We want better data quality: NOW!
Data Quality, a topic which is of utmost importance for Europeana was the theme of a session organised as part of the last EuropeanaTech Conference held on February 12th and 13th earlier this year. The Data Quality session opened with a series of presentations highlighting various aspects of data quality. These were followed by roundtable discussions involving the speakers and all the participants.
The following report summarises the discussions that took place during this session, with the help of the notes gathered by the participants. It touches upon the problems leading to poor data quality and proposes solutions to tackle them. The report also attempts to find useful elements of definitions that help better grasp the notion of what good data quality really is.
Defining and finding solutions for data quality is not trivial
Cultural institutions have developed frameworks to ensure the provision and exchange of structured data. Data quality, however, remains a hot topic for discussion.
Cultural heritage institutions work within a framework that is, in theory, structured and well defined. This framework mainly relies on standards that have been defined over the years and attempt to reflect the practices of specific domains or disciplines. All the standards used by cultural heritage organisations, from the main domain-specific ones such as MARC21 and EAD (Encoded Archival Description) to the more discipline-specific models such as the CARARE model [2], or even cross-domain models like the Europeana Data Model (EDM)[3], have extensive written documentation about their models and provided schemas specifying how elements should be used, their semantics and constraints. The participants around the table representated of this diversity of standards.
In the same way that data providers and aggregators started to build large scale aggregation system, data provisioning workflows have been formalised into reference models such as OAIS[4] or the more recent Synergy model[5].
Participants all agreed on the puzzling question: if we have standards, then “why is the data so crap in the end?” as one participant cried.
It also raises the question, why is it to difficult to achieve good data quality? And what even is good data quality?
This diversity of subjects discussed at the roundtables shows how close to impossible defining data quality in one sentence is and doesn’t make the concept more intelligible. It seems that participants could find common ground, however, by listing the problems we, as cultural heritage institutions, all encounter when we lack good quality data.
Data Quality and Aggregation workflows
Europeana has weaved an impressive web of data channels between its direct data providers and main aggregators. However the more this web grows, the longer the data chain becomes. As the data travels through different channels its quality deteriorates.
All the participants agreed that the majority of the issues around data quality stem from the principle of data aggregation. Cultural heritage institutions within the Europeana ecosystem are now all working within an established workflow; this involves the delivery of data from one provider to an aggregator and then to Europeana. We won’t go into detail here, but we know that this process involves many different actions on the data that can result in the improvement of data quality, or, on the contrary its diminishment. From data creation and delivery, to mapping definition, normalisation, and enrichment, data is defined and redefined according to different data standards. It is also prepared for different environments and consumers.
From a provider or an aggregator to Europeana, the chain is long and the data providing process requires a lot of communication between different agents. Along this chain different agents will discuss different aspects of the data (the knowledge described in the data, the data structure, the technical implications) and will specify different types of requirements (e.g. mapping rules, URI generation and normalisation rules) which might interfere with each other. The focus of data provisioning might also differ from one agent to the other.
Aggregators highlighted that often the focus of the metadata description concentrates on the digital object and not on the primary object as could be the case, for instance, in bibliographical records. It is difficult to carry these different perspectives along the process of aggregation. Participants talked about the fact that “aggregators have to take the data that is given to them” or showed concern about the fact that we “merge or match metadata of different origin and quality into one system”.
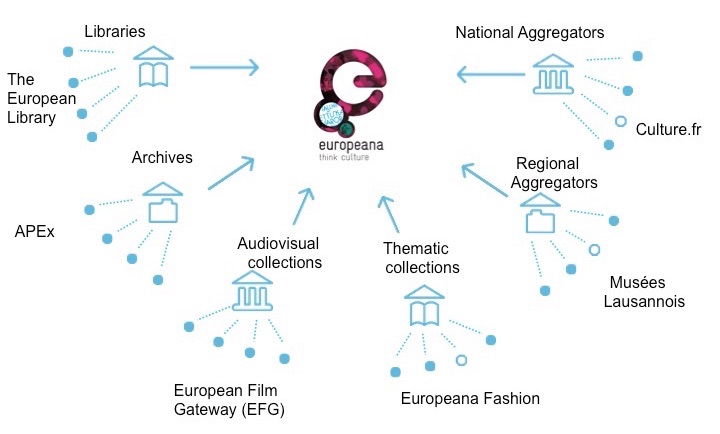
The data transaction flows are important within the aggregation workflow as they are key points where data quality can be affected. Mappings, for instance, illustrate this tension.The transfer of knowledge from one side to the other is key and can’t be done without communication and a transparent and documented aggregation process. However, the aggregation process is quite often criticised for being too inflexible to allow a proper feedback loop between a provider and its aggregator. The lack of staff members in data providing institutions compared to aggregators also hinders a seamless process.
