Issue 10: Innovation Agenda
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community.
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community.
It’s no surprise that innovation and EuropeanaTech go hand-in-hand. It’s been apparent over the past 10 years of Europeana’s existence that those making great leaps in technical innovation within cultural heritage are part of the EuropeanaTech community. At each of our conferences (2011, 2015, 2018) we have seen these advancements first hand and clearly noticed how heritage and research institutions have reaped the benefits of our collective knowledge.
But where are we going next? That was certainly the question during EuropeanaTech 2018. With its wide-ranging expertise, impressive geographic breadth and connectiveness, the EuropeanaTech community is in the perfect position to champion the growth and progress of the cultural heritage sector but some form of steering and overview of core focus areas are necessary.
Aware of this in 2017, the Europeana Foundation Governing Board assigned a Task Force to develop an agenda and implementation plan that can position the innovation of the cultural heritage sector as a priority within European cultural policies and research and innovation programmes. This resulted in the newly published Europeana Innovation Agenda a report that identifies thirteen topics that constitute the most urgent challenges and opportunities across the European cultural landscape. The Agenda highlights that while there is a strong feeling of urgency in the sector to keep up with the fast-paced digital transformation, innovation cannot be limited to technological demands within the cultural heritage institutions. Broader societal and economic challenges also require immediate and concerted actions. Participants at EuropeanaTech 2018 were asked to provide their insights as was the the Network Assocation at large via an online survey. If you're curious about these inputs you can read them all here.
EuropeanaTech is one of the communities of focus in this report, as it continues to innovate not just technically but structurally, socially, economically and educationally and with this edition of EuropeanaTech Insight, we’ve selected several presentations from the EuropeanaTech 2018 conference that we felt fell within the ethos of these thirteen topics. We then invited these presenters to share an overview, update and insights on their work.
We’re just scratching the surface of the abundance of work being done by the EuropeanaTech community but even these few bits and pieces illustrate what a bright future there is for digital cultural heritage.
Even though the creation of digital heritage collections began with the acquisition in image mode, several decades later to search in the content of some of these images still belongs to a more or less distant future. This apparent paradox originates in two facts: digital libraries (DLs) first focused on applying OCR to their printed materials, which renders major services in terms of information retrieval; Searching in large collections of images remains a challenge, despite the efforts of both the scientific community and GAFAs to address the underlying challenges [1]. However, the needs are very real, if one believes user surveys [2] or statistical studies of user behavior. But DLs iconographic collections are generally inadequate, given the broad spectrum of areas of knowledge and time periods surveyed by users. However, DLs are rich in many other iconographic sources. But organized in data silos that are not interoperable, most often lacking the descriptors required for image search, and exposed through text-oriented GIs. While the querying of iconographic content poses specific challenges [3], answers to various use cases, targets different knowledge domains, and finally calls for specific human-machine interactions [4], [5]. This work presents a proposal for a pragmatic solution to these two challenges, the creation of an encyclopedic heritage image database (which has never been done in DLs, to our knowledge, even if the Bayerische Staatsbibliothek offers an image-based similarity search) and its querying modalities.
First, before we look in the images, we must find out where they are located, i.e. we have to data mine the digital repositories. Besides, a multicollection approach requires to take into account the variability of the data available, due both to the nature of the documentary silos and to the history of the digitization policies. Our database aggregates 600k illustrations of theGallica collections of images and prints related to the First World War. The data extracted from 475k pages thanks to the Gallica APIs and to SRU, OAI-PMH and IIIF protocols are stored in a XML database (basex.org). The images collection presents particulars challenges: MD suffering from incompleteness and inconsistency; missing MD at image level like genre (picture, engraving, drawing) or color mode; portfolios exposing specific difficulties: cover and blank or text pages must be excluded, multi-illustrations pages cropped, captions extracted.
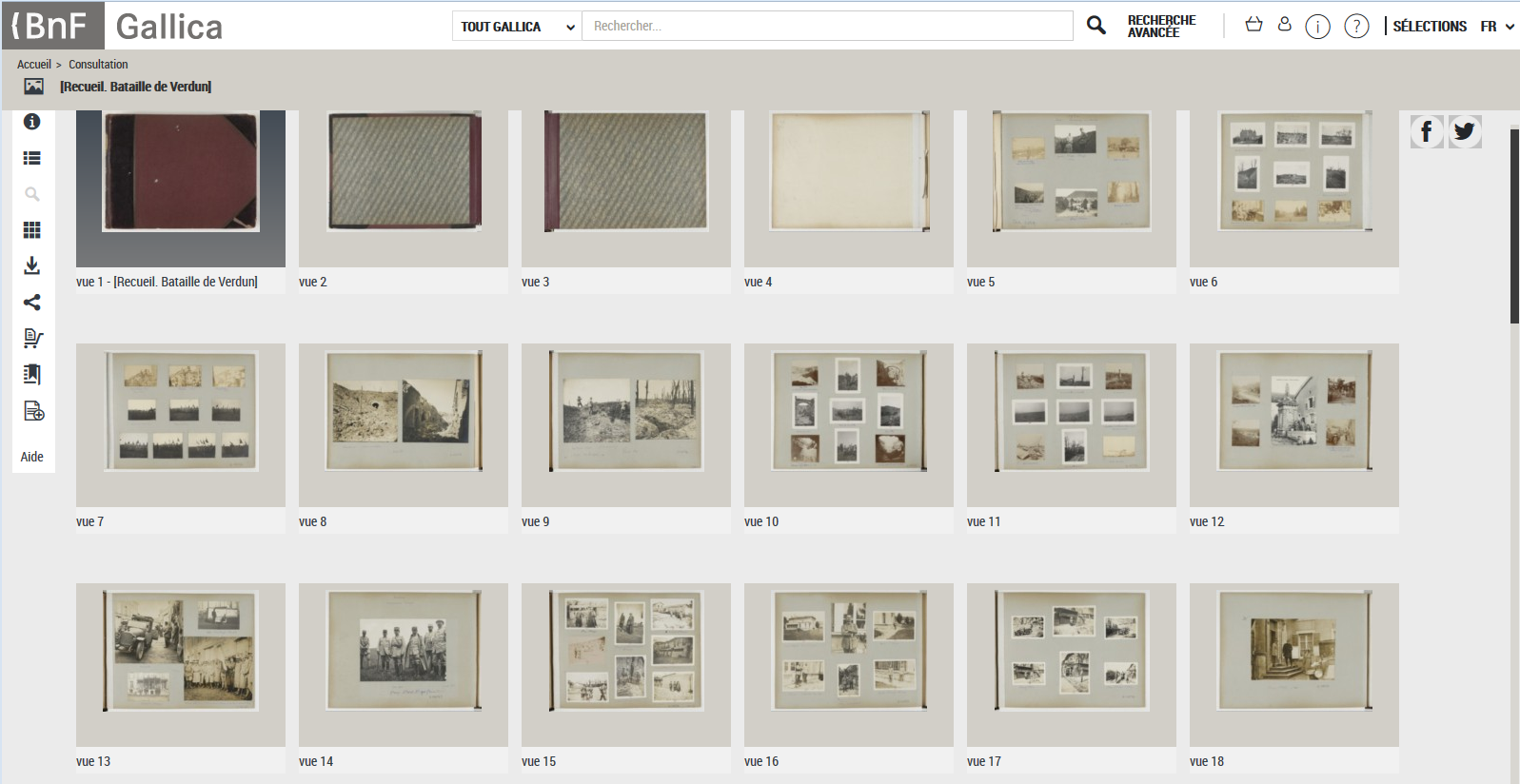
Figure 1 : Example of portfolio (https://gallica.bnf.fr/ark:/12..., many of illustrations, one bibliographical record)
For printed collections, we can leverage the OCR resources to identify illustrations a well as the text surrounding them. In the case of the daily press, the illustrations are characterized by a wide variety of genres (from maps to comic strips) and a large volume.

Figure 2 : OCR can identify illustrations in printed materials
On the 600k raw illustrations extracted, we now must filter the noisy ones, particularly the false detected illustrations from OCR of printed documents but also the blank pages and covers of portfolios. The images collection presents a low noise rate (≈5%) but it affects the quality perceived by users. For newspapers, noise varies from 10% (operator-controlled OCR) to 80% (raw OCR). Using MD and heuristics (illustration size and position, width/height ratio), this noise can be reduced.

Figure 3: Illustrations data mining on raw OCR newspapers outputs a lot of noise…
It is important to note that this first step alone (the whole process is schematized below) is worth it: even without semantic indexing of image content, it gives dedicated access to those valuable resources
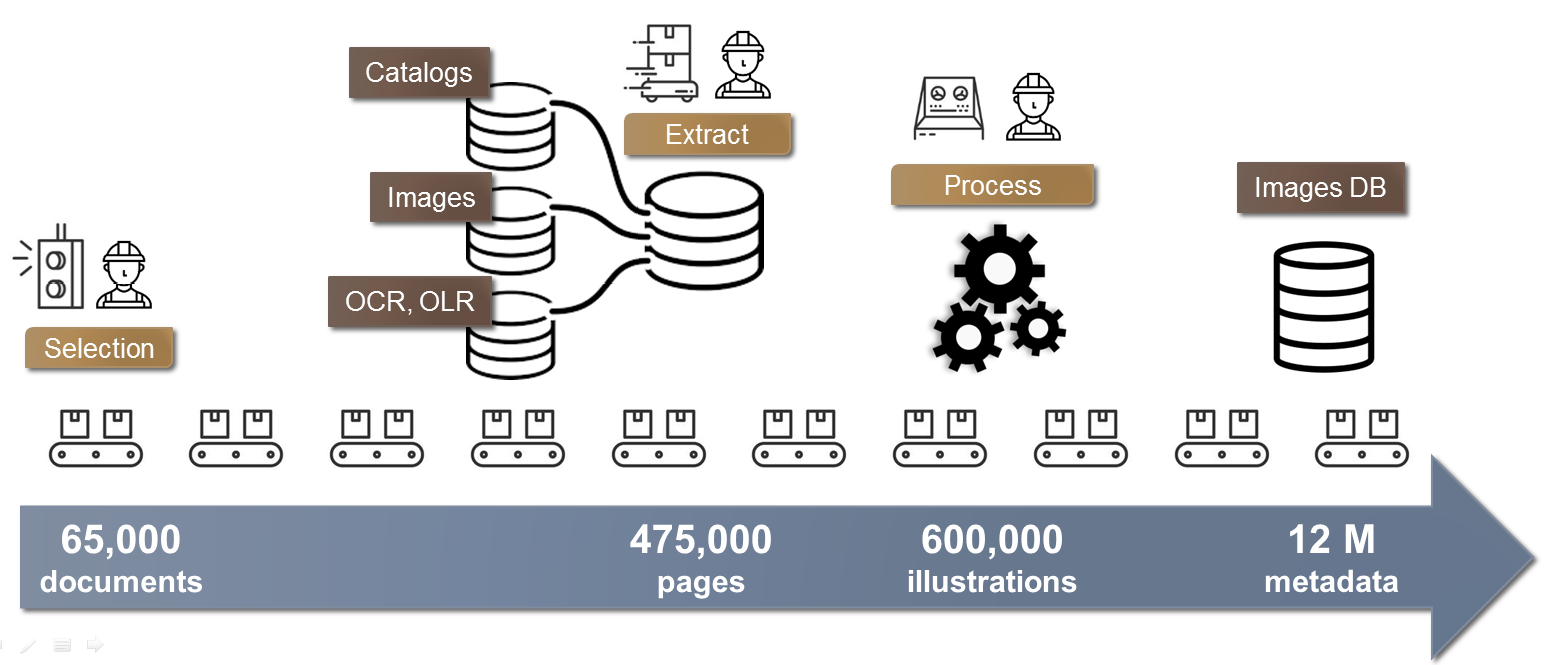
Figure 4: The extraction worflow
The next step consists of transforming, enriching and aligning the MD obtained during the previous step. First, illustrations without any text descriptor are filtered and their enlarged bounding box is processed with Google Cloud Vision OCR. Attempts are also made to link the illustrations to the BnF Linked Data service, data.bnf.fr.
The illustration genres are not always characterized in the catalogs (and obviously, this MD is not available for printed materials). To overcome this lack, a deep learning approach for image genres classification is implemented. We retrained the last layer of a convolutional neural network model (CNN, here Inception-v3 [6]), following a “transfer learning” method [7]. Our model has been trained on a twelve “heritage” genres ground truth (GT) of 12k illustrations produced first by bootstrapping from catalog MD and then by manual selection.

