Get your vocabularies in Wikidata...
In the case study, Get your vocabularies in Wikidata...so Europeana and others can get them, we are describing the practical steps envisioned, based on recent experimentation done by Sandra Fauconnier consisting of aligning the MIMO vocabulary with Wikidata.
Europeana offers a trusted online repository of cultural heritage objects. In order to achieve its mission it is crucial for the metadata described in Europeana to be semantically rich and multilingual.
Enriching the metadata with Linked Open Vocabularies has allowed us to improve our metadata. We perform automatic metadata enrichment using external value vocabularies and datasets such as GeoNames and DBpedia and exploit the semantic relations and translations offered by those vocabularies.
When selecting which vocabularies we use for our automatic enrichment, we seek to apply some criteria, especially for minimising our semantic commitment and abstracting from the needs of specific domains or (sub)-communities. Europeana will therefore select large, rather generic and multilingual data sources. And we will favour data sources that are well-connected such as 'pivot vocabularies' where equivalent elements in other vocabularies are indicated.
Wikidata, as mentioned in the recommendation 7 of the 2015 Europeana-Wikimedia Task Force report, fulfils many of our criteria Europeana for data sources selection. The coverage of Wikidata and Europeana in terms of entities and languages are indeed very much aligned[1]. In addition, Wikidata bring together crowdsourced resources and authoritative datasets (such as VIAF) and so guarantees a good balance between the authority and the quality we are looking for.
Besides our "centralized" enrichment, Europeana would also benefit from more “local” semantic resources used by our data partners and which are often the results of tremendous data curation efforts. Europeana has started to leverage some of these reference authorities or vocabularies[2]. However this results in a rather cluttered 'semantic layer' where semantic with different scope and grain can co-exist without being aligned. Our position is that using Wikidata could bring a solution to better handle domain specific vocabularies, as it allows manual upload and alignment of semantic entities.
Our proposal is basically to use Wikidata as a pivot to access links to more specialised vocabularies[3]. The practical approach for a data provider would consist in several steps resulting in the alignment of their source vocabulary with Wikidata. This would benefit:
- The GLAM community, which could leverage the power of Wikidata to share their local resources and then have them reused in a wider web context.
- Wikidata as it would enrich its existing knowledge base.
- Third parties like Europeana as it would enable one to access more specialised knowledge via Wikidata.
We have described below the practical steps envisioned, based on a recent experimentation done by Sandra Fauconnier consisting in aligning the MIMO vocabulary with Wikidata. The MIMO vocabulary was chosen as a use case as it has been used in a previous Europeana related projects[4] for describing musical instruments and is one of the vocabularies Europeana “dereference”, i.e., fetch from the concepts URIs all the multilingual and semantic data attached to them. The MIMO vocabulary is a multilingual[5] controlled vocabulary of musical instruments built to ensure consistency of classification for the musical instruments. It is a result of an alignment of a vernacular classification with the professional “Hornbostel-Sachs” classification.
Steps in Contributing
Preparing the import The first step consists in importing the source vocabulary in the Mix'n'match tool. Depending on the structure of the source vocabulary, some preparatory work might be required as the Mix'n’match tool does not currently handle hierarchies. Typically a vocabulary described in SKOS will present a hierarchy of concepts. In this case the vocabulary structure will have to be flattened, and the hierarchical structure added back in Wikidata later, when refining the Wikidata entities. Simple tools such as Open Refine or Excel can be used to support these data cleaning activities. When the source file is ready, it can be imported into Mix'n’match via the import tool.
The MIMO vocabulary is available as a SKOS/ RDF XML file. It is highly structured as each musical instruments family and musical instruments are described in a hierarchy of concepts. The vocabulary hierarchy was therefore flattened and all the translations and aliases were concatenated into strings so that they would then fit into the Mix'n’match descriptions using Open Refine. The XML was converted into a Excel spreadsheet for import. Note that in some other cases more data cleaning might be required such as removing extra white spaces, duplicates, normalising some terms etc. In total 2.471 terms were imported into Mix'n’match. Note that some hints of the hierarchy (mention of the broader concept) were added in the description of the terms on Mix’n'match, in order to facilitate the manual verification of the automatic alignment (see later step).
Other preparation work Importing the source vocabulary in Mix’n Match will allow the alignment with existing Wikidata entities. In order to capture the link between a Wikidata entity and the source vocabulary entity, i.e, the alignment and describing at the same time the type of link; a new Wikidata property needs to be created. This property will contain a string or a URI representing the identifier used in an external system: https://www.wikidata.org/wiki/Property:P3763 - MIMO Instrument ID in the case of MIMO.
Aligning Wikidata and the source vocabulary Once the vocabulary has been imported the alignment work can start. Mix'n’match will automatically match terms from the source vocabulary to Wikidata and these matches must be checked manually. Other correspondences (not detected by Mix'n'match) will need to be created manually by directly entering the identifier of a Wikidata entity equivalent for a MIMO concept.