Poor data quality affects, first, the knowledge represented in the data, and the best keeper of this knowledge are the institutions that have created it at source. It seems therefore natural that the communication and feedback process should be reinforced between providers and aggregators. The new Synergy model mentioned earlier gives a more prominent role to the knowledge experts and involves them in the entire process of the aggregation workflow. As highlighted by the speaker Runar Bergheim in his presentation about the Geolocalisation enrichment tools developed in the LoCloud project[6], it is better to manage information at source or as close as possible to its origin. In the context of data quality, “source” designates the data creators, but also the knowledge keepers; roles that are often of the provider’s remit. Providers are preserving intangible heritage, which is key for interpreting the semantics of data.
“We need tools! ” they said.
Apart from the issue of communication and general flow of information from one provider to its aggregator and then to Europeana, the lack of information about existing tools supporting the process of data provisioning is also an issue.
The functionalities needed from these tools include the export, the mapping and the transformation of the data from one data model to another. Because of the lack of tools, some providers might start acknowledging data quality issues only when publishing their data. These tools should be able to support good data quality along with the data provision process and help providers focusing solely on data, such as OpenRefine presented by Ruben Verborgh. However these needs should also be taken into account by software providers when developing tools for the cultural institutions. But in this case who should be communicating with them: providers, aggregators, or is it a role for Europeana? Participants expressed their interests in open source softwares, rather than commercial products, but highlighted that they are not always visible on the Web and are sometimes poorly documented.
Data enrichment, a solution for better quality data?
When the data is not there, we tried to create it. Using context to enrich existing data is now common practice. The use of open vocabularies associated with automated solutions can be a way to improve data quality. Cultural institutions, however, need support to follow this route.
When discussing data quality, participants focused not only on metadata but also on vocabularies. Some participants considered that good quality metadata could be considered as metadata with associate vocabularies providing context to the described objects. Vocabularies are traditionally created and maintained at provider level, but aggregators are also creating list of terms they use to organise the data within their aggregation. However these vocabularies are often not published in ways that will enable other institutions to re-use them.
This is what Linked Open Data teaches us: as highlighted by the speaker Ted Fons in his presentation during the conference, “nobody should own the vocabularies”. When discussing vocabularies:
- Participants agreed that vocabularies should be made open and published in ways that they can be re-used.
- Beyond the “simple” publication aspect, participants also emphasised the fact that linking to existing vocabularies is important.
- Within aggregation infrastructure we should see vocabularies aggregated and aligned in the same way as currently applied to metadata.
- Participants also noted that a technical infrastructure should be in place to support processes, such as the creation of identifiers that point to source vocabularies.
- More importantly the results of this work should then be communicated back to the authority managing the vocabularies.
- The question about the identification of authorities behind vocabularies, or behind an aggregation of vocabularies, has been flagged as an important issue to be addressed.
Europeana supports these principles and encourages providers to deliver richer data, enhancing the data they provide with links to internal or external vocabularies directly[7].
Identifying vocabularies will also help the generalisation of more automatic enrichment solutions which allow the linking between controlled vocabularies and contextual resources in the data. Services such as data.bnf.fror Europeana are linking their data to external Linked Data Vocabularies to get additional semantics where they were missing in the source data. Open source software solutions are being developed to allow semantic enrichment such as the Open Refine NER extension, also mentioned in Ruben Verborgh’s presentation. Named Entity Recognition (NER) allow the automatic recognition of entities in free text, making further linking to external vocabularies easier.
Several participants expressed their faith in NER to improve data quality, as existing tools are getting more and more accurate. The Europeana Newspaper project [9] has used Stanford NER CRF so that they can tolerate very noisy data. Another commonly mentioned tool is DBpedia spotlight. Are there other, better tools?
These tools can vastly improve data quality with the precondition that they don’t add noise on top of the data. As they are based on automatic processes, flaws and errors can be introduced in the data. Most likely, source data could be enriched with data with radically different semantics. That is why the results of such processes should be evaluated. A new EuropeanaTech Task Force is currently working on evaluation methodologies for automatic enrichments and best practices[11] for using such tools.