Figure 5 : The twelve categories of the training dataset
Once trained, the model is evaluated: accuracy and recall are 90%. These results are considered to be good regarding the diversity of the training dataset (see [8] for results on a similar scenario), and performances are better with less generic models (separately trained on the images collection, recall rises up to 95%). Most confusions occur between engraving/photo, line-based content (drawing, map, text) and illustrated ads, common in serials (in the newspapers set, ≈30% of the illustrations are ads), which must be recognized to be filtered or used for scientific aims [9]. But the neural network outputs poor results because these ads can be of any graphical genre (advertisement is a type of communication, not a graphical form). A mixed approach (text+image) should preferably be used. This model is also used to filter the unwanted illustrations that have been missed by the previous heuristic filtering step (§1), thanks to 4 noise classes (text, ornament, blank and cover pages). Recall/precision for these noise classes are highly dependent of the difficulty of the task: 98% for the images collection, 85% for the newspapers. Using neural networks for illustration genres classification brings to light interesting phenomena. Thus, their ability to generalize is expressed e.g. in hybrid documents, both cartographic and illustrative, a variation that wasn’t present in the “maps” learning corpus.

Figure 6: Documents classified as “map”
Due to the wide documentary coverage of the collection, even over a short period of time, documentary genres that were not foreseen in the training base may appear. Consequently, a new training class must be build and the whole model needs to be retrained.

Figure 7: The new “charts” class: technical drawing, stock exchange charts…
IBM Visual Recognition and Google Cloud Vision APIs have been used to analyze the illustrations and extract “concepts” [10] (objects, persons, colors, etc.). An evaluation is carried out on Person detection. A 4k GT is created and another evaluation is conducted on the “soldier” concept.

Figure 8: Samples of results for Person recognition
The “person” concept has a modest recall of 55% but benefits from excellent accuracy of 98%. A decrease is observed for the more specialized “soldier” class (R=50%; A=80%). However, these results are to be compared with the relative silence of keyword searches: “soldier” does not exist as a concept in the bibliographic metadata and it would be necessary to write a complex keyword query like “soldier OR military officer OR gunner OR…” to obtain a 21% recall, to be compared to the 50% obtained by using the visual MD only and the 70% in the hybrid scenario (visual+text descriptors), which shows the obvious interest in offering users cross-modal search [11].
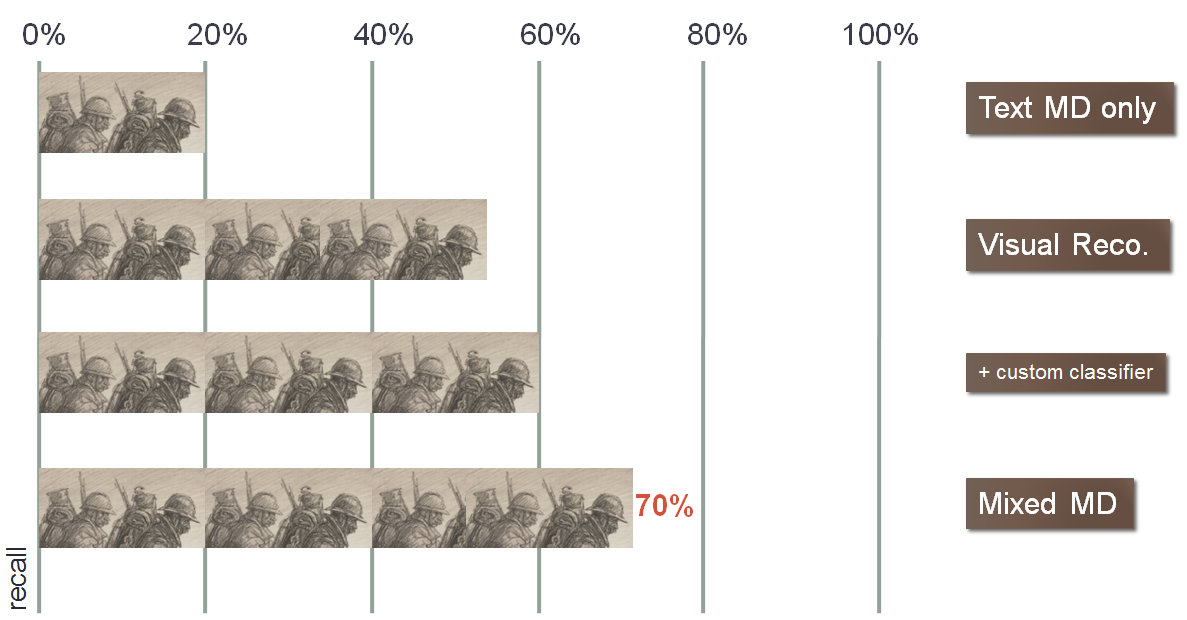
Figure 9: Soldier detection: recall for the different search modalities
Negative effects of deep learning sometimes occur: generalization may produce anachronisms (a 1930 motorized scooter is classified as a Segway); complex or under-segmented documents are indexed with useless generic classes (we have to keep in mind that machine learning techniques remain dependent on the modalities over which the training corpus has been created).

Figure 10: Classification (from left to right): “frame”, “printed document”, “newspaper”
The Watson API also performs face detection (R=43%/A=99.9%). On the same GT, a basic ResNet network gives a recall of 58% if one compromises on accuracy (92%): deep learning frameworks offers more flexibility than APIs

Figure 11: Face detection results on engravings and drawings (OpenCV, ResNet model, “Single Shot Multibox Detector” method)
The enrichment indexing pipeline turns out to be complex to design and to implement. It takes into account the fact that certain genres do not need visual indexation (maps); that both text and image can be source of indexing; that this indexation may help to “unfilter” illustrations; that it may be replayed on a regular basis (using different APIs or in-house models); that new kind of content may require to retrain the model(s) and/or redesign the workflow.
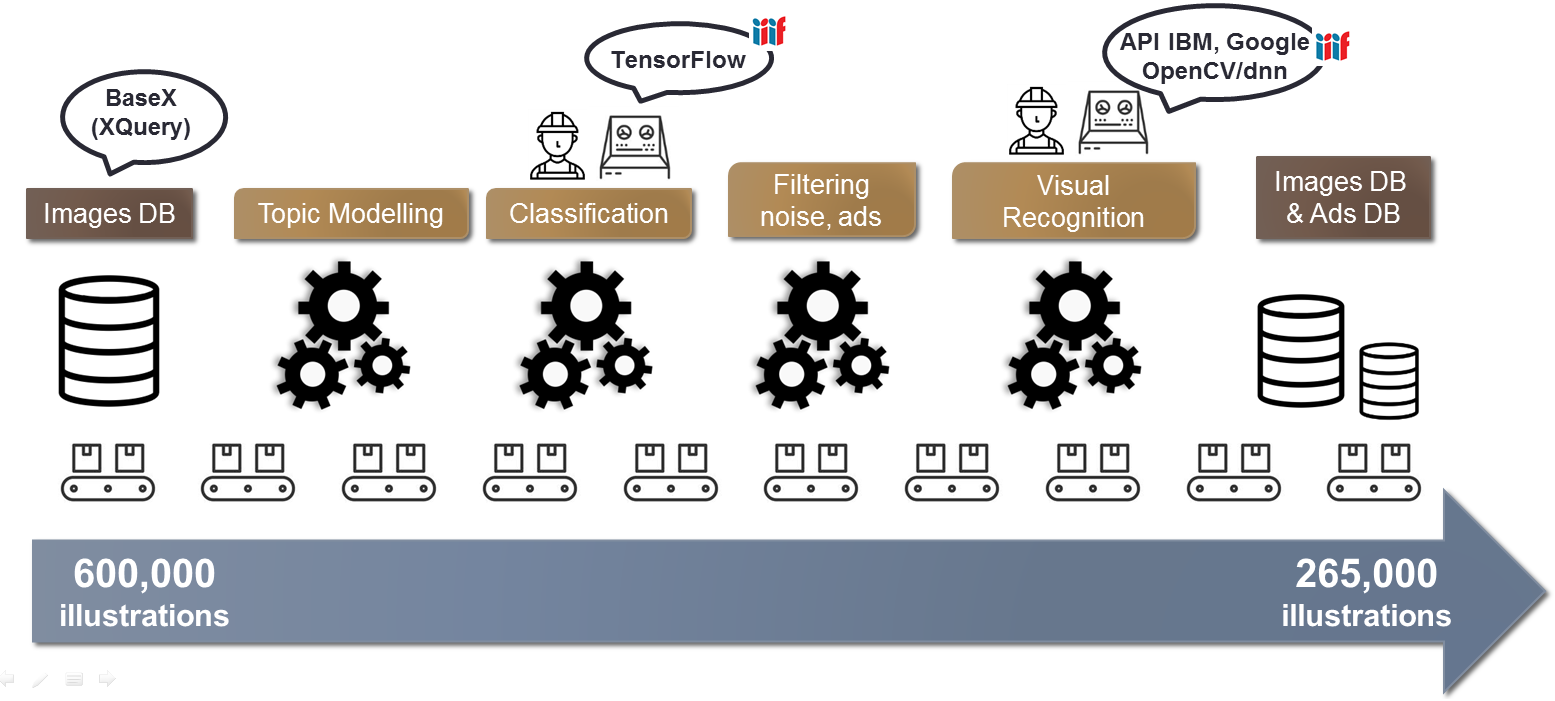
Figure 12: The enrichment worflow
The BaseX database is requested through REST queries. An images mosaic is fed on the fly by the Gallica IIIF server. A rudimentary faceted browsing functionality prefigures what a more ambitious user/system interaction could be2. Encyclopedic queries leverage the textual descriptors (metadata and OCR). While a “Georges Clemenceau” query in Gallica images collection only returns 140 results, the same query gives more than 900 illustrations with a broader spectrum of genres. The “drawing” facet (thanks to the neural network classification) can then be applied to find Clemenceau caricatures in dailies.

