This website uses cookies to ensure you get the best experience. By clicking or navigating the site you agree to allow our collection of information through cookies. Check our Privacy policy.
For years SWIB has been an important gathering for the EuropeanaTech community with community members always present both on stage and behind the scenes programming the event. 2017 was no exception and EuropeanaTech has taken the chance to highlight several topics presented at the event in this issue of EuropeanaTech Insight.
As a testament to SWIB's importance and the increase in knowledge sharing and transnational collaboration, there are several cross-paper connections we'd like to highlight that occur within this issue of Insight.
This special SWIB issue of EuropeanaTech Insight sees articles from Fedora, Netwerk Digitaal Erfgoed, The University of Illinois Urbana-Champaign, Finnish National Library and the German National Library of Science and Technology (TIB). It’s becoming clearer that LOD is not just being seen as a librarian and information specialists tool for experimentation but true value is being derived from this work enriching user experiences and collection contextualization. As more platforms work to integrate LOD as the standard we can only imagine what use cases and valorizations we’ll see at SWIB 2018.
Integrating data from distributed sources via lookup services
Tatiana Walther, Christian Hauschke; German National Library of Science and Technology (TIB) Hannover
Introduction
Currently global efforts are being undertaken in librarian, cultural and scientific context to make data interoperable and interlinked. The importance of applications and services, which can enable comfortable data integration, has risen.
Descriptive and subject cataloguing can benefit from the use of external controlled vocabularies and thesauri, preferably in Resource Description Framework (RDF). This data is either accessible on the web via various Application Programming Interfaces (APIs) or stored in data dumps.
In this article, we describe an extension of lookup services in the research information system software VIVO, which can be applied for integration of external distributed data - e.g. concepts from subject authorities, available on the web. The integration of non-concepts is planned as well. The lookup service utilizes SPARQL Protocol and RDF Query Language (SPARQL) endpoints, Representational State Transfer (REST) API and the Skosmos tool as a middleware. The extension has been developed at the German National Library of Science and Technology (TIB) Hannover.
Motivation and Goal
VIVO is an open source software, developed at the Cornell University Library. It uses Linked Data technologies and standards, as e. g. RDF, Resource Description Framework Schema (RDFS), SPARQL, Web Ontology Language (OWL), and Simple Knowledge Organization System (SKOS). As a research information system VIVO is generally used to represent scholarly activities of one or more institutions on the Web [1]. A typical installation covers profiles of persons connected with organizations, publications, projects etc.
VIVO delivers a set of default vocabularies, e. g. the Library of Congress Subject Headings (LCSH) to assign concepts as annotations to various information items. Regarding the integration of concepts for subject cataloguing, the aforementioned authorities were not sufficient to fulfill the needs of librarians and end users (mainly scientists) using VIVO. Extending these services is also necessary due to a new and increasingly important reporting standard for research information in Germany – the Research Core Dataset (Kerndatensatz Forschung, KDSF), which determines the use of the „Destatis Fächersystematik“ (Subject Classification of the German Federal Office of Statistics) for assigning subject annotations. To record data in VIVO in conformity with the KDSF we also had to integrate this vocabulary into VIVO.
Either manual or semi-automatic collecting, enriching and converting of a larger amount of concepts or other objects costs a lot of time and resources.
Thus, the objective of our project was to extend the scope of external vocabularies and other bibliographic sources in VIVO, integrated via lookup services.
Implementation
As a pilot we implemented two subject authorities. Besides the „Destatis Fächersystematik“, we opted for the Standard Thesaurus for Economics (Standard Thesaurus Wirtschaft, STW). Integration of non-SKOS data collections is still being planned.
The „Destatis Fächersystematik“ was initially available in a non-machine readable file. We used Skosmos as a means to provide access to the vocabulary for human users and machines alike. Integrating „Destatis Fächersystematik“ in Skosmos and VIVO required conversion to a concept scheme in SKOS, which was done by means of OpenRefine. Subsequently, we have further processed the vocabulary with Skosify [3] for Skosmos to fully interprete the vocabulary, which results in additional features. The STW was already available in SKOS and equipped with a publicly available SPARQL endpoint. Therefore no middleware was required.
Setting up the lookup service involved some work on several Java configuration files.