Participants all agreed that appropriate tools are key for supporting data quality. It is however still difficult to find the appropriate tool for a given use case. Many small companies are developing solutions but they can’t reach cultural heritage institutions.
Participants suggested that Europeana should play a role in acting as a kind of registry to connect small companies or small software providers with cultural heritage institutions. The need for a certain level of trust is key to make this connection.
Need feedback on the data? Think crowdsourcing!
Cultural institutions tend to think about data quality in isolation, however the users of the data may be in the best position to comment on the data and help improving it.
As mentioned earlier, participants highlighted that it is important to have a feedback loop process between providers and aggregators. They also agreed that the feedback from the data consumers is as important.
Data publication highlights data quality issues by making data visible to everyone. It is therefore important to develop ways by which end-users can directly provide feedback on the data. Such crowdsourcing efforts can be really valuable when involving experts in a specific area (also called “niche”). For instance, the SEALINCmedia project has engaged with ornithological experts to help annotating bird prints from the Rijksmuseum with terms coming from a controlled vocabulary[12]. Other initiatives in the Wikimedia community have shown that enthusiasts or amateurs in a specific area can detect errors in data and contribute to its improvement. Participants also suggested that instead of relying on voluntary work we could, for instance, pay people for a session of data tagging. A new business model could be explored around this idea.

Data quality, yes, but for which applications?
The more we expect from data the more likely we are to be disappointed. To avoid this disappointment it is crucial to understand what the purpose of data is and how it changes in different context.
Many discussions also focused on the idea of what “fit for purpose” data means. This raises questions about for whom data is created, and for what kind of applications.
Participants raised the issue that data in cultural heritage is primarily created for internal and descriptive purposes. Data is not necessarily meant to be understood in context other than the knowledge domain it was created in and the purpose for which it has been published. Lots of information is therefore implicit for the professionals who created the data, but becomes less obvious once published within end-users’ applications or interfaces. Participants emphasised the difference between the data created for describing, and data created for finding resources. For them, the purpose of the data is not documented enough, and therefore makes it difficult to assess the degree of quality required to fulfill the requirements of a given application. They also raised the issue that we are not thinking enough about our users, and how they access cultural heritage and discover things.This problem might stem from the fact that there is not enough thought put into the steps following the publication of data which can frustrate cultural heritage institutions.“The responsibility of the data doesn’t end with its publication”.
The quality of the data can therefore be affected by its publication. When metadata becomes open and shared, who is responsible for its quality? The publication of data should be seen as part of the data quality process. Participants insisted on the benefits of creating a true “virtuous circle”. This allows the creators of the data to benefit from the enrichments done before the publication of the data or even after when they get re-used and improved by third-parties. New data can then be re-used to enrich old data or even fill gaps when metadata doesn't even exist. A few projects are looking into the “renewing” or “re-ingesting” curated data, such as the project Europeana Inside. Unfortunately, there are only a few projects working on those aspects and they don’t receive much attention. Providers will be able to see the benefits of this "virtuous circle" only once they see it in their own environment. Participants agreed that projects working on solutions for how to “renew” data should be better featured within the Europeana community. They also recommended that it should be Europeana ‘s role to help cultural institutions to get back and integrate enriched data.
However, we know that working on the source data is a massive task and should be an ongoing effort. Some participants suggested that instead of spending lots of resources on trying to improve data at the source, institutions could focus on the discoverability aspects supported by data and focus on the description of entities such as places, people, and concepts.
Some participants also showed their reluctance to re-use or link to data they don’t know. It is understandable that cultural institutions might still have trust issues when it comes to linking or enriching their data with external datasets. Participants rightly acknowledged the existence of models which could be used to provide information on data provenance and maintenance such as W3C Provenance (PROV-O) ontology[13] or the DCAT vocabulary. A W3C group is also currently working on Best Practices for data on the Web[13] which would have the potential to make the resources available on the Web more trustworthy and ready for re-use by cultural heritage institutions.
So what is good data quality?
By listing the problems and solutions around the concept of good quality data, we start to grasp a little better what it really means. This is no easy task!
Data quality can affect multiple facets of data:
- the quality of knowledge represented in the data can be at stake: data transfer, mapping, and enrichment taking place in our environment can all affect the semantic and the granularity of data.
