR-D is the development of a comprehensive Ground Truth corpus that includes reference and training data as well as the according transcription guidelines. Ground Truth is the perfect, i.e. error-free, result of text and layout recognition typically produced by manual double-keying. Ground Truth is used both for the evaluation and training of text and layout recognition software models.

Ground Truth Data already produced within OCR-D, as well as the according transcription guidelines (currently available only in German, a translation into English is foreseen) can be obtained from the OCR-D research data repository.
A total of eight module projects were granted by the DFG in 2017 and have since started their work on researching methods and software development. In the following section, the goals and approaches of each module project are briefly described.
1) Scalable Methods of Text and Structure Recognition for the Full-Text Digitization of Historical Prints" Part 1: Image Optimization
The first project by the German Research Center for Artificial Intelligence (DFKI) Kaiserslautern is concerned with the identification, development and integration of suitable tools for image optimization. It delivers tools for image dewarping, deskewing, cropping and despeckling based on state-of-the-art methods. Finally, as many methods for OCR and layout analysis internally operate on bitonal (black-and-white) images, two binarization methods developed by DFKI will be integrated into OCR-D.
2) Scalable Methods of Text and Structure Recognition for the Full-Text Digitization of Historical Prints" Part 2: Layout Analysis
Next to the actual text recognition, the most important component of OCR is layout analysis, which is the task of the second project by DFKI. In layout analysis, images are segmented into individual blocks/regions, and subsequently text lines that are then fed to the text recognition engine. Due to the fact that current neural-network based text recognition methods operate on text line images, the subsequent segmentation of lines into words and words into characters are no longer required.
3) Development of a semi-automatic open source tool for layout analysis and region extraction and region classification (LAREX) of early prints
The goal of the project by the Julius-Maximilians-University of Würzburg is the further development of the semi-automatic open-source segmentation tool LAREX and its integration into OCR-D. The preliminary work LAREX (Layout Analysis and Region EXtraction) allows both a coarse segmentation by separation of text and non-text and a fine segmentation by detection and classification of different textual entities. LAREX utilizes an efficient implementation of the connected component approach.
4) NN/FST - Unsupervised OCR-Postcorrection based on Neural Networks and Finite-state Transducers
The project by the ASV group of the University of Leipzig aims to develop a ready to use software for postcorrection. In this module, neural networks are combined with finite-state transducers (FST) in a noisy-channel model for fully automatic correction of OCR errors.
5) Optimized use of OCR methods - Tesseract as a component of the OCR-D workflow
It is in perfect alignment with the concept of OCR-D that the module project operated by the Mannheim University Library does not develop yet another OCR engine, but instead will concentrate its efforts on the fine-tuning, optimization and integration of the Tesseract OCR engine into the OCR-D framework. Tesseract is a Free Software for text recognition and has a history of more than 30 years of continuous development and improvements.
6) Automated post-correction of OCRed historical printings with integrated optional interactive post-correction
Post-correction of existing OCR is the main topic of the project by the CIS group from the Ludwig-Maximilians-University Munich. Based on previous work in the IMPACT project such as the creation of an OCR profiler and the interactive PoCoTo tool for post-correction, the project develops a machine-learning based and fully automated post-correction system for historical documents and integrates it with the OCR-D framework.
7) Development of a Repository for OCR Models and an Automatic Font Recognition tool in OCR-D
The project is a collaborative effort by Johannes-Gutenberg University Mainz, University of Leipzig and Friedrich-Alexander University Erlangen-Nürnberg and will allow the use of OCR in a font-specific manner with limited effort. In order to achieve this the project has three main objectives: The development of an online training infrastructure that allows specific models to be trained for these font groups and at the same time for different OCR software. Development of a tool for the automatic recognition of fonts in digitization of historical prints. In this case, an algorithm for the recognition of fonts is first trained using the ground truth found in the Typenrepertorium der Wiegendrucke. In a second step the fonts are grouped according to their similarity in order to get as few groups as possible while maintaining OCR accuracy.
8) DPO-HP - Digital Preservation of OCR-D data for historical printings
With the improvement of OCR quality for historical printed documents comes a greater use and demand from the scholarly community who want to analyse, study and work with OCR resources as research data. This entails requirements with regard to long-term availability, citation and versioning of OCR data. A sustainable preservation and identification of the images, the bibliographic metadata as well as the encoded full texts and their versions is obligatory for these purposes. In this collaborative project by the Göttingen State and University Library and GWDG, a standardized concept is created in order to ensure this.
