Text Mining #1: Extending the method toolbox: text mining for social science and humanities research
Guest Blog Post by Gregor Wiedemann, Natural Language Processing Group, University of Leipzig, gregor.wiedemann@uni-leipzig.de
Qualitative and quantitative aspects of text as data
Text as data for research in social science and the humanities has been a hot issue in methodological debates for decades. Interest in large quantities of text started with investigations especially of propaganda in press coverage of hostile countries during the first half of the 20th century. Early attempts simply manually counted columns and lines, or directly measured areas of text coverage on single pages related to a certain topic. Later on, in the late 1960s, since computers were able to assist researchers doing word counts in large quantities of text, media scientists started to base their quantifications on more fine grained categories involving the actual text. But at that time, researchers with more qualitative focus already began to separate themselves from the “quants”. They were keen to generate a real understanding on how meaning was constructed via discourse, thus focusing on close reading and analyzing small quantities of text representing distinct and paradigmatic cases. Method debates from both sides successfully sought to draw clear distinctions between the qualitative and the quantitative paradigm.
For a few years now, this divide on how to approach qualitative data is questioned. Social scientists, for example, engage in mixed method research projects and discourse analysts start to realize that their subject always incorporates a quantitative perspective at least indirectly. On the one hand, this is a consequence from the increased availability of digital sources—born digital during the web era or made available as retro-digitized documents by galleries, archives, libraries and museums. On the other hand, nowadays text analysis technologies from Natural Language Processing (NLP) contribute to reconcile qualitative aspects of semantic meaning with quantitative aspects of their relevance.
Types of computational text analysis
To better understand the development of computational text analysis and what is “new” in the situation nowadays, a typology highlighting specific aspects of analysis technology is helpful. As shown in Figure 1, I distinguish four types [1]:
- computational content analysis (CCA),
- computer-assisted qualitative data analysis (cQDA),
- lexicometrics / corpus linguistics, and
- machine learning.
I refer to the latter both also as “text mining”, since they enable us to reveal (previously unknown) patterns of meaning in very large corpora automatically.
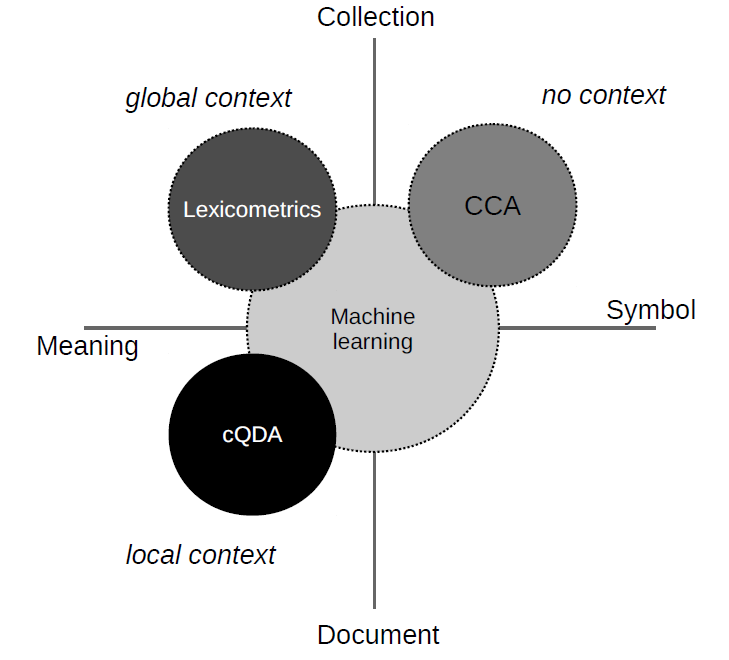
Figure 1: Types of computational text analysis.
These types differ in their applicability to varying quantities of data and in their ability to extract structures of meaning from text. Since word meaning can be perceived as a function on its contexts (or as J. Firth has stated “You shall know a word by the company it keeps”), consideration of context is crucial for distinguishing types of computational text analysis.
Since the 1960s CCA has focused on counting of keywords and lists of keywords (also known as dictionaries). While this can be applied easily to large quantities of text, due to the isolated observation of single terms, it lacks context to a large extent.
The emerging current of qualitative research answered to this lack of understanding by developing methods of qualitative data analysis (QDA), supported since the 1980s by gradually evolving software for document management and coding. In computer-assisted QDA Programs such as MAXQDA or Atlas.ti guide researchers through the process of analysis and interpretation of small document sets.
Also during the 1980s, especially in the Francophone research community, the utilization of corpus linguistics, also called lexicometrics became prevalent. Lexicometric analysis such as key term extraction and collocation analysis model context of language use in a global manner, retrieved from statistical observations in large corpora. During the 1990s and 2000s, it slowly spread into social sciences via integration with (Critical) Discourse Analysis.