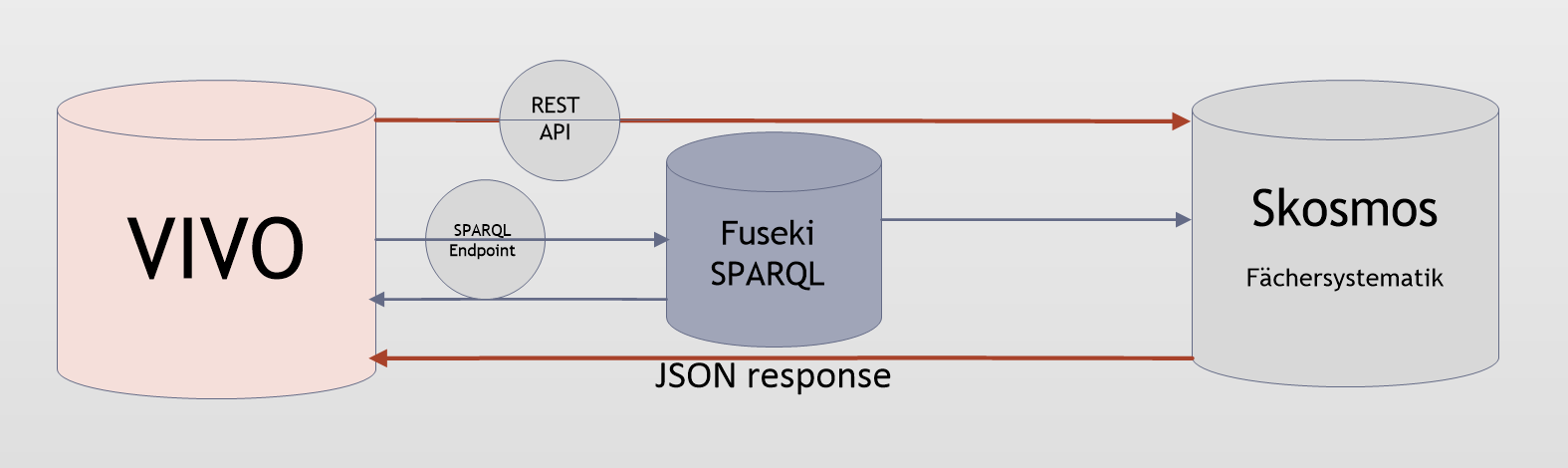
Figure 1: Integration of "Destatis Fächersystematik" from Skosmos into VIVO.
As figure 1 represents, to integrate the Destatis Fächersystematik, we utilized a REST API provided by Skosmos, which offers a SPARQL Endpoint as well. When using the REST API, VIVO sends a request as a URL to the interface of Skosmos. It receives a response in JavaScript Object Notation (JSON) form, which is further processed locally.
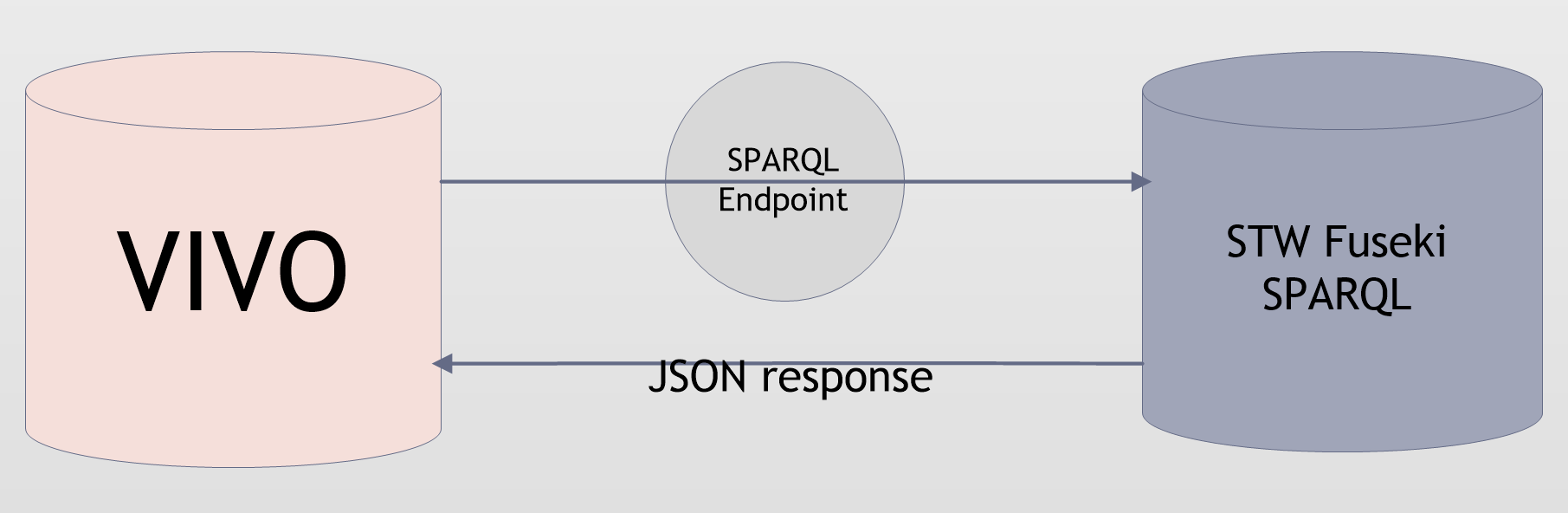
Figure 2: Integration of STW into VIVO
In the case of STW, as outlined in figure 2, VIVO communicates with a SPARQL endpoint. VIVO sends a SPARQL query and receives a response in JSON form as well. We chose to try both alternatives to learn about different ways to integrate vocabularies.