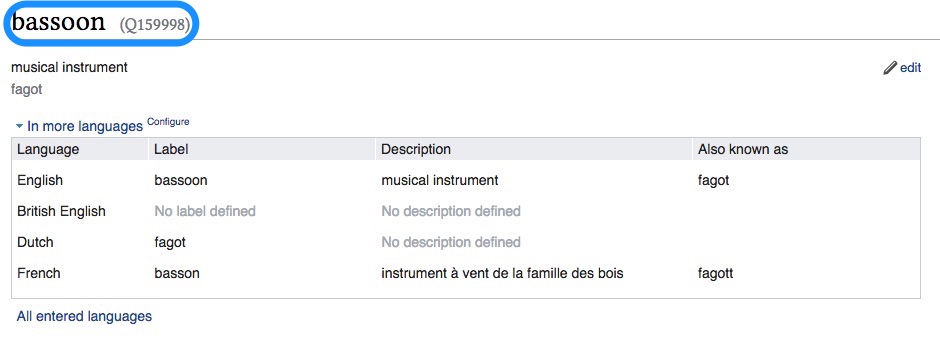
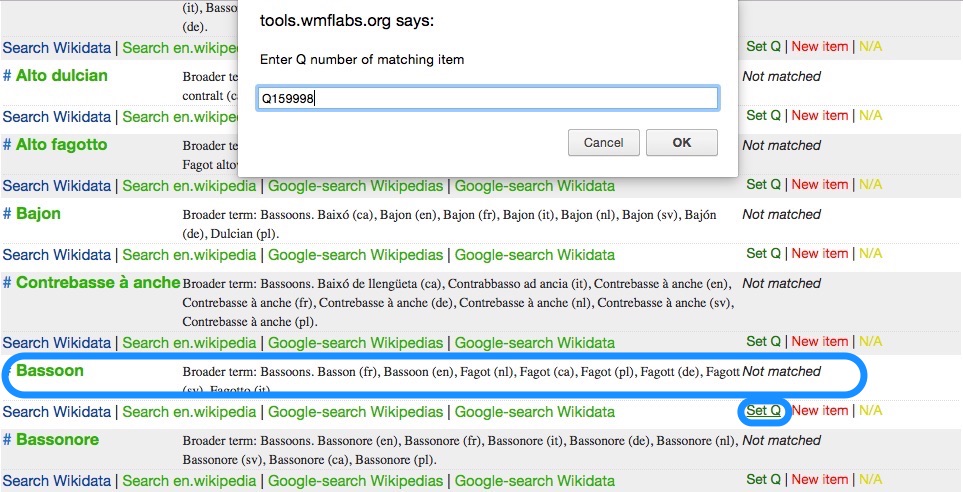
An example of manual match done by entering the Wikidata id of an entity equivalent to the MIMO concept.
More details on how to use Mix‘n’match are available at the Mix’n’Match user manual. In the case of MIMO142 alignments were created automatically.

An example of automatic match to be confirmed in Mix'n'match. Note that next to the labels in languages available for the MIMO concept being examined, a clarification note has been added to indicate the broader class of instrument.
Refining the Wikidata entries Once the alignment has been performed, one may want to refine the existing Wikidata entries directly. For instance, we mentioned earlier that Mix'n’match doesn’t support hierarchies yet.The hierarchical relationships such as broader or narrower terms can be added manually on the Wikidata entries themselves at this stage.
The MIMO keywords vocabulary are organised by a higher-level classification coming from the professional “HornbostelSachs” classification. The more specialized terms provided by the classification are not included in the import but could be then manually added to the Wikidata entry
Creating a new Wikidata entry When a Wikidata entry doesn’t exist for a given concept in the source vocabulary, the solution will be to create it by directly editing Wikidata. If required properties (e.g. domain specific properties [6]) are not available, the data partner will be able to propose new ones in the Wikidata ontology [7].
We now need your help to complete the remaining alignment. You can directly contribute at https://tools.wmflabs.org/mix-n-match/#/catalog/391.
Outcomes and Next Steps
The increased reliance of Europeana services on semantically rich and multilingual metadata illustrates the need for rich and open resources such as Wikidata. We also believe Wikidata also offers a perfect platform to increase the engagement of the GLAM community and the further research community and support the sharing of more resources. We would like to build and gather more resources (cases, manuals, workflows, etc) to convince and train our partners to align their vocabularies with Wikidata. We welcome any support for this idea !
[1] Wikimedia developments task force recommendations at http://pro.europeana.eu/public...
[3] Before importing any data to Wikidata, data providers would need to check their data is suitable for Wikidata: https://www.wikidata.org/wiki/...
[4] MIMO (http://www.mimo-international....) and Europeana Sounds (http://www.europeanasounds.eu/)
[5] English is the pivot language, and translations in seven other languages have been added.
[6] For more example see the suggestions for CreativeWork at https://www.wikidata.org/wiki/...
[7] Before being created new Wikidata properties have to be proposed and discussed at https://www.wikidata.org/wiki/...