Figure 13: Caricatures of George Clemenceau: keyword search + genre classification
The conceptual classes extracted by the visual indexing overcome the silence related to the textual descriptors but also circumvent the difficulties associated with multilingual corpora, the lexical evolution or the fact that keyword-based retrieval can generate some noise. E.g, a query on “airplane” will output a lot of noise (aerial pictures, aviator portraits, etc.) whereas the “airplane” concept will do the job.

Figure 14: Querying on “airplane” concept
Again, applying the “person” facet will help to quickly find aviators near their machine.

Figure 15: Querying on “airplane” + “person” concepts
Finally, the joint use of metadata and conceptual classes allows the formulation of cross-modal (or hybrid) queries: searching for visuals relating to the urban destruction following the battle of Verdun can rely on classes “street” or “ruin” and “Verdun” keyword.

Figure 16: Cross-modal query
The PoC source code and the database1 are available for the academic and digital humanities communities, which investigates more and more heritage contents for visual studies [12]. Moving towards sustainability for the illustrations MD would benefit to their reuse by information systems (like catalogs) as well as by in-house applications or end users. It should be noted that the development of this demonstrator was made possible by the availability of APIs, and in particular IIIF. Besides, the IIIF Presentation API provides an elegant way to describe those illustrations in a near future, using a W3C Open Annotation attached to Canvas in the IIIF manifest. All iconographic resources can then be operated by machine, for GLAM-specific projects, data harvesting and aggregation [13] or to the benefit of hacker/makers and social networks users. Nevertheless, the status and the management of these “new” metadata are still open questions: They are computer-generated (while catalog records are human creation) and susceptible to regular replay (AI is evolving at a frenetic pace); They can be massive (one catalog record for a newspaper title/millions of atomic data for its illustrations dataset); An interoperability standard for expressing them is missing (e.g. IBM and Google use different classification taxonomies). At the same time, the maturity of modern AI techniques in image processing encourages their integration into the standard DLs toolbox. Their results, even imperfect, help to make visible and searchable large quantities of illustrations. But the industrialization of an enrichment workflow will have to cope with various challenges, mainly related to the diversity of the digital collections: neither illustration detection in documents nor deep learning for classification can generalize well on such a large spectrum of materials. Anyway, we can imagine that the conjunction of this abundance and a favorable technical context will open a new field of investigation for digital humanist researchers in the short term and will offer image retrieval services for all categories of users.
References
A growing body of open source software (OSS) supports cultural and scientific heritage organizations, and while some initiatives have been successful at creating sustainable programs, others have struggled to determine what strategies will work once grant funding ends or other major pivots are required.
In 2017, to deepen the cultural and scientific heritage field’s understanding of sustainability and encourage OSS programs to share and learn from each other, LYRASIS convened a national meeting of OSS stakeholders with support from the Institute of Museum and Library Services (IMLS). The “It Takes a Village: Open Source Software Sustainability Models” forum was held on October 4-5, 2017. The goal of the project and forum was to develop a guidebook for new and existing OSS initiatives to strengthen planning, promotion, and assessment of sustainability.
Working with an advisory group, ITAV project co-directors Laurie Gemmill Arp, LYRASIS Director of Collections Services and Community Supported Software, and Megan Forbes, CollectionSpace Program Manager, invited individuals representing 27 OSS initiatives to the forum for a total of 49 participants. Diverse perspectives were sought by including a mix of program, governance, community (users), and technical leaders.
The ITAV team assumed that while there is no single approach to sustainability, there may be common threads among programs that would lead to mutual needs and strategies for meeting those needs.
Prior to the forum, background information was collected from the invited OSS programs to provide context for discussions. Information was collected in such areas as mission and purpose of the OSS, date of first and most recent releases, size and make-up of the user community, size of the development community, development management processes, governance structure, and current sources of financial support. In addition to providing a means for sharing information among participants, the background survey responses inspired directions and themes for the forum discussions.
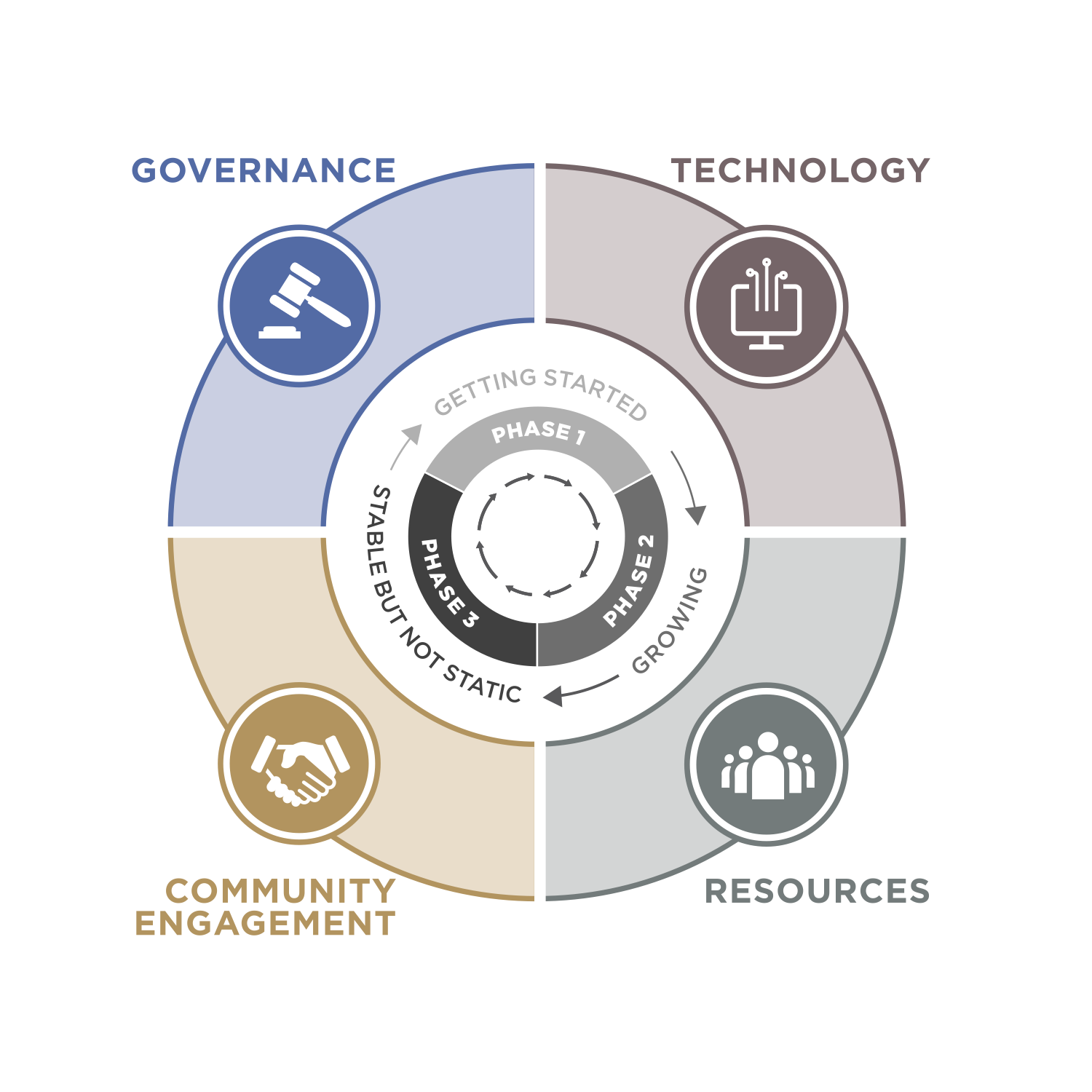
The results of the forum and survey were combined with other resources and shaped into a Sustainability Guidebook published in February 2018. Freely available via a CC license, the Guidebook creates a framework for evaluating sustainability using a combination of lifecycle phases and sustainability facets. The lifecycle phases, which are repeated for and revolve around each facet, include: Getting Started; Growing; and Stable, but not Static. There are many elements that go into OSS sustainability, but during discussions, most participants coalesced around four main facets: Governance, Technology, Resources, and Community Engagement. For each phase in each facet, the Guidebook identifies goals, characteristics and common roadblocks; provides guidance for moving programs to the next phase; and highlights case studies and additional resources to help programs.
The effects of the project and framework can be seen in short, intermediate, and long-term impacts. We were gratified to see short term impact immediately. One of the benefits of the project was bringing together people representing different programs and perspectives for sharing, networking, and potential collaborations. Many of the forum participants found meeting others at different phases in their programs extremely valuable. Some participants already knew each other but appreciated the opportunity to focus on OSS sustainability in a concentrated way without the distractions or conflicting priorities of a larger conference. 100% of forum participants indicated that discussions at the forum would be considered in their program’s plans for the future. Specific feedback included:
The intermediate and long-term impact comes from the framework itself. By providing tools for programs to identify the current lifecycle phase of each facet of their work and then focus on the details of specific facets, programs will be better able to identify strategies for moving forward, perform self-evaluations of sustainability, and establish connections within and outside of their community to enable resource sharing and collaboration.
We have had feedback from many project participants that they are sharing the Guidebook with their communities and finding it valuable:
The beginnings of the long-term impact are already visible in the eight months since the Guidebook was published. During that time, multiple programs that did not participate in the forum have approached us about the framework and how to implement it with their programs. The team has worked to identify additional needs within the field for processes and tools that can be adapted to support a programs ongoing and continuous focus on sustainability.
Another long-term impact will be seen outside the realm of OSS. While created to evaluate OSS programs, it has become clear through discussions and presentations that the model can be used as a more general sustainability evaluation tool. All programs and projects have sustainability needs; all need to make decisions about their future around governance, community engagement, and human, financial, and technology resources. The ITAV model has proven applicable and useful for strategizing and framing discussions around other (non-OSS) collaborative initiatives led by LYRASIS, such as the ORCID US Community. The framework could also be beneficial for granting agencies, both in the evaluation of program sustainability plans and as a planning resource for grantees.
The project and resulting Guidebook were intended to serve as a practical source to help OSS programs serving cultural and scientific heritage organizations plan for long term sustainability, ensuring that commitment and resources will be available at levels sufficient for the software to remain viable and effective for as long as it is needed. We have been gratified to hear that it is serving those needs and beyond.
The Guidebook, along with more information about advisory group members and participating programs, is available at www.lyrasis.org/itav
Wikipedia, the free encyclopedia, has been around since 2001 as the only non profit in the top 10 of most visited websites in the world. For many, it is a first stop to find information online. Less people know that Wikipedia is part of a larger ecosystem of over a dozen interoperable Wikimedia projects, including Wiktionary (a free dictionary), Wikivoyage (a free travel guide), Wikisource (a platform for digitized source materials), and the underlying open source wiki software MediaWiki. All these projects share a common vision: Imagine a world in which every single human being can freely share in the sum of all knowledge.
Figure 1: The ecosystem of Wikimedia projects. CC BY-SA 3.0 Unported, via Wikimedia Commons
Wikimedia projects are community- and volunteer-driven, they are non-profit (funded by small donations from individual donors around the world and free of advertisements), they are editable by anyone, and they collect and distribute information that may be freely re-used, also for commercial purposes.
From the perspective of cultural heritage, Wikimedia Commons and Wikidata are probably among the most impactful Wikimedia platforms. Wikimedia Commons was launched in 2004 and serves as Wikimedia's repository of media files. These more than 50 million files - mainly images, but also an increasing number of videos, audio files, digitized publications and 3D files - illustrate Wikipedia articles and other Wikimedia projects, and are re-used by many external platforms and applications.
Figure 2: A small selection of media files on Wikimedia Commons, uploaded as part of Europeana Fashion.
Wikidata, Wikimedia's youngest sister project, was founded in 2012 and provides a generalized knowledge base of free, multilingual linked and structured data that is integrated in platforms as diverse as Wikimedia itself, OpenStreetMap, Mac iOS, VIAF, and many more.