Over the course of 2019 - 2020, the module projects develop prototypes that are then being tested and subsequently integrated into the OCR-D framework. After this second phase has been successfully completed, a third phase is foreseen where the OCR-D framework and modules shall be optimized for high throughput and robustness, and integrated with digitization workflow software such as e.g. KiToDo.
It is our hope that the provision of a comprehensive and fully open source OCR framework for historical printed documents leads to the use and adoption of OCR-D tools and best-practices internationally and that the release of open tools and resources contributes to further advances in the wider OCR community.
OCR-D Website: http://ocr-d.de/eng OCR-D
Specifications: https://ocr-d.github.io/ OCR-D
Module Projects: https://ocr-d.github.io/projects OCR-D
Source Code: https://github.com/OCR-D/ OCR-D
Repository: https://ocr-d-repo.scc.kit.edu/api/v1/metastore/bagit
OCR-D Chat: https://gitter.im/OCR-D
Large digitisation programmes currently underway at the British Library are opening up access to rich and unique historical content on an ever increasing scale. However, particularly for historical material written in non-Latin scripts, enabling enriched full-text discovery and analysis across the digitised output is still out of reach. With this in mind, we have undertaken a series of initiatives to support new research into enhancing text recognition capabilities for two major digitised collections: printed Bangla and handwritten Arabic.
The Bangla texts are drawn from our South Asian printed books collection with 1,600 digitised for the first time through the Two Centuries of Indian Print project, most of which are already available online through our catalogue. These rare and unique books, dating between 1713 and 1914, encompass a plethora of academic disciplines and genres. Unlocking these sources for both academic and non-academic audiences will be integral to expanding and enhancing knowledge of the history of print in India.
The Arabic collection comprises a combination of classic scientific literature with lesser known manuscripts illustrating scholarly activity in subjects such as medicine, mathematics, astronomy, engineering and chemistry within the Islamic world, from the 9th to the 18th century. These manuscripts have been digitised as part of the British Library/Qatar Foundation Partnership digitisation project, and are freely available on the Qatar Digital Library (QDL).
Our Bengali and Arabic materials present a diverse set of OCR/HTR challenges. These include, for example, faded text, non-straight text lines, show through and wormholes. Added to that are typographical variations between texts, inconsistent spacing between words and words which are no longer used in modern dictionaries. Other inconsistencies in text layout include non-rectangular shaped regions, and varying text column widths and font sizes.
The very nature of Bengali and Arabic scripts poses further challenges. For example, Bengali script contains complex character forms which are connected by a ‘matra’ headline, which are difficult for OCR tools to isolate and extract features to classify. In the case of Arabic, characters may take 2 to 4 shapes, most of which are joined but some are non-joining, leading to spaces within words that would make it difficult for OCR methods to correctly identify words. Complex combination of ascenders, descenders, diacritics, and special notation pose further challenges for Arabic, and the obvious challenge of being written by hand.

Bearing in mind these barriers to OCR for both collections, our approach has been to collaborate with experts in the text recognition field as well as experimenting with the latest open source recognition tools to develop a comprehensive understanding of how useful these tools are for delivering OCR that can be used for real life research situations.
Thanks to an existing relationship with the PRImA Research Lab and the Alan Turing Institute, we jointly entered competitions as part of ICDAR 2017 and ICFHR 2018, inviting providers of text recognition methods to try them out on our material. The partnership with PRImA was integral to the success of the competitions. Whilst we provided curatorial expertise and material selection, PRImA guided us in how to use their ‘ground-truthing’ tool, Aletheia, to create transcribed documents with defined regions. These ground truth sets were then be used by competition entrants to train their recognition methods.

After training their methods with the ground truth, REID2017 competition entrants were given 26 pages of Bengali without transcriptions, which were used to see how their methods would perform in a real world use case. PRImA carried out the evaluation of submitted methods: layout analysis assessed correspondences between the regions defined in the ground truth against the submitted results. A text character and word based analysis calculated the edit distance (number of insertions, deletions and substitutions) between the ground truth and the OCR result.
