Text Mining #3: Europeana for Quantitative Literary History
Guest Blog Post by Christof Schöch, Departement for Literary Computing, University of Würzburg
Over the last several years, there has been an increasing interest in large-scale, computational, quantitative investigations into European literary history. Scholars working on texts from many different European literary traditions are using tools and services from computational linguistics, adapting methods from computer science and statistics, and developing new tools and methods for their research. They work on attributing texts of unknown or uncertain authorship to their actual authors (in the field called stylometry), they attempt to retrace the fate of particular phrases and ideas across the centuries (in text-reuse studies), they explore the distributions across genres and the evolution over time of thematic trends (using methods such as topic modeling), or they investigate the stylistic and structural commonalities of authors, literary genres or literary periods. What is common to all of these approaches is their reliance on large amounts of freely available textual data.
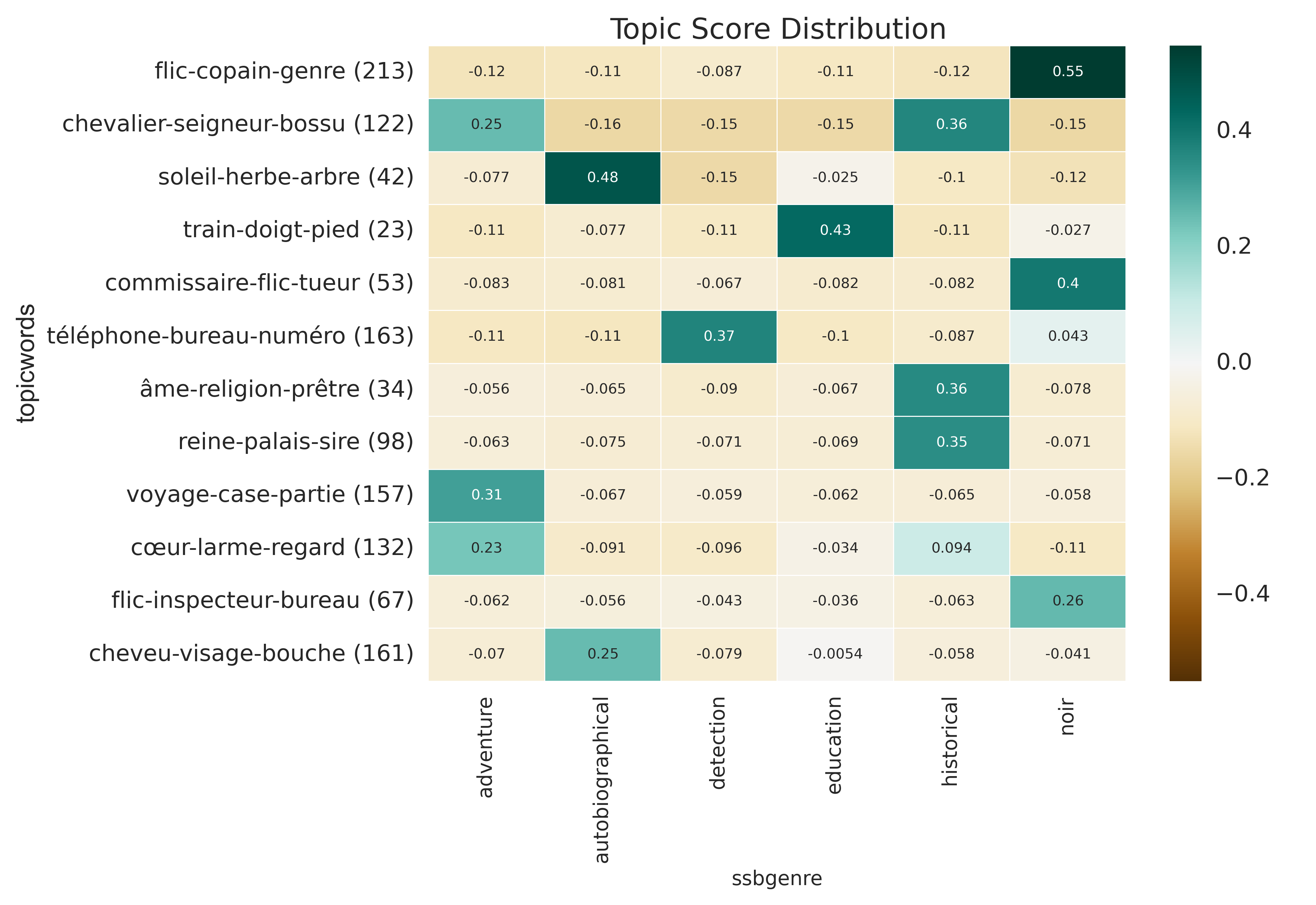
Figure 1: This graph shows the distribution of a selection of topics in a collection of several hundreds of French novels of different types. The heatmap has been generated using topic modeling coupled with metadata about the subgenre each novels falls into. Such techniques allow new insights into the distribution of themes and motives in literary history.