Consideration of context in the most recent type, Machine Learning (ML), resides in a crucial intermediate position between the other three types: ML works on the basis of local context by observing co-text in single documents or smaller sequences (e.g. sentences). Through aggregation and joint observation of multiple documents, knowledge conceivable only on the collection-level is learned and incorporated into model instances representing global context. At the same time, learned global knowledge again is applied on individual documents, e.g. by assigning globally learned categories to individual instances. In consequence, the computational representations of meaning of the latter both types allow for qualitative and quantitative insights into text collections which could not be acquired by the isolated observation of single documents alone.
Apparently, there is no single best method of computational text analysis. Methods should meet requirements from the analyst’s perspective and might be operationalized in manifold ways. Greatest benefits can be expected from systematic combinations of several approaches of the aforementioned types [2, 3].
Different requirements: Linguistic vs. social science collections
Text mining using both, lexicometrics and machine learning, enormously can contribute to reveal semantic structures, differences of meaning between (sub-)collections, changes of meaning over time, correlations between text external observations and many interesting things more from large collections which could not be revealed by purely manual approaches. Nonetheless, human interpretation is not replaced by “machine intelligence”. In contrast, the algorithmic approaches are only tools to make patterns visible buried in large data sets and provide measures of their quantitative prevalence. Still, meaning has to be constructed from such “new” kinds of data by the analyst.
Hereby, a distinction between analysis goals for linguistic or social science purposes is useful. Linguists, who have been accustomed to the use corpus linguistic methods for decades already, strive for revealing patterns in language use to infer statements on language as their matter of research. Social scientists, in contrast, apply text mining to identify discourse patterns striving for statements on social reality. For them, language analysis is not an end in itself, but a window to look through to study societal phenomena.
Both perspectives have severe consequences for requirements on language collections as subjects of analysis. While corpora for linguistics need to be representative for certain language user communities, corpora for social science need to be representative for social communities and their (public) discourse to support valid research. Unfortunately, up to now most digital corpus resources in the field of DH were created having linguistic and philological purposes in mind. Linguists usually are content with sets of well-formed sentences, while social scientists work on document contexts mostly. Also, collections for social science need to be rather complete, instead of just medium-sized samples, to enable researchers to dig into specific events. For instance, a complete collection of volumes of a newspaper consisting of millions of documents quickly reduces to several thousand or even only hundreds of articles when filtered to a specific topic of interest. This implies that corpora need to be accessible to be sliced into smaller pieces, either by metadata (e.g. certain authors) or by thematic selections (e.g. key word searches). For this, data management infrastructures for large collections need to provide access to full archives via well maintained source information allowing for attribution of authorship or publishers and well curated metadata in general [4].
Unfortunately, these conditions are not met by many popular large collections. The Google Ngram Corpus, for example, provides valuable resources for linguistic research and certainly contains documents of interest for social science as well. Nonetheless, obscure background information of its composition and lack of control to filter for sub collections makes it pretty useless in social science scenarios. Luckily, the data availability situation for content analysis is improving since more and more collections, e.g. of complete newspaper volumes covering decades of public discourse, become available for research purposes (e.g. the German “DDR-Pressekorpus” provides a collection of three GDR newspapers covering more than forty years of news coverage). Equipped with such big data sets of stable quality and levels of representativeness over long periods of time, text mining truly may become a valuable extension of the toolbox of contemporary historians and social scientists. Their methodological debate is likely to accelerate, once they are provided with more collections curated in such way. Moreover, there is a need for interdisciplinary reflection on technical realizations and application of research infrastructures to enable scientists to make use of text mining efficiently… but that’s another story on its own.
Further readings
[1] A more elaborated description of these types can be found in this article: Wiedemann, Gregor (2013). Opening up to Big Data: Computer-Assisted Analysis of Textual Data in Social Sciences. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 14(2), Art. 13.
[2] A systematic and integrated application of information retrieval, lexicometrics and machine learning for a political science task is sketched in this article: Lemke, Matthias; Niekler, Andreas; Schaal, Gary S.; Wiedemann, Gregor (2015): Content analysis between quality and quantity. Fulfilling blended-reading requirements for the social sciences with a scalable text mining infrastructure. In: Datenbank-Spektrum 15 (1), S. 7–14.
[3] Use cases and methodological considerations will also be published in November 2015 in Lemke, Matthias; Wiedemann, Gregor (Hg.) (2015): Text Mining in den Sozialwissenschaften. Grundlagen und Anwendungen zwischen qualitativer und quantitativer Diskursanalyse. Wiesbaden: Springer VS.
[4] An example of a text mining infrastructure for social scientists as primary intended user group is the “Leipzig Corpus Miner” which is introduced in detail in: Niekler, Andreas; Wiedemann, Gregor; Heyer, Gerhard (2014): Leipzig Corpus Miner. A Text Mining Infrastructure for Qualitative Data Analysis. In: Terminology and Knowledge Engineering (TKE '14).