- the quality of the data structure is usually determined by the standards in place in cultural heritage.
But those principles get blurred as soon as we consider published data.“On the web data quality is a moving target”. The meaning of good data quality will be different depending on the applications using it, on the targeted end-users or even depending on the ranking algorithm used in the services(some applications might be tuned to only show top-quality metadata which won’t be representative of the whole).
The best solution to approach data might be to consider it from a “conformance”, or intention or fit for purpose dimensions. Data quality can be only measured against defined requirements. We have to think about the services we are developing for our end-users and how we want people to access data. Data quality can therefore only be defined according to a particular service a provider or aggregator would like to provide. Data quality could therefore be defined in terms of “access”: the definition of the purpose of the data (its access) and the standard to be used for that purpose. Participants thought it could an interesting Europeana Task Force topic to define what “access” means in different data publication contexts.
What data quality is and what it means is therefore context-dependant. Participants thought that more time should be spent on documenting contexts so that data quality could be measured against them (what will be included, shown, used in/from the data).
We need data quality policies that bring transparency to the expected data. These policies could range from data guidelines, schemas, but also data dissemination plans; as long as they clearly document intentions and are references for data creation.
Good data quality can also be thought of in terms of complementarity. Knowing which datasets can be trusted and used for enrichment would encourage providers and aggregators to use them. It should be Europeana’ s role to facilitate this discussion among the community.
But in conclusion we also know that data quality is not “monolithic”. Datasets can have many layers of quality. Different parts of a given dataset could therefore have different levels of metadata.
We can draw three philosophies about data quality from all the discussions that took place at the conference:
- Participants agreed on the fact that we should accept any data and define it as good quality as long as it is consistent: “weird is okay if it’s consistently weird”.
- Accept the data as they come and try to make the most of it (even if you still try to enhance it) as described by the speaker Andy Neale from DigitalNZ.
- Rather than spend time and effort trying to achieve better data quality, take advantage of the activities that poor data quality generates such as crowdsourcing enrichment and tagging, as illustrated by Tim Sherratt[15].
References:
[1] Europeana Strategy 2015-2020 at http://strategy2020.europeana.eu/
[2]Papatheodorou, Christos Phil Carlisle, Christian Ertmann-Christiansen and Kate Fernie. (2011). The CARARE schema, version 1.1. http://www.carare.eu/eng/Resources/CARAREDocumentation/CARARE-metadata-schema
[3] Europeana Data Model (EDM) documentationhttp://pro.europeana.eu/share-your-data/data-guidelines/edm-documentation
[4]Reference model for an open archival information system (OAIS) http://public.ccsds.org/publications/archive/650x0m2.pdf
[5]The Synergy reference model for data provision and aggregation. Draft June 2014. http://www.cidoc-crm.org/docs/SRM_v0.1.pdf
[6]Presentation on the Geolocalisation enrichment tool http://www.slideshare.net/locloud/locloud-geocoding-application-runar-bergheim-asplan-viak-internet
[7] Europeana enriches its data with AAT. http://pro.europeana.eu/share-your-data/data-guidelines/edm-case-studies/europeana-aat
[8] Report of multilingual and semantic enrichment strategy http://pro.europeana.eu/get-involved/europeana-tech/europeanatech-task-forces/multilingual-and-semantic-enrichment-strategy
[9] Named Entity Recognition for digitised newspapershttp://www.europeana-newspapers.eu/named-entity-recognition-for-digitised-newspapers/
[10] FLOSS available at http://pro.europeana.eu/get-involved/europeana-tech/floss-inventory
[11] Task Force on Evaluations and enrichments http://pro.europeana.eu/get-involved/europeana-tech/europeanatech-task-forces/evaluation-and-enrichments
[12] Linking Birds: Converting the IOC World Bird List to RDF http://wm.cs.vu.nl/blogs/linking-birds-converting-the-ioc-world-bird-list-to-rdf/
[13] Cultural Heritage institutions re-ingesting enriched metadata http://pro.europeana.eu/post/cultural-heritage-institutions-re-ingesting-enriched-metadata
[14] Data on the Web Best Practices. W3C Editor's Draft 29 January 2015 http://w3c.github.io/dwbp/bp.html
[15] Myths, mega-projects and making http://discontents.com.au/myths-mega-projects-and-making/