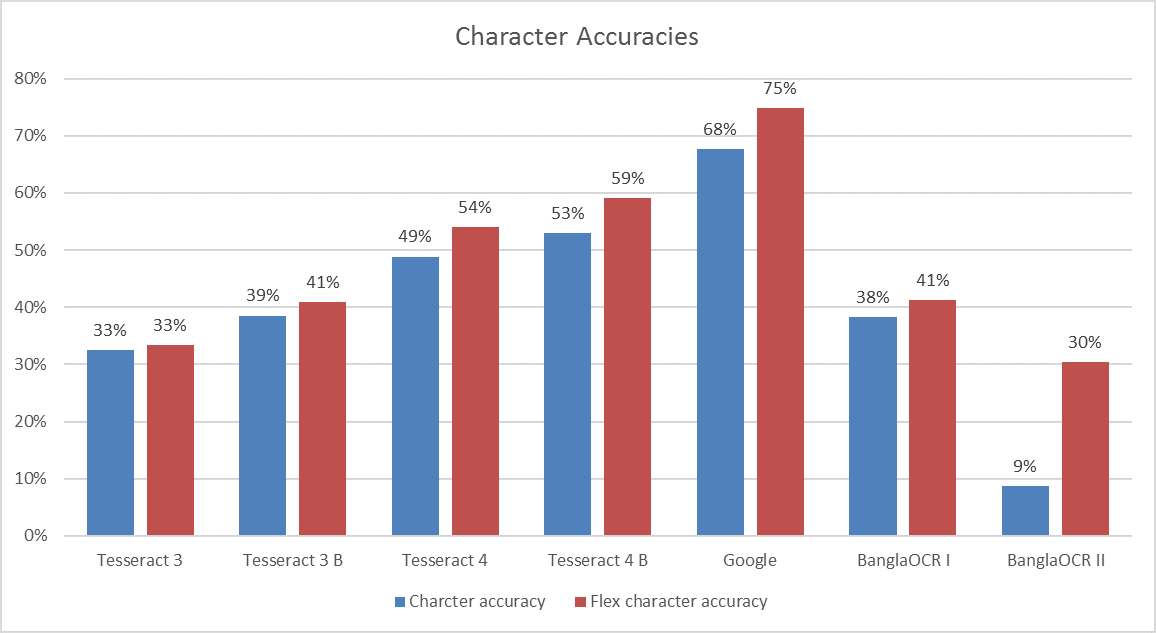
Of the submitted methods, Google’s Cloud Vision document text detection performed best with 75% (see Fig. 3) character and 50% word accuracy. Some key insights gained from the competition was the improvement in text accuracy with the latest version of Tesseract 4.0 over its previous iteration, and improved accuracy when Tesseract is used on images in binarised using ABBYY FineReader. Overall, all methods that took part in the competition could be improved with more robust binarisation, being able to handle a variety of fonts, and developing dictionaries to deal with historical spellings. Full results were published as part of the ICDAR2017 conference proceedings.
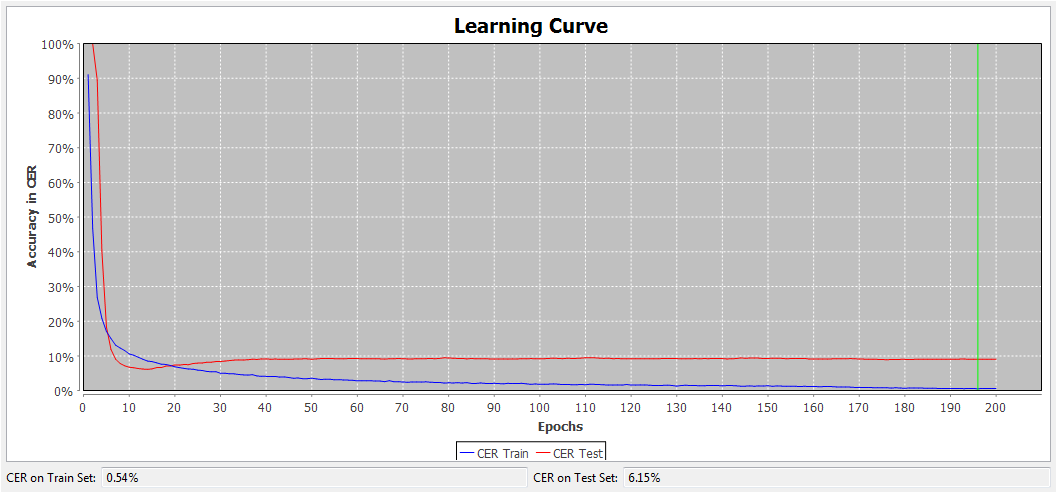
We have also been trying out other options, most notably achieving early success using Transkribus for the Bengali printed texts (see Fig. 4). Whereas the ICDAR competition was a collaborative exercise drawing on PRImA’s technical expertise, we’ve also been fortunate to have co-operative project partners at Jadavpur University who transcribed pages from the Bengali books which, when added to the competition ground truth, gave us 100 pages to train Transkribus’ HTR+ recognition engine. At 94% character accuracy, the results are the highest we have seen, although we must be careful drawing comparisons between results produced through the competition and Transkribus, with both using different ground truth and evaluation datasets.