Functioning
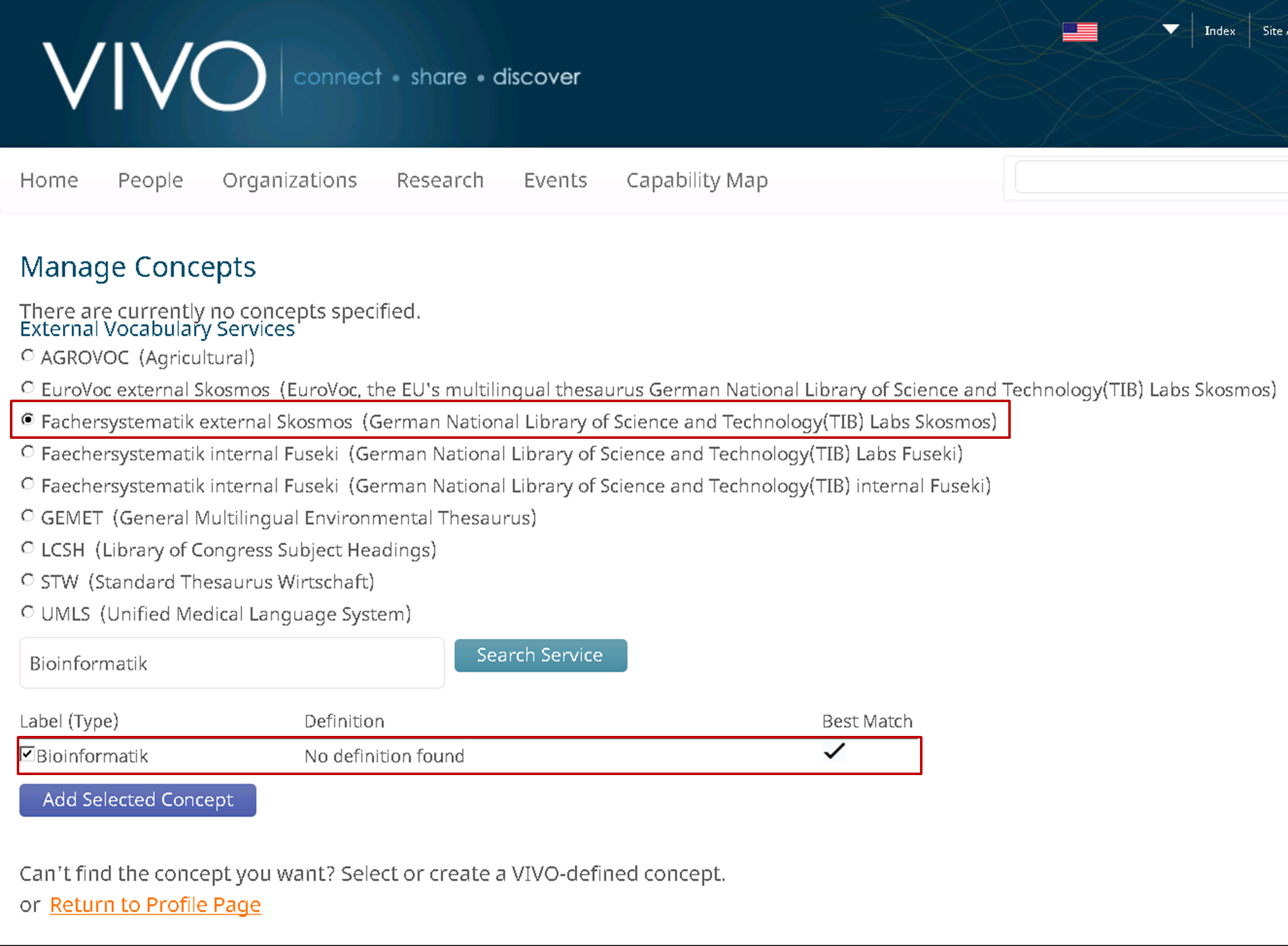
Figure 3 shows handling with concepts from external authorities in the user interface. In the list of vocabulary services a user can now select one of the new vocabularies. After a requested term has been typed in the search form it is sent to the selected service. The targeted application checks, if there are any concepts with preferred labels (as for now defined in the configuration file, other settings are possible, too) matching the searched term and sends the response.