Figure 3: VIAF, the Virtual International Authority File's entry on French art historian and curator Françoise Cachin, with links to external databases, including Wikidata.
Since the mid-2000s, heritage institutions around the world have worked together with Wikimedia communities to share their knowledge and collections. Such GLAM-Wiki collaborations are inspired by the very closely aligned missions of the Wikimedia movement and cultural institutions: both want to share knowledge about our common culture and history as broadly as possible. Wikimedia projects allow cultural institutions to reach very broad audiences, to be present where people actually look for information, and to host digital representations of their collections on platforms that are commons-based and have proven to be quite persistent. But most importantly, Wikimedia projects engage heritage collections with very active, passionate communities of culture-loving volunteers who provide a lot of added value and give new life to heritage in the broadest sense. Over the years, many cultural institutions have developed GLAM-Wiki projects with Wikimedia communities on Wikipedia, have made their digitized collections available via Wikimedia Commons and used Wikidata to support their own Linked Open Data projects.
Like numerous other organizations, Europeana actively engages with Wikimedia and has embedded these activities in its organization through a dedicated staff member (generally called a 'Wikimedian in Residence'). Liam Wyatt, Europeana's Wikimedia coordinator, has initiated and mentored diverse active collaborations between Europeana and the Wikimedia communities, including campaigns and collaborations around Europeana Fashion, World War I, the Europeana Art History Challenge, and its migration vocabulary.
Short video explaining the Europeana Art History Challenge (2016) held on Wikidata and other Wikimedia projects. CC BY-SA 4.0, via Wikimedia Commons
In the past years, the cultural sector has been increasingly dedicating efforts to Linked Open Data. It is a recurring theme in many collaboration projects and at conferences, including EuropeanaTech 2018. Public data providers now take concrete steps to build bridges between silos of digital data, and the heritage sector increasingly dedicates itself to building the integrated library, archive, and museum of humanity together. Publicly funded aggregation platforms like Europeana and civil society initiatives like the Wikimedia movement play a pivotal role here as mutually reinforcing data hubs. In this landscape, Wikidata offers a generic, multilingual and networked knowledge base. It interlinks vocabularies that are widely used in the heritage sector. Concepts on Wikidata (people, places, subjects…) are extensively mapped to widely used databases like VIAF, to authorities managed by national libraries and the heritage sector at large, to the Getty Institute's heritage vocabularies and, interestingly, also to more informal online knowledge platforms such as Quora and MusicBrainz. This makes Wikidata a powerful tool for disambiguation of concepts and as connective tissue for the Linked Open Data web. Europeana recommends its data providers to link to Wikidata as well; mapping institutions' vocabularies with Wikidata makes correct integration of their data in Europeana easier.

Figure 4: A small selection of musical instruments on Wikidata, shown in Spanish, linked to the Hornbostel-Sachs classification and MIMO vocabulary for musical instruments. Link to query
In 2017-19, Wikimedia Commons will be converted to structured data. Until present, files on Commons were only described in plain text (Wikitext), but starting from early 2019, Wikimedia Commons will be enhanced with metadata from Wikidata. This integration opens many perspectives for supporting cultural heritage institutions and aggregators like Europeana.
Figure 5: Design mockup of structured data from Wikidata integrated in Wikimedia Commons, November 2018. Pam Drouin (WMF), CC BY-SA 3.0, via Wikimedia Commons.
Firstly, structured data makes the media files on Wikimedia Commons fully machine-readable and 'linked', so that they become morebetter discoverable and re-usable, also in complex external applications and in search engines. Importantly, integration with Wikidata also brings advanced multilinguality to Wikimedia Commons. Each concept ('item') on Wikidata has 'labels' in many languages; the Wikimedia volunteer communities proactively translate these labels. By tagging media files with these multilingual concepts, they become discoverable in many more languages than was possible with the originally provided metadata.
Figure 5: A selection of artworks included in the Europeana Art History Challenge, with Wikidata descriptions and titles shown in Swedish. Screenshot from Crotos, an artwork visualisation tool developed by Wikimedia volunteer Benoît Deshayes.
Through improved and refined APIs and metadata mappings, such translations - and other crowdsourced enhancements and improvements by Wikimedia communities - can now also more easily be sent back to the data provider. The Swedish National Heritage Board (Riksantikvarieämbetet / RAÄ), one of the national aggregators for Europeana, is workingworks on a prototype for this functionality. Until December 21, 2018, RAÄ hasholds a survey to investigate how cultural institutions like to receive translated and enhanced metadata from Commons, and which data they are most interested in. Please participate in this survey!
Further Reading
Stinson, Alexander D., Sandra Fauconnier, and Liam Wyatt. “Stepping Beyond Libraries: The Changing Orientation in Global GLAM-Wiki.” JLIS.It 9, no. 3 (September 15, 2018): 16–34. https://doi.org/10.4403/jlis.it-12480.
Kitodo is an open source software suite to support the digitisation of cultural assets for Libraries, Archives, Museums and Documentation centers of all sizes. The Kitodo software covers a broad range of aspects in the digitisation process - from the production of scans and metadata to a flexible presentation on the web.

In the workflow tool ‘Kitodo.Production’ you will define a project in general - connected with the setup of a workflow with an individual list of workflow steps according to your Institutional needs. In the user administration area, every user will be connected with their specific projects and task in the workflow. A workflow management and role concept helps you to manage many projects simultaneously.
The core of Kitodo.Production is the highly configurable metadata editor. With this tool, we assign libraries the appropriate structure types to the different parts of a book – for example, Title page, Table of contents and chapters/articles with important metadata e.g. a Title. The job in the environment of Kitodo. Production is completed with the export of METS/MODS files.
Kitodo.Production is programmed as a web application in Java and can be used as a conventional web application.
Kitodo. Presentation is built as an extension in TYPO3 combined with a solr Index. The plugin concept for typical elements like hitlist, table of contents, metadata listing leads to an easy integration in the general website template of your institution. It’s comfortable to manage all configuration tasks in/by a graphical user interface. Finally it’s quite easy to provide other portals by the integrated OAI interface with METS files.
The Vision for our open source community - based on a management perspective and our IT-strategy:
We see digitisation as a task on the agenda in our institutions, that will run for long time.
We want to build knowledge within our institution – to anticipate and solve issues on our own.
We want to learn together and support each other. We need sustainable infrastructure – realised within a realistic budget over the years. We would manage the whole digitisation process ourselves and would like to avoid any vendor lock-in. Software is developed along the needs of our community.
We see a variety of IT-topics in all institutions – and the small IT-teams to address them. From the beginning we had an explicit goal, to attract and integrate service providers to our Kitodo community.
On our way to integrating service providers we lost one of our providers, – we didn’t arrive at a common understanding regarding the planning of the software development. Today we have two companies that have joined the Kitodo community with a strong commitment to open source principles, and to contribute in support and software development.
Smaller institutions will be able to build a stable digitisation infrastructure with open source tools – with different support levels from full service including hosting to restricted support budgets. At best, all of our activities in the Kitodo community lead to a mixture of independence and support – may be starting with support in installation issues as leading to increasing independence.
The “Goobi”-Project – the parent version of Kitodo.Production - started in 2004 as a third party funding project at the Göttingen State and University Library. Other libraries involved in a growing number of digitisation projects adopted this open source approach, Collaborations were started around some common issues and the association was founded in 2012 to organize software development and to enhance the network of experienced professionals.
The association board consists of 5 members – elected every two years in the general meeting. We ask the companies to suggest of their team members to join our board.
Since 2017 the library of the Technical University in Berlin dedicated a member of staff part time with the responsibly of a Kitodo association office. Our colleague takes care of important tasks such as coordination of general Kitodo requests, Website Care and supporting the board as well as managing special projects e.g. workshops.

We prefer a Release Management independently from a company. Release Management – paid by the association and appointed to an institution every two years at the general meeting. And the core statement in our developer guidelines is "All development projects should be publicly documented and must be communicated to a release manager.“
In addition to typical mailing within our association board we brainstormed how best to support institutions who have decided to adopt Kitodo and have enough IT-Staff to get started on their own. The Kitodo association office has a list of experienced and committed institutions to get in contact and receive technical advice and where possible on-site practical assistance.
Furthermore we regularly offer a detailed technical introduction, this is a 2 day workshop called "Kitodo for newbies“. The targeted audience are System Administrators and System Librarians.
"Kitodo-Exchange" is a new format and it covers the practice and needs of the Kitodo users. We are organizing mutual visits with different institutions to discuss practical subjects in the management of digitisation projects with Kitodo.
After more than 13 years, the maintenance and the enhancement of Kitodo.Production got more complicated, so we were very happy about a successful application for third party funding in 2016. The most important goal is the split of the software in a small kernel und a reasonable module architecture with documented interfaces. Kitodo needs a modern and above all a user friendly design that is based on current frontend framework. To enhance the existing role concept the integration of the framework ‘Spring Security’ module architecture will provide extended possibilities to design customized roles.
One team on the project – experienced in usability research – prepared a comprehensive evaluation including video recording of users doing their everyday tasks. We didn‘t confine our evaluation to Kitodo but went also to institutions where other products are used. The results lead to detailed epics connected to 3 different personas with different tasks in a typical digitisation process.
You will find again a close collaboration with the companies organized in our association – both companies participate by public tenders and will be part of the project until the end.
In our library (State and University Library Hamburg) Kitodo is the solid base to bring all our unique cultural heritage to the web. There are no scaling license fees to consider when new ideas arise. Kitodo enables us to manage a lot of projects at the same time and to support smaller institutions in Hamburg like special archives in their digitisation ambitions as we did this summer with several collaborations.
How do you get people interested in and engaging with digitized cultural heritage content? More specifically, how do you engage the creative community? These question posed by the EU to the cultural heritage sector during FP7 led to a slew of digital-leaning, app-focused projects that believed in the power of innovative digital mobile technologies, big data and interactive platforms. The lense looked towards disruptive tech of the late aughts as being the golden goose for cultural heritage to connect with the silicon valley-esqe creative minds. Projects like Europeana Creative, Apps4Europe and Europeana Space all took great steps to engage the creative sector in Europe through digital technologies. These projects provided invaluable insights into what creatives need from heritage institutes in terms of access. But as far as long-standing viable outputs go, the new products these projects hoped to coach and bring to market rarely left the pilot / prototype stage. Why? Because creating something like a tech start-up is hard. Dedicating focus on innovative digital technologies as the mediator for cultural heritage’s connection with the creative sector is a costly, time-consuming and overall resource-heavy with a payoff that, while when successful: huge; can result in a stockpile of prototypes and alphas with no user base and no hope to revive these obsolescence tools barring an influx of new funding.
Enter The Netherlands Institute for Sound and Vision’s RE:VIVE initiative, a low-tech approach to the creative re-use of digitized cultural heritage materials that uses the varied aspects of electronic music - Europe’s largest and most vibrant creative industry - to bring new perspectives to heritage, generate revenue and encourage new audiences to engage with heritage the way they want to.