For the Arabic RASM2018 competition we have supplied a ground truth example set of 10 pages and 85 pages as an evaluation set. Most of these were transcribed using collaborative transcription platform, From the Page. The competition set three challenges: text block detection and segmentation, text line detection and segmentation, and text recognition.
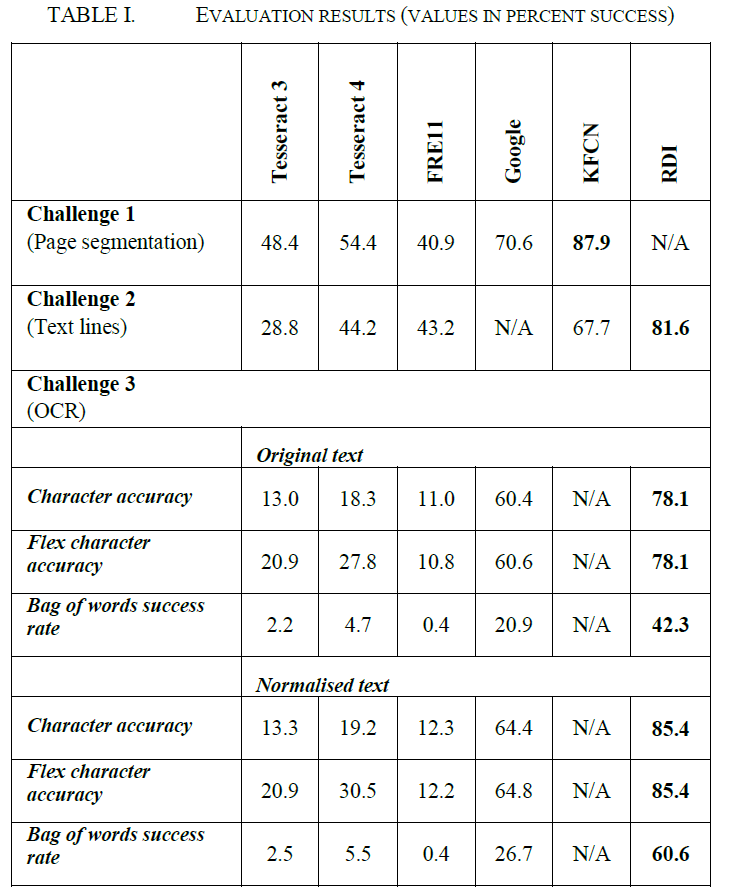
Submitted systems were evaluated on the scalability of their proposed solution as the Library’s need is for an optimal solution for automatic transcription of a vast collection. Results were promising with winners showing some exciting progress in this area (See Fig. 5). Berat Kurar Barakat (KFCN, Ben-Gurion University of the Negev) won the page layout challenge with 87.9% accuracy, and Hany Ahmed (RDI Company, Cairo University) won the text line segmentation and OCR character accuracy challenges with 81.6% and 85.44% success rates respectively. These results were published in the ICFHR 2018 conference proceedings.
Since running the REID2017 and RASM2018 competitions discussed above, we have run two ICDAR2019 competitions for Bengali and Arabic OCR/HTR, REID2019 and RASM2019 respectively, collaborating again with PRImA Research Lab. We’ve added more transcribed and ground-truthed pages to the example and evaluation sets, and added marginalia as an OCR challenge for the Arabic material. Our reports on the results of these competitions are on their way, so watch this space.