Figure 3: User interface for managing concepts from external sources in VIVO
The result is a list of suggested terms with the best matching concept denoted. The user is now able to add the selected concept to his profile.
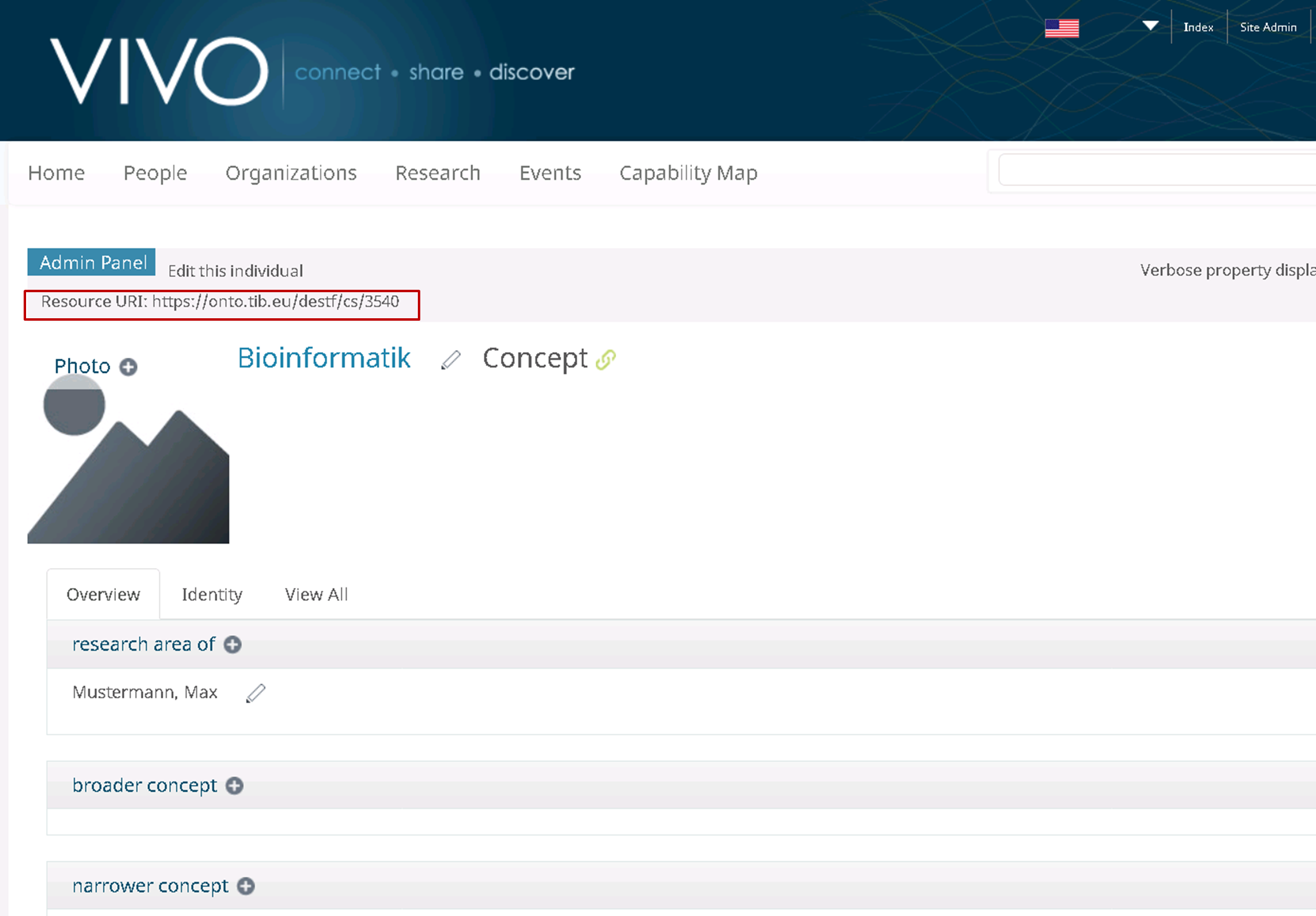
Figure 4: A profile page of the new integrated concept in VIVO
Concurrently a profile page for the concept, shown in figure 4, is being automatically created. The concept preserves its United Resource Identifier (URI) from the external authority, and its metadata, if available, as well.
