Opening Up Google Books
Like explorers cutting through the jungle, so digital humanists continue to slice through swathes of large sources of data, the so called 'big data'.
Some resources are already fully open online, in all sense of the words. The recent publication of transcribed data from The Text Creation Partnership on early English language texts is a great example.
But many mass digitisation datasets are not quite as open, meaning they cannot be used in for text and data mining.
As probably the largest textual dataset in the world, the Google corpus of digitised books is perhaps the most interesting for re-use in the digital humanities.
As a tool for simple discovery, allowing anyone to search through the OCRd text of over 30m books, even scholarship’s most profound opponent of technology cannot fail to make use of Google Book Search.
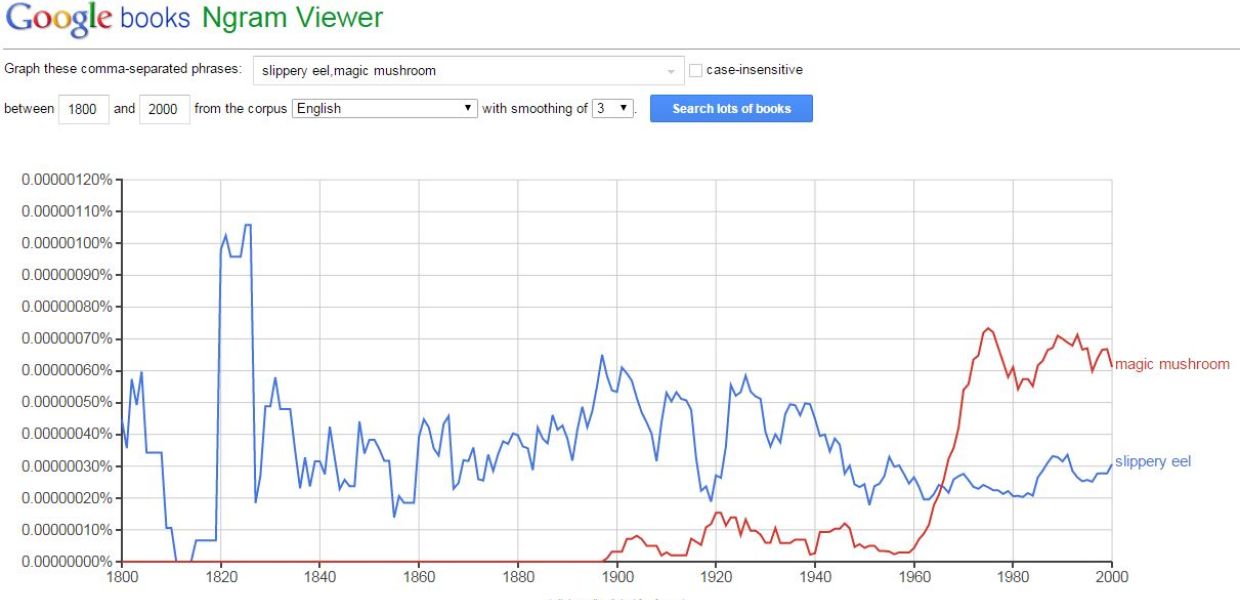
Building on this, the Google n-gram viewer allows users to see the frequency of words across some of it corpus (although not all languages are included). More recent versions of the n-gram viewer have improved the functionality, allowing for searches including distinction between upper and lower case, and using wildcards.
Google has also made the n-grams available from certain languages within the corpus so they can be downloaded for offline use (with a CC-BY licence). These aren't the indices of the books but extracted keywords from the corpus. So the 2 gram index features (and counts) all instance of phrases with two words, eg "slippery eel" or "magic mushroom".
The availability of both this viewer and the data has provoked some new strands of scholarship, most notably the Cultronomics movement instigated at Harvard and Princeton (See one of their early papers here) It should be noted that criticism of this approach has already begun. A 2015 paper pointed out some of the flaws with drawing too many conclusions from the Google corpus, particularly as there was no related metadata to know what was precisely in each n-gram index
But what Google doesn't do is allow bulk access to the original OCRd text. You can get the plain text OCR to a single page or group of pages, and a pdf or sometimes an ePub of the whole text. But if you want to get easy access to the all the text for multiple books, it can't be done. The complex jungle of licensing restrictions means this can't happen.
The two existing APIs for Google Books allow third parties to embed the search functionality and the image viewer on other websites. Indeed some of the libraries that contributed books to the digitisation project make use of the APIs to show their Google books on their library catalogues. But, again, these do not provide access to multiple full texts that are required for text mining.
Within the US, the Hathi Trust (the library consortium) and in particular the related Hathi Trust Research Center (HTRC) are addressing this issue. As cited on their home page, the HTRC are building capability for analysing the public domain and in-copyright books at scale.
Having aggregated many digitised books from US libraries - including the US libraries who were part of the Google books program - the Research Center is now in a position to allow authenticated access to the collected dataset, allowing researchers to run algorithms over it.
But there doesn't exist a similar organisation in Europe. Many libraries have digitised shelves and shelves of their collections, but there is currently no systematic way at a European level to release this data for research throughout the research community. There are numerous interested stakeholders - researchers, aggregators, the libraries, politicians and policy groups and Google itself of course.
So, here we have one of the first strategic issues that Europeana Research can help tackle. How do we liberate this data for research?
(With thanks to Steven Clayssens, KB NL Research)