This last point can hardly be overstated: Without texts, lots of texts, quantitative literary history just doesn't work and won't get anywhere. And while literary studies as a field has invested generations worth of effort into creating reliable witnesses of the literary tradition and establishing detailed information about authors and texts, most of this valuable information is not available in digital form and can therefore not be used at the scale required for quantitative literary history. From the perspective of such research, libraries with their millions of books seem like the wardens of enticingly large amounts of excruciatingly inaccessible data. Many libraries have understood this a long time ago and have been working towards making their rich holdings more accessible and more useful. But this is not an easy task and there is still a lot of work to do.
What, then, would be the most urgent and most useful from the perspective of quantitative literary history? In fact, it seems there are three key requirements: First, large amounts of relevant, semi-structured, reliable textual data. Second, rich, detailed, relevant metadata. And third, the technical and legal availability of the data and metadata.
Regarding the first requirement, relevant, semi-structured, reliable texts: Data needs to be relevant from the perspective of literary history, that is consist of texts generally assumed to belong to the realm of literary texts, in a broad but meaningful sense of the term. Data needs to be available in a semi-structured, open and standardized format. The de facto standard of the Text Encoding Initiative (TEI) comes to mind because of its ability to make major structural divisions (such as parts, chapters and paragraphs) as well as fundamental local phenomena (such as person or place names or quotations and direct speech) explicit.
Also, texts need to be reliable in the sense of presenting a level of accuracy with regards to the print sources which is sufficient for quantitative methods (what that level is, remains open to debate) and those sources themselves need to be reliable texts. It is a problem that quantitative investigations into literary history frequently use the latest statistical methods but need to rely on texts which have been established a century ago at best, cutting this research off from the state of the art in textual criticism.
As for the second requirement: Metadata needs to be relevant to literary history, which basically means it is not just the author, title, place and date of publication of a document that are needed. When working with large amounts of text, even characteristics of texts which would be obvious to a human reader need to be made explicit in machine-readable form. For this reason, texts need to be described with regard to fundamental categories such as their form (proportions of prose and verse, for instance), the languages used (often, more than one language is used in literary texts) and their broad genre category (the Dewey classification would be a somewhat useful start, distinguishing poetry, drama, fiction, essays, speeches, letters, humor & satire, and miscellaneous writings).
Anything more detailed would be a huge challenge for the library world and for literary historians: Without consensus on fundamental categories in literary studies, it will be very difficult to enable librarians to add such metadata to their holdings. But for relatively clear and simple categories, tools could be built that will help detect them automatically from the full texts. In comparison with this challenge, the technical question of the best format and standard for metadata becomes almost secondary: XML (TEI or METS), CSV or JSON will be just fine.
The third requirement regards the technical and legal availability of the data and metadata: For quantitative literary history, large amounts of data are key and being able to run customized routines for linguistic annotation and statistical analysis is just as important. As a consequence, convenient ways of downloading the data and associated metadata in bulk are essential. The legal requirements are those routinely associated with "open data", that is, researchers need to have the right to access, download, store, modify, merge, analyse and republish the data and metadata. The last point, republishing the data, is sometimes neglected but actually crucial, because it allows documenting one's own research more fully and making it transparent as well as reproducible.
While Europeana generally focuses on aggregating metadata from their many partner institutions, Europeana Research's initiative to gather specific thematic collections of data and provide those as full datasets is very welcome in the context described here. The datasets are large, can easily be downloaded, have permissive licenses, and include metadata. However, there are still very few of these datasets and even fewer of them contain literary texts. The current newspaper archives use unstructured text formats, have problematic levels of OCR quality for anything other than keyword search, and the metadata are doubtless reliable but relatively superficial.
There appear to be two avenues for increased use of digital library holdings by literary historians: the first avenue would be for librarians and literary historians to team up and build more and even richer collections than the ones already offered through Europeana Research, collections such as "1001 French Nineteenth-century Plays" or "2000 Italian Sonnets".
The second avenue would be to build machine learning algorithms which are trained to add some of the metadata relevant to literary historians to Europeana's holdings, so that for any full-text made discoverable through Europeana, researchers can also find out whether, for instance it is a play or a collection of poems, written in prose or in verse. Besides funding of such activities, the key challenge will no doubt be to bring the library and research communities closer together in order to make the most of the hidden digital treasures available through libraries across Europe.