Conclusion
The lookup service presented here is reliable and meets our expectations of building an infrastructure for vocabularies to be used in VIVO – and other systems, of course. Nevertheless, further conceptual and technical work is necessary to deal with changes in the vocabulary used. In terms of content, the next challenge is to integrate non-SKOS entities from such sources as Wikidata and the Integrated Authority File of the German National Library (GND) [4], which requires mapping models, normalization of data and disambiguation processes in the background. A significant work in this area was done in the scope of Linked Data For Libraries (LD4L) project (see also [5]). A generic user friendly interface for lookup services is another goal to be achieved. Thus, further developments and improvements of the existing lookup services in VIVO to make them more generic and applicable are required.
[2] O. Suominen, H. Ylikotila, S. Pessala, M. Lappalainen, M. Frosterus, J. Tuominen, T. Baker, C. Caracciolo and A. Retterath, "Publishing SKOS vocabularies with Skosmos. Manuscript submitted for review," 2015.
[3] O. Suominen and E. Hyvönen, "Improving the Quality of SKOS Vocabularies with Skosify," in Knowledge Engineering and Knowledge Management : 18th International Conference, EKAW 2012, Galway City, Ireland, October 8-12, 2012. Proceedings, 2012.
[4] T. Walther and M. Barber, "Integrating Data From Distributed Sources Via Lookup Services," 18 December 2017. [Online]. Available: https://doi.org/10.5281/zenodo....
[5] H. Khan and E. L. Rayle, "Linking the Data: Building Effective Authority and Identity Lookup," 2017. [Online]. Available: https://wiki.duraspace.org/dis....
Finnish National Bibliography Fennica as Linked Data
Osma Suominen, National Library of Finland
Introduction
The National Bibliography Fennica is a database of Finnish publications maintained by the National Library of Finland. Fennica contains metadata on Finnish books (since 1488), serials including journals (since 1771), maps (since the 1540s) as well as digitised collections and electronic books. It has been published as linked open data using the CC0 license, which allows free use for any purpose, for example in applications or data visualisations.
In order for libraries to stay relevant in the modern world they need to share their data on the web. Producing Linked Data is a great way of finding and correcting quality issues in the data and an opportunity to make it more interoperable. As an institution, we are also building competence for the future by expressing our bibliographic data in a more modern entity-based data model, so that we are better prepared when the MARC format is eventually replaced by newer metadata models.
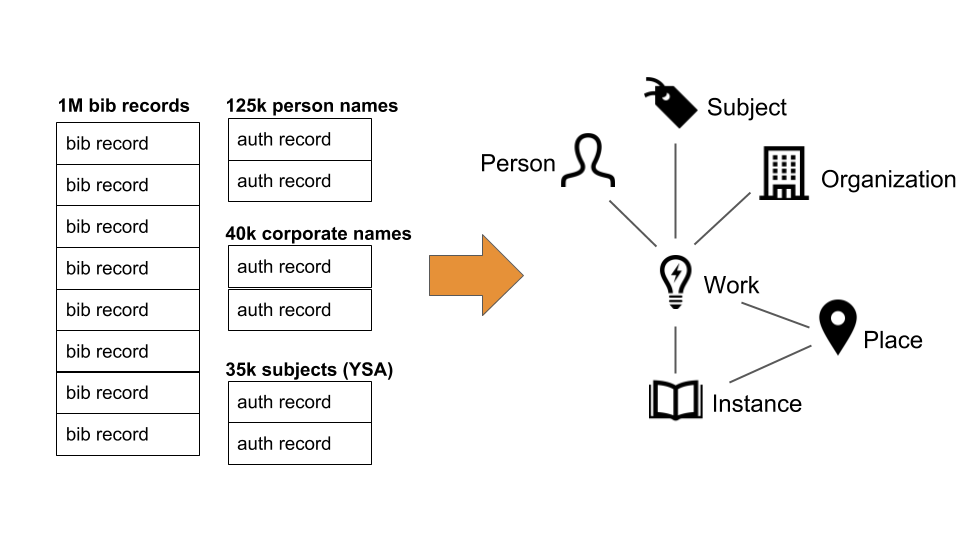