Figure 1: Lakker - Struggle & Emerge LP cover (Flooding of Wieringermeer 1945) Image via Rijkswaterstaat
RE:VIVE’s goal is to bring together the worlds of electronic music and cultural heritage through the co-production and facilitation of new artistic works that make direct re-use of digitized cultural heritage materials. This includes work such as new records, film scores, live performances and workshops. The initiative puts heritage front and center. The content and context are the core source of inspiration as well being the building blocks out of which the new works are composed. RE:VIVE invites the artists to embrace the collection, to connect with it on a deeper level and manipulate it through their own personal, national and creative lenses.
The initiative’s approach to engaging the creative sector, fostering the re-use of digitized cultural heritage material and raising the profile of digital collections is low-tech through and through. RE:VIVE makes extensive use of readily available innovations and platforms. The innovation comes from the artist’s creativity. And in order to not obfuscate that innovation, RE:VIVE taps into existing familiar channels to deliver the new works. The new music is released and presented in the most traditional and common of methods: physically (vinyl), digitally (YouTube, Bandcamp, SoundCloud, Spotify etc.) and performatively. Furthermore, the consumption of music can be passive or intently active. From background music to deep-listening, it is up to the listener to decide how much attention they give to the music and the context behind said music. RE:VIVE capitalizes on that user-choice and welcomes it. If a listener is intrigued to find out more about the music and all the context that surrounds it, we make that information available not just on our own platforms, but on music platforms where listeners already go to learn more about their favorite records or artists. But, if someone only listens and never dives deeper, we can take solace knowing that they’re consuming re-used cultural heritage, whether or not they’re aware of it. Using these methods allows RE:VIVE to get straight to the audience and operate on a shoestring budget.
But RE:VIVE is not alone in these endeavours. Instead of dedicating resources towards becoming an event promoter, music publisher or record label, RE:VIVE serves as the intermediary. We bring together the archive and the artist and the artist and the publisher. It’s the publisher or promoter that brings the artist to the audiences. By the rules of the transitive property, the archive is also brought to the audiences. Since RE:VIVE can be involved in all the steps, we’re able to ensure that the archival re-use aspect of the projects remains intact. What’s crucial to note though is that the buy-in and commitment from all involved partners is essential.
Releases of new works aside, RE:VIVE also uses low-tech solutions to answer the question of “how to get creatives engaging with heritage materials?”. RE:VIVE curates “sample packs” a collection of openly licensed archival audiovisual material related to certain theme(s) that we make available for electronic music producers. In the electronic music community, sample packs are commonly large sets of downloadable digital files that come pre-packaged, immediately giving an artist a wealth of material to search for inspiration. Following suit, RE:VIVE simply uses WeTransfer as a way for artists to access the material via the RE:VIVE website. It not only is easy and cheap, but it also allows for large amounts of heritage material to reach the creative re-user. To date using this method RE:VIVE as been able to deliver over 500.000 digitized heritage items to users around the world.
RE:VIVE builds on the tireless efforts of open culture advocates, digitization specialists and the countless institutes that make their collections available online both locally and through Europeana. Taking this crucial work, RE:VIVE translates heritage for the creative community. The initiative uses platforms and methods familiar to the end-user because that’s what end-users want and need. Vernacular, branding, partnerships and visibility are all imperative and low-tech. Partnering and working with the creative sector or capitalizing on the added value that artistic interpretation can can provide with helping understand identity and a feeling of “Europeanness” does not need to be expensive, it needs to be human. Communities are built on communication and trust, and once one door opens, it’s only a matter of time before more doors open to new audiences and new users.
Digital exhibitions have their place in the cultural heritage sector, as do apps and interactive platforms. These tools allow for beautiful interfaces and in-depth contextualization. They can gather millions of unique views and raise the profile of any heritage institute. But such breakthroughs are the minority. They’re also expensive, take a considerable amount of time, coordination and require regular technical upkeep to avoid opalescence. The investment and payoff can be overwhelmingly successful or crushingly disappointing because the hardest part of these projects is simply getting audiences to this specific platform. And in terms of the long-term success and sustainability, those initial traffic numbers will inform future activities and inspire further work. If an app falls flat in its first 3 months of deployment any, work that comes after will require more budget which is not always available for heritage institutes. Due to the lack of dedicated personnel and a need to continue developing, platforms fall into desolation, barely hanging on in the digital world. In tech, “vintage” is not cool (hardware excluded). No one revisits a 10-year-old app. Music is timeless. Like the art on the walls of museums or records in vaults, it’s these human works that will live on.
Wai-te-ata Press is a letterpress printery established in 1962 at Victoria University of Wellington in New Zealand. In addition to teaching and research on the history and practice of media technologies, we produce fine press handmade books and experiment with analogue printing of 3-D printed types. We also undertake digital humanities projects working with NZ cultural heritage data. Our Qilin project demonstrates the challenges we face and some solutions we have developed for Chinese Optical Character Recognition [OCR], harnessing the innovation potential of next generation engineers and computer scientists.
Our Chinese type restoration and scholars’ studio project started in 2016 with the acceptance of one tonne of Chinese full-form character lead type that had been in storage in a farmer's field south of Auckland. This type, ordered from Hong Kong, arrived new in Wellington in 1952. It was used to print the New Zealand Chinese Growers Monthly Journal, the organ of the Dominion Federation of New Zealand Chinese Commercial Growers. This journal continued for two decades, linked market gardeners around the country, published local and international news, featured articles on the civic careers of influential growers, and included Cantonese language lessons. At any one time, every Chinese household was said to be reading one of its 700 monthly copies. The journal was digitised by the Auckland City Libraries in collaboration with the Alexander Turnbull Library, funded by the Chinese Poll Tax Heritage Trust and made publicly available. In 2017, those assets were transferred to the National Library of New Zealand for inclusion in their PapersPast digital collections. However, since the format did not conform to the existing PapersPast standards there were questions around when this important cultural collection would again see the light of digital day. Challenge number one, therefore, had to do with how to machine read the Chinese types in a journal that mixed both Chinese and Latin letterforms in a complex layout grid.
Challenge two was whether we could address the OCR problem by leveraging the existence of the original types which arrived in a disordered state and with characters that over time and frequent use had become worn and illegible. Could we combine the type identification required for sorting, cleaning and cataloguing the collection with parsing the journal's digital images so we would know how many of each character we had and therefore how to design type cases to house them? We had already started to image each of the estimated 300,000 individual type sorts using a high power microscope that also enabled us to assess the condition of the types, but the scale of the operation was proving daunting. Because we wanted to be able to restore and reuse the collection to tell new or little-known stories of Chinese New Zealanders, the types had to be carefully organised for use. The pages for each month's issue were set vertically for Chinese and horizontally for Latin in neat rows with spacing (leading) between the lines, furniture filling out the empty spaces, and all locked into open metal frames called chases so the type didn’t move or fall out. The completed formes were sent to the printer and used to print the journal. These formes were then returned, and the individual characters or sorts replaced (distributed or diss-ed) in the correct type tray, back in the office.

Figure 1: From type catalogue

Figure 2: to metal types set up for last issue of journal
Figure 3: to printed newspaper scans
To help us solve our interlocked challenges, we proposed the Qilin project as part of Victoria University of Wellington's School of Engineering and Computer Science third year client-facing programme. We tasked the student team to help by analysing images of the newspaper and needed to devise a pipeline that built in industry capability and international digital cultural heritage standards and protocols. Behind the scenes, we negotiated access to the digital images and permission from the copyright holders, our friends the Growers. Next up was storage options. We had only 60GB of data, but we wanted the students to think about cloud storage provision and what that meant for cultural data, sensitive or otherwise. Since we were working simultaneously on another Māori cultural data project, we were acutely aware of issues of data sovereignty. Our first choice was a NZ-based cloud provider but only one currently exists and the timing and scale of the project precluded using it. We then investigated CloudStor, an Australian service, that we could access through our university's REANNZ [Kiwi Advanced Research and Education Network] subscription. When the uni severed its connection with REANNZ, the challenge became, where to next? We could have delivered the image files to the students to host locally, but we wanted to future engineer the project and ensure that the students learnt how to call out to a third-party provider and create code that could be resilient in the event of future repository shifts. We finally put the imagery in Figshare - an online digital repository for researchers - in a private collection, in which each issue is a figshare fileset, a set of high res TIFFs.
Over the entire publication there were over 2,800 pages delivered in 2,800 high resolution scans. This is a large amount of data to process as each page takes a reasonable computer around 7 minutes to process an entire page. Since processing all 2,800 pages sequentially would take about two weeks, we decided to build a system that could process the pages in parallel. After trialing a number of parallel processing options including Apache Hadoop, we ended up using Apache Spark which is a framework for processing Big Data. Spark uses a cluster with worker nodes where we could set each worker to process one issue and return the results. Microsoft Azure's HDInsight provides Spark in the cloud: we used the free student allocation of NZ$300/month. With 6 students, we could cycle through our allocation, experimenting with ease, and not be constrained by issues of funding or timing.
To process a page of the newspaper there are a number of steps required; finding the characters printed by the type, turning the characters into a machine-readable format and counting the frequency of each occurrence of character. The first step, layout analysis, was not trivial. The layout of the newspaper changed considerably between pages and issues. There is Chinese text in ads throughout the newspaper which were printed using blocks rather than type; often sections used hybrid scripts and bilingual text. Moreover, character definition varied according to the amount of wear of each character as well as the amount of printing ink applied, thus changing the density of image blackness on the page. We originally tried some prebuilt solutions such as Google Tesseract layout analysis and OCRopus. However, these had very poor accuracy. The approach we finally settled on was using a deep convolutional neural network [CNN] based on GoogLeNet architecture. It was trained to classify the section our samples were from. We could then run a whole page of the newspaper through the network and use Class Activation Mapping [CAM] to find out where the different sections were in the page of the newspaper. These were combined with colour-coded images that differentiated headings from subheadings from body text. Since different type sizes and sometimes even fonts were used for different sections, this was an important stage in the workflow. However, while it could recognize the different sizes of characters well, it was not as adept at recognising the characters that are in a different font. This ended up not being that much of an issue given the masking causes the outlier characters to become unrecognizable, meaning the OCR solution would not recognise these as characters.