In addition, the full datasets of images and ground truth created throughout these projects will be made freely available via the British Library’s data portal, TC10/TC11 Online Resources, as well as part of the IMPACT Centre of Competence Image and Ground Truth data repository, to support and encourage further research in this ground-breaking area. We hope to build new collaborations from relationships made with other projects working in this area, and keep exploring solutions such as Transkribus and Kraken.
It is common for historical newspapers to be digitized at page level. Pages of physical newspapers are scanned and OCRed and the page images serve as the basic browsing and searching unit of the collection. Searches through the collection are made at page level and the results are shown at page level to the user. Page, however, is not any kind of basic in-formational unit of a newspaper. It is only a typographical or printing unit. Pages consist of articles or news items (and advertisements or notices of different kinds, too), although their length and form can be quite variable. Thus, the separation of the article structure of digitized newspaper pages is an important step to improve usability of digital newspaper collections. As the amount of digitized historical journalistic information grow good search, browsing and exploration tools for harvesting the information are needed, as these affect usability of the collection. Collections’ contents are one of the key useful elements of the collections, but also presentation of the contents for the user is important. The pos-sibility of being able to use article structure will also improve further analysis stages of the content, such as topic modeling or any other kind of content analysis. Several digit-ized historical newspaper collections have implemented article extraction on their pages. Some good examples are the La Stampa, British Newspaper Archive, and Trove.
The historical digital newspaper archive environment at the National Library of Finland is based on commercial docWorks software. The software is capable of article detection and extraction, but our material does not seem to behave well in the system in this respect. We have not been able to produce good article segmentation with docWorks, although such work has been accomplished e.g. in the Europeana Newspaper framework. However, we have recently produced article separation and marking on pages of one newspaper, Uusi Suometar, by using article extraction software named PIVAJ developed in the LITIS labor-atory of University of Rouen Normandy [1]. In this article we describe intended use of the extracted articles in our digital library presentation system, digi.kansalliskirjasto.fi (Di-gi), as newspaper clippings which can be collected by the user out of the markings of the article extraction software.
We have described results of article extraction using PIVAJ software in a recent article [2] at the DATeCH2019 conference. The results we achieved with our training and evaluation collection were at least decent, if not remarkable, and we believe that they provide a useful way to introduce articles for users, too. Figure 1 shows an example of PIVAJ’s graphical output. Different colors show different articles. This colored output is useful to have a quick idea of how the software behaved on given material: in production PIVAJ outputs METS and ALTO files.

PIVAJ’s current release version (2.1) is centered on articles thus, it does not extract ad-vertisements. PIVAJ’s development version investigates a totally different pipeline fully based on Deep Learning (more specifically FCN, Fully Convolutional Networks). Current page level extraction performs a semantic segmentation at the pixel level with satisfying results (around 90% accuracy) on the Luxembourg National Library ML Starter pack dataset and Gallica’s Europeana Newspapers dataset . An example graphical result of the development version’s output is shown in Figure 2.

Users of our digital presentation system Digi have been able to mark and collect so called clippings for several years [4]. This function has been quite popular and many users have collected hundreds and even thousands of clippings for their own collections on their user accounts. The clippings can also be seen by other users. Researchers have used the clipping function to collect their data as well. So far the function has been totally manual: the user has marked on the pdf representation of the page the textual area they are interested in and the image of the clipping has been stored with bibliographical information. The user can also add keywords, topic and title to the clipping. So far there has been no possibility of storing the OCRed text of the clipping, only an image file [4].
The procedure of creating articles automatically for the user utilizes the existing clip-ping functionality of Digi. PIVAJ uses the defined newspaper models of Uusi Suometar, and it provides as XML file as its output which contains the coordinates of the article regions for each recognized article on a page. In Digi’s context these are the different parts of the clipping that are created in the order of the creation. After the regions have been entered to the presentation system, they are shown as individual clippings on the page.
Figure 3 illustrates the overall work flow of clipping production.