Figure 4: Layout challenge
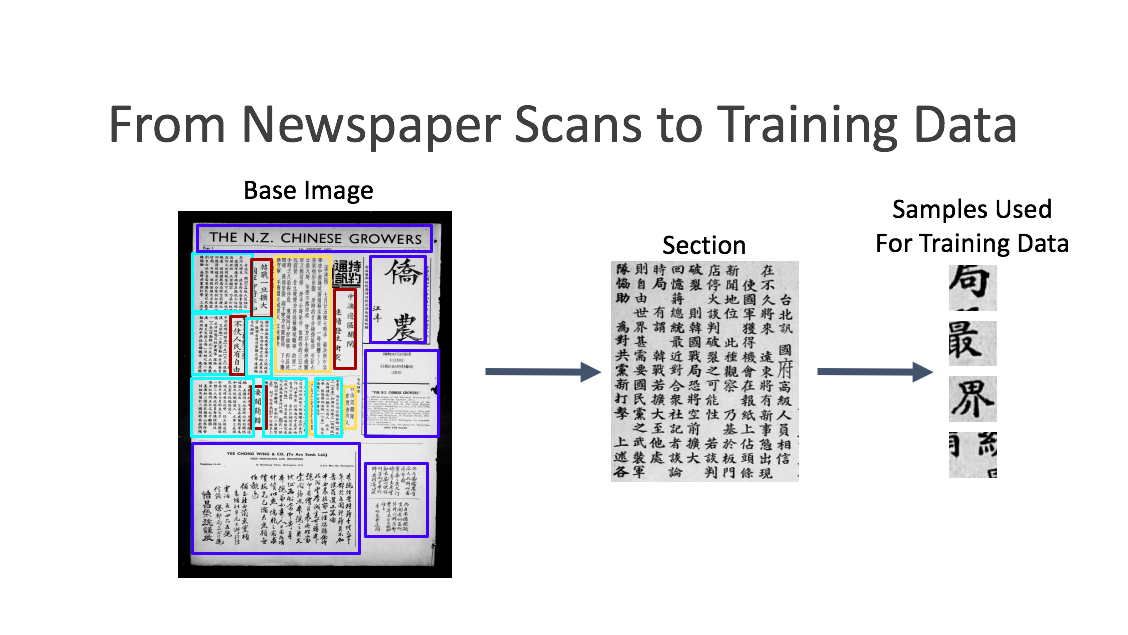
Figure 5: Layout analysis
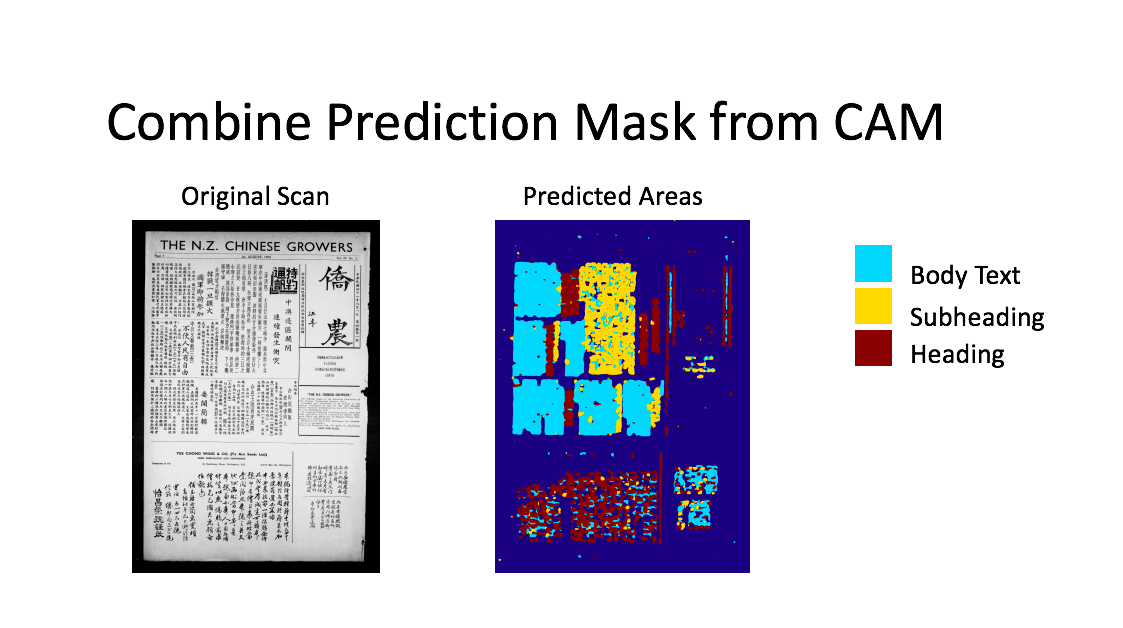
Figure 6: Class Activation Mapping
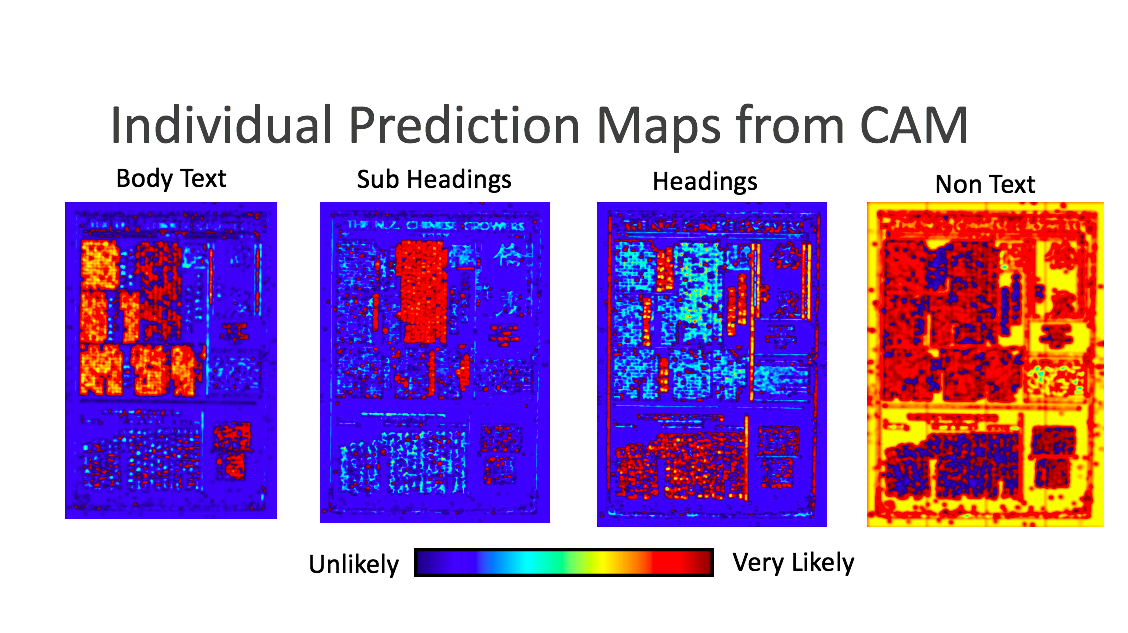
Figure 7: combined Prediction Maps for one page
For the OCR component we ended up using Google's Tesseract. We attempted to create our own OCR solution that would work better specifically for the Chinese language. However, we were only able to achieve 50% accuracy across 13,000 different characters using training data from unicode fonts via the type catalogue used to order the original metal types. Potentially, we could have achieved higher accuracy scores by reducing the number of characters selected from the newspaper. However, given Tesseract delivered very approximately 80% to 90% accuracy on sections from the newspaper, it was unlikely we could have obtained any better accuracy scores. We generated frequency tables copied from the cluster, for Body, Subheading and Headline. Throughout the process, the outputs were tested by our human expert, Ya-Wen Ho, and refinements were continually iterated for printed type to unicode translation accuracy as well as usability of the tables for our cataloguing and design challenge.
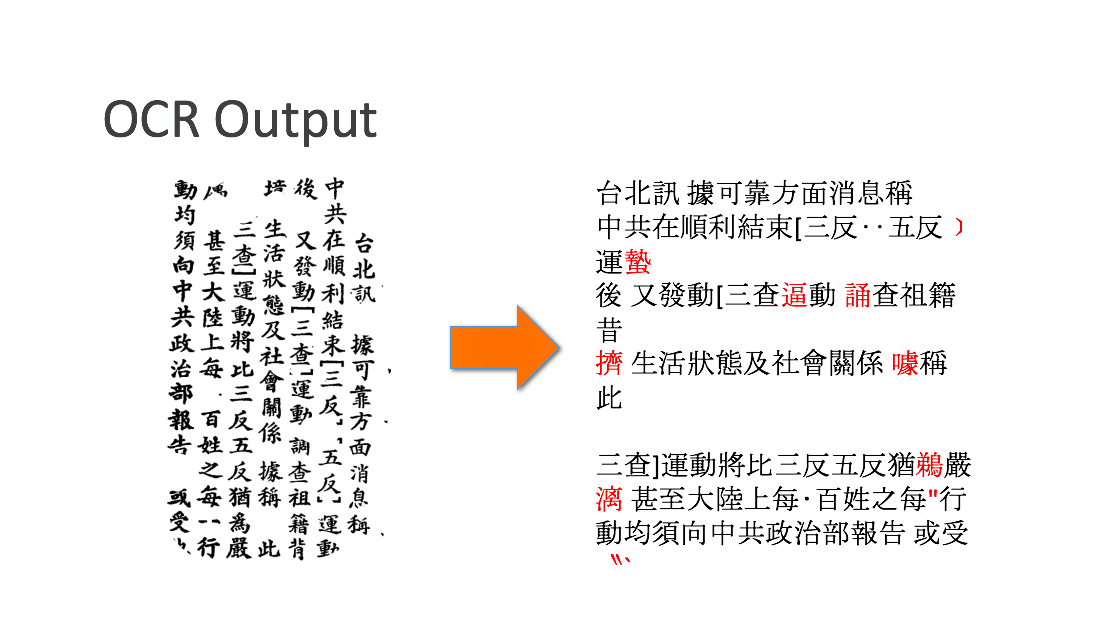
Figure 8: OCR results
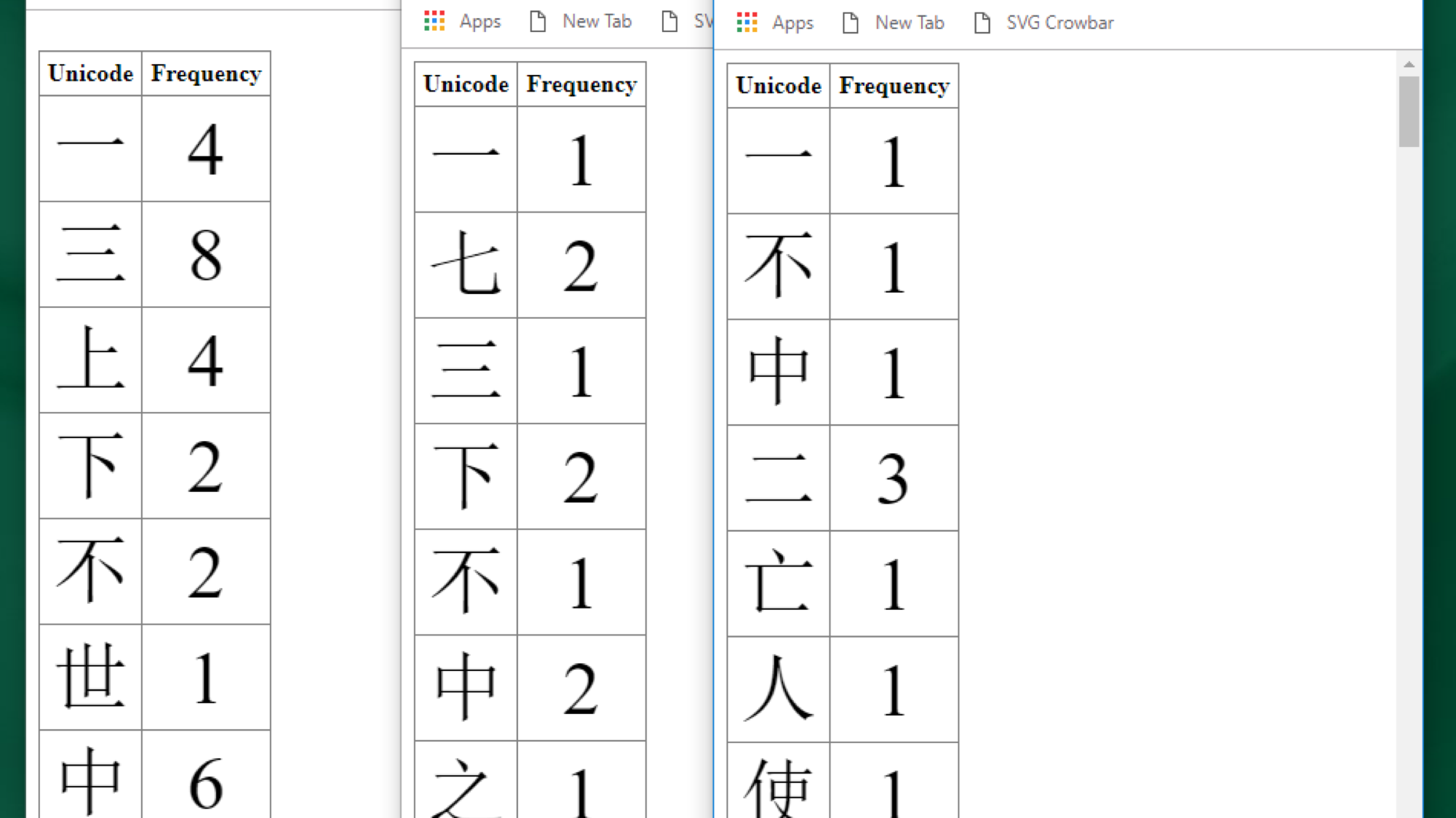
Figure 9: Unicode frequency tables
By the end of the eight-month project, the students really helped us to understand the complexity of the challenge we gave them. As an example, we shared scans of the catalogue from the Hong Kong typefoundry. These were the clearest printed images of the physical types we had and furnished a training data set to intermediate between the types and the printed newspaper. The catalogue also provided a key learning experience on how to undertake image rectification and image splitting. The team's code used knowledge of the fixed page format then ran Tesseract OCR on the characters to obtain the unicode values that were critical to distinguishing type frequency in the newspaper.
Another challenge for the team's character checker was the existence of multiple variants of a character. The Taiwanese Ministry of Education dictionary of variant forms documents the character for 眾 zhong [a crowd] as historically having 40 variant forms. How could we know if these unicode glyphs existed in our type collection? We turned to the conceptual model developed by the Unicode Consortium for variant unification of Han ideographic characters. It expresses written elements in terms of three primary attributes: semantic (meaning, function), abstract shape (general form), and actual shape (instantiated, typeface form). As such, it provides a triangulated variable system that could, in future, assist in character disambiguation, particularly for worn types with their inherent legibility problems. This 3D model also returns us to the three-dimensionality of our physical types and where we began this project.
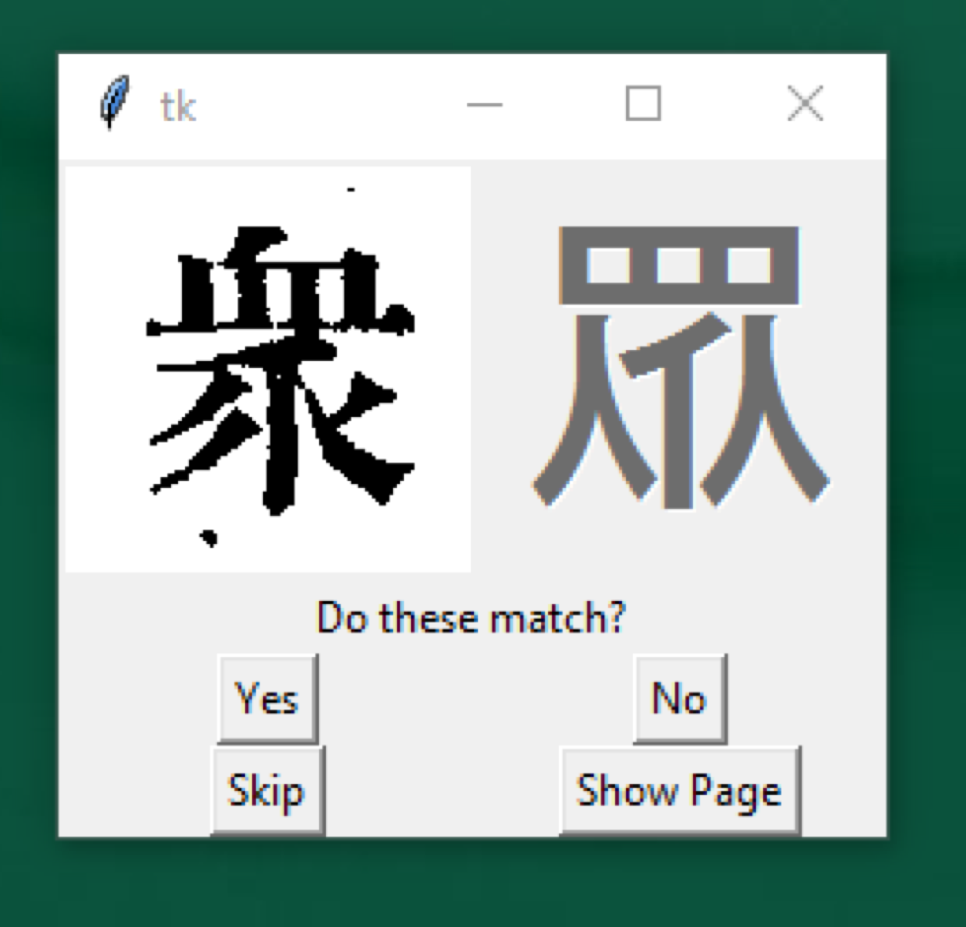
Figure 10: Character checker
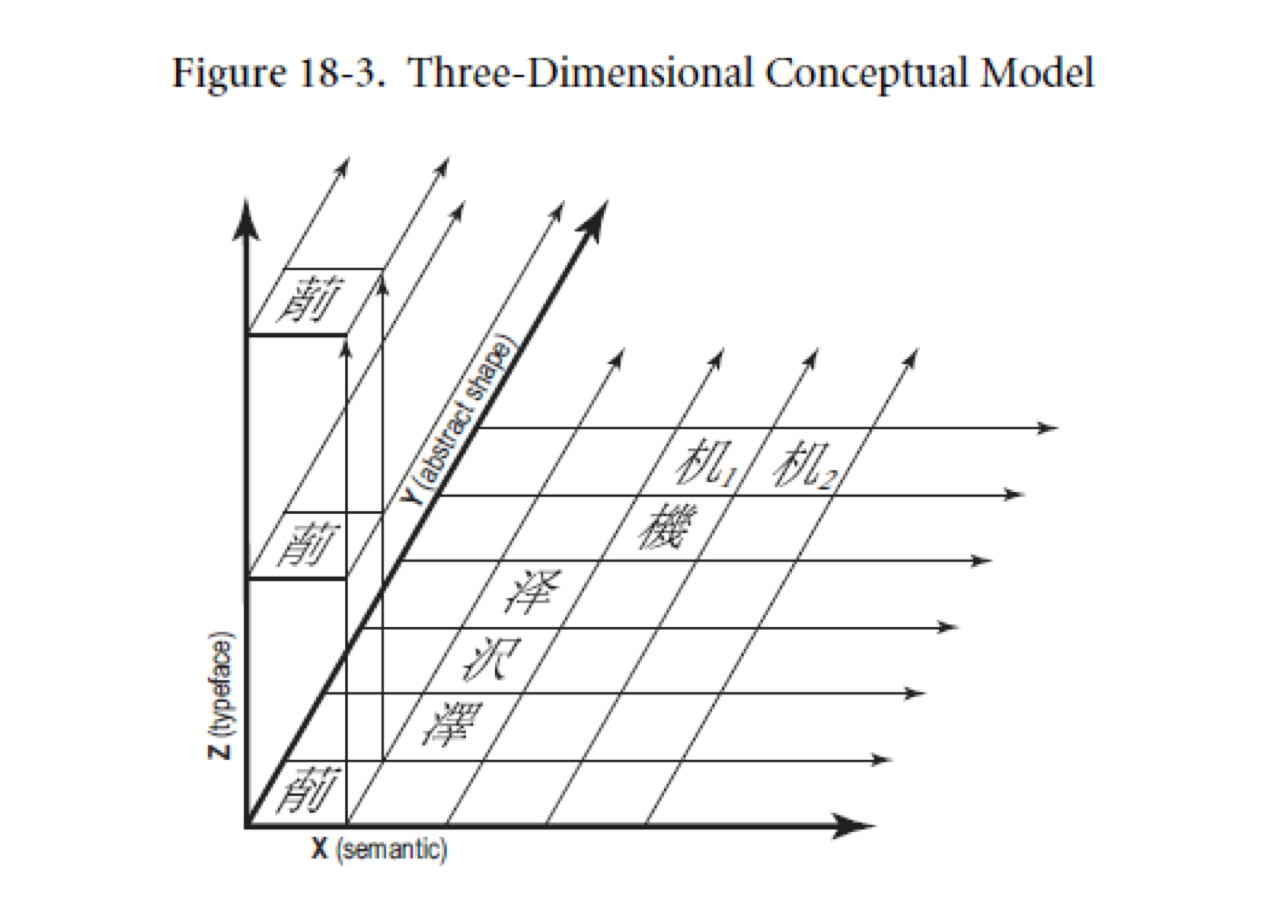
Figure 11: and 3D conceptual model for variant forms
In addition to having many better ideas of the complexity that exists in our work, the students have prototyped an infrastructure for us to scale out, enabling us to begin action research into Big Data analytic approaches. They have helped us resolve a specific problem, but the trajectory of their solution means transferability to other cultural data contexts and across multiple non-Latin languages. If it also helps rendering an important heritage resource once again available to the public, then we will have achieved one of our public engagement and impact objectives. In the meantime, the project has made us all even more aware of the fragility of our digital resources and the need to prevent them from becoming casualties in the dark archive of the cultural imperium.
The team's project, Qilin, is online, public and open source: 100% student-led team work.
Figure 12: Qilin wrestled
Wai-te-ata Press wishes to thank the Dominion Federation of New Zealand Chinese Commercial Growers, Auckland City Libraries and the National Library of New Zealand and Alexander Turnbull Libraries. And, most importantly, our all-star, student cast: Andrew, Deacon, Inti, Rachel, Tabitha and Tomas.
Evaluation of search systems has been an active area of interest for decades; however, much of the focus has typically been around assessing system performance based on the quality of search results. Given how information access systems to digital cultural heritage increasingly provide features that allow users to explore and discover content beyond simple search modes, in practice we need to think outside the search box when it comes to evaluating performance and success. This article describes perspectives for evaluating information access to digital cultural heritage within two example systems: PATHS and Europeana. I conclude by suggesting a more holistic view of search evaluation using a broader framework of systems success.
Traditionally, the most common approach to evaluating search is system-oriented where the focus has been to assess algorithmic performance, such as retrieval effectiveness or efficiency. Evaluation is typically performed in batch mode and offline using pre-existing benchmarks, such as Information Retrieval test collections. However, user- or human-oriented approaches are increasingly being used, taking into account the characteristics of users, their contexts and situations, and their interactions with a search system. All of these factors may affect users’ search behaviours and influence their notions of perceived system or search task success. Various methods can be used to evaluate search with people (typically surrogate real end users, such as student volunteers), often following existing HCI approaches, such as task-based comparative evaluation in a usability lab.
However, in contrast to offline evaluation methods and lab-based user studies, there has also been increased activity around methods for online evaluation. This approach utilises a fully-functioning system in an operational setting, where traces of user-system interactions from real users undertaking real tasks are analysed and used to infer behaviours, such as success. Such methods are powerful, but require an operational system with sufficient numbers of users. In practice, multiple evaluation methods and activities will take place throughout system development (formative), once an operational system is built (summative) and as the system operates (online).
A challenge for search provision in digital cultural heritage is that systems are often feature-rich to support user engagement and serve a plethora of information needs and search behaviours. This means going beyond simply evaluating the relevance of search results to assessing additional components, such as visualisations and recommendations, and going beyond the system to understanding users’ contexts and needs.
The PATHS (Personalised Access To cultural Heritage Spaces) project is the first example I consider where the focus of evaluation activities went beyond the search box. PATHS was funded under the European Commission’s FP7 programme and developed methods to support search and discovery in large and heterogeneous cultural heritage collections. The prototype system provided users with various features, such as links to related items, item-level recommendations, a thesaurus based on a data-driven subject hierarchy and collection overview visualisations, to support the user. A summary of PATHS can be found in this EuropeanaTech Insight article.
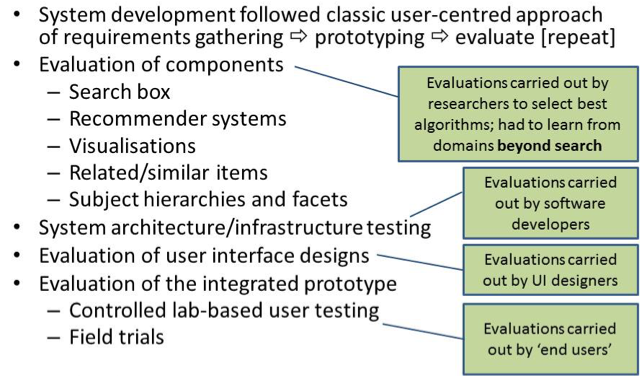