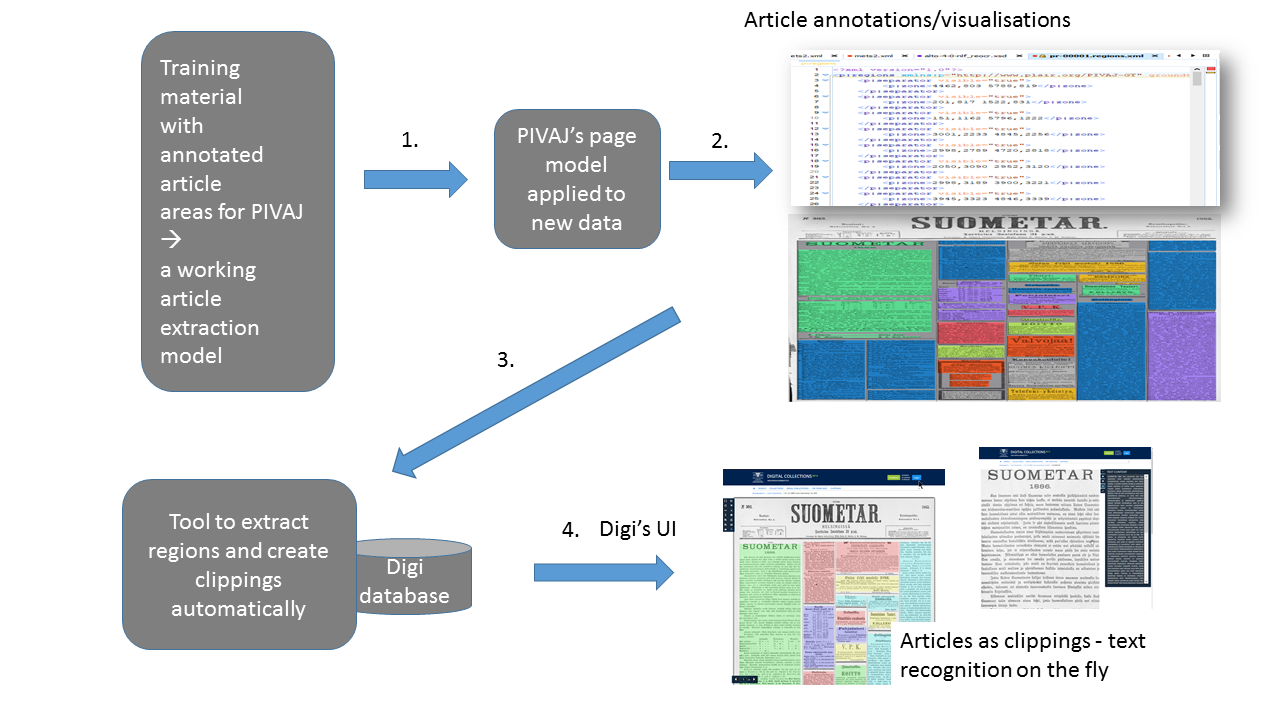
After choosing the article from the automatic pre-selection of PIVAJ, the user can store the article in his/her collection. The user is also able to store the OCRed text along the clipping. This functionality is shown in Figure 4. The left part of the figure shows the clipping as an image, the right part shows the textual content.
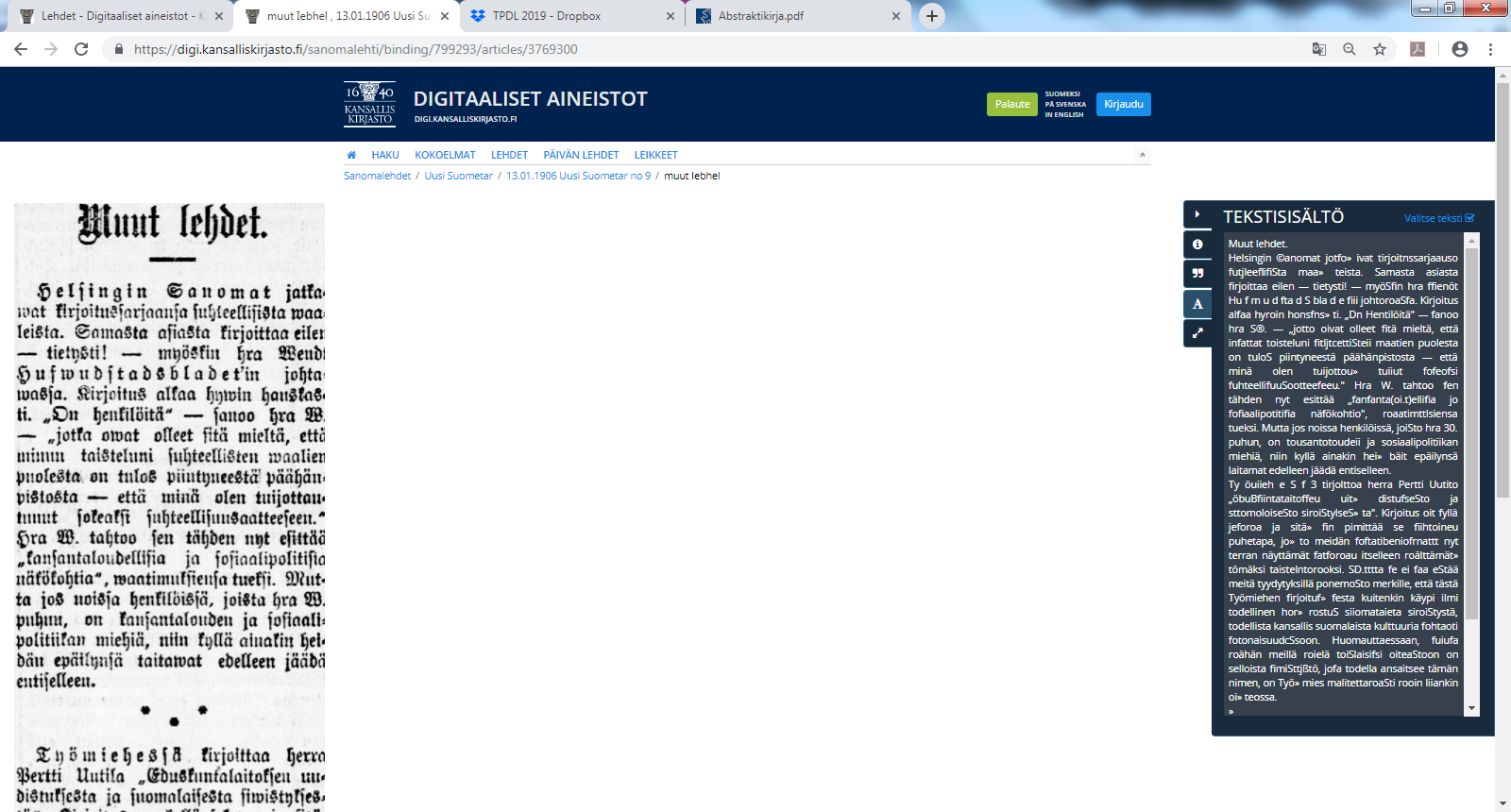
The new functionality will appear in our presentation system during the year 2019 with the data of Uusi Suometar 1869-1918. This newspaper is one of the most used in our col-lection and consists of 86 068 pages.
This paper has described utilization of automatic article extraction on one historical Finn-ish newspaper, Uusi Suometar, in the journalistic collection of The National Library of Finland. The new functionality of the digital presentation system has been implemented by using an article detection and extraction tool PIVAJ and a clipping functionality al-ready available in the user interface of our presentation system. The user can collect auto-matically marked articles for his/her own use both as images and OCRed text. We believe that the functionality will be useful for different types of users, both researchers and lay persons who use our collections.


The work at the NLF is funded by the European Regional Development Fund and the pro-gram Leverage from the EU 2014-2020.
1. D. Hebert, T. Palfray, T. Nicolas, P. Tranouez, T. Paquet (2014). PIVAJ: displaying and augmenting digitized newspapers on the Web Experimental feedback from the “Jour-nal de Rouen” Collection. In Proceeding DATeCH '14 Proceedings of the First Interna-tional Conference on Digital Access to Textual Cultural Heritage, 173–178. http://dl.acm.org/citation.cfm...
2. K. Kettunen, T. Ruokolainen, E. Liukkonen, P. Tranouez, D. Antelme, T. Paquet (2019). Detecting Articles in a Digitized Finnish Historical Newspaper Collection 1771–1929: Early Results Using the PIVAJ Software. DATeCH 2019.
3. C. Clausner, S. Pletshacher, A. Antonacopoulos (2011). Scenario Driven In-Depth Per-formance Evaluation of Document Layout Analysis Methods. 2011 International Conference on Document Analysis and Recognition (ICDAR). DOI: 10.1109/ICDAR.2011.282
4. T. Pääkkönen (2015). Crowdsourcing metrics of digital collections. Liber Quarterly, https://www.liberquarterly.eu/...