With respect to evaluation the retrieval system was just one component of many and Fig. 1 summarises evaluation activities carried out during the project. System design followed a classic user-centred approach to develop requirements and inform the design of prototypes. Each system component was developed independently by different research groups and subsequently integrated into an operational system. Components were evaluated using an appropriate discipline-specific methodology, e.g., recommendation functionality evaluated using techniques from the field of recommender systems. The components were then integrated into a working prototype by software engineers making use of evaluation methods, such as unit testing. The user interface was also developed separately through iterative development of low- and high-fidelity prototypes and testing using lab-based methods. Finally, the integrated prototypes were evaluated using task-based evaluations in both controlled lab-based settings and more naturalistic field trials. Results and user feedback informed future development. More details about evaluating PATHS can be found in (Clough, 2015).
The second example I consider where search evaluation focused outside the search box is Europeana, specifically work undertaken in the Digital Services Infrastructure, DSI-2 project and improving search for Europeana Collections. Various forms of testing have been carried out within Europeana since 2011, including evaluation of: (i) the user experience; (ii) usability of the user interface; (iii) quality of content and metadata; and (iv) search quality. Juliane Stiller and Vivien provide a comprehensive summary of evaluation activities undertaken over the past decade in their TPDL’17 paper. In the DSI-2 project we developed a framework in which to evaluate search quality (shown in Fig. 2).
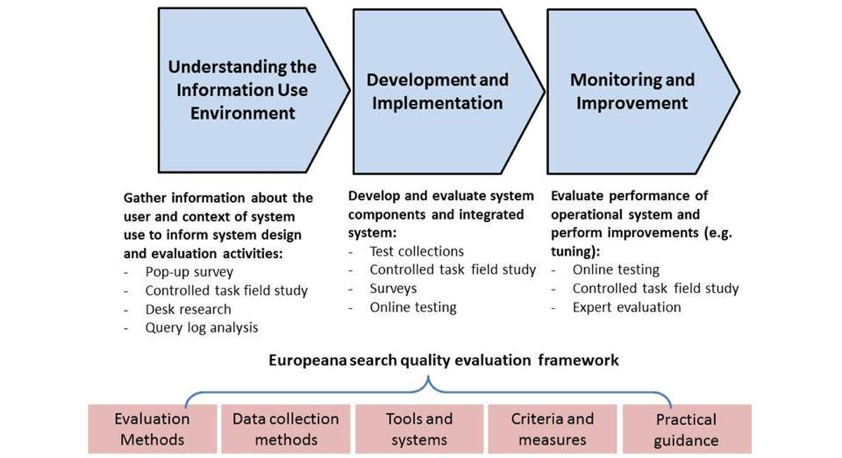
The evaluation framework included suggestions for evaluation methods, data collection methods, suitable evaluation criteria and measures, and best practice guidance. Multiple approaches are required to evaluate Europeana and its components during various stages of the development lifecycle: (i) firstly, understanding the user and search context (the information use environment); (ii) secondly, the development of components and subsequent integration into the operational Europeana system; and (iii) the post-implementation stage of monitoring and improving search (e.g., relevance ranking tuning). The focus on users and the wider context of information use (e.g., typical search tasks) was important for evaluation in the design of appropriate evaluation instruments in subsequent stages. For example, understanding and categorising users’ search tasks informed the design of task-based evaluations (see our TPDL’17 paper describing who uses Europeana and why); analysis of search logs provided suitable queries for test collection design. More details of the work can be found in D6.3 the search improvement plan.
The previous examples of search evaluation have gone beyond focusing on the search box and taking into account users and context of information use. In practice, understanding system success and coordinating evaluation activities and aggregating their findings can be difficult due to diversity of methods used and multiple stakeholders. A more holistic view of search evaluation needed.
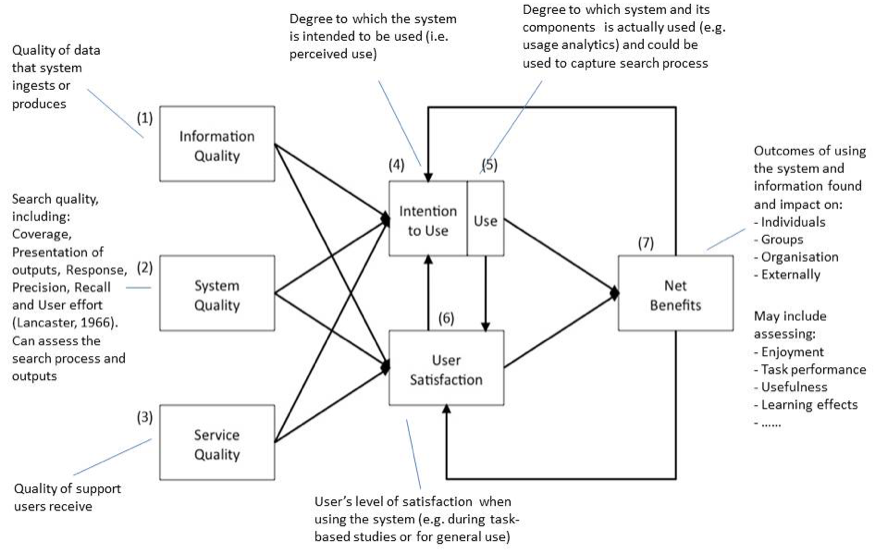
Fig. 3 shows one possible framework based on the ‘classic’ view of information systems success as proposed by William DeLone & Ephraim McLean. In this view success of the system centres on user satisfaction (6) which in turn will drive system use (5) or intention to use the system (4). User satisfaction with the system will be based on data/information quality (1), system quality (2) and the quality of the provided service (3). The benefits of using the system and users’ satisfaction will result in improved task performance, engagement with the system, learning etc. Parts of the framework in Fig. 3 clearly interrelate and impact on success. Having a broader view beyond the search box and sharing our experiences with evaluation helps us to think outside the search box.
Work undertaken within the PATHS and Europeana DSI-2 projects involving many individuals. Particular thanks go to Paula Goodale, Jill Griffiths, Monica Lestari Paramita and Timothy Hill.
An excellent overview of various approaches to evaluating search systems is provided by Ryen White in his book “Interactions with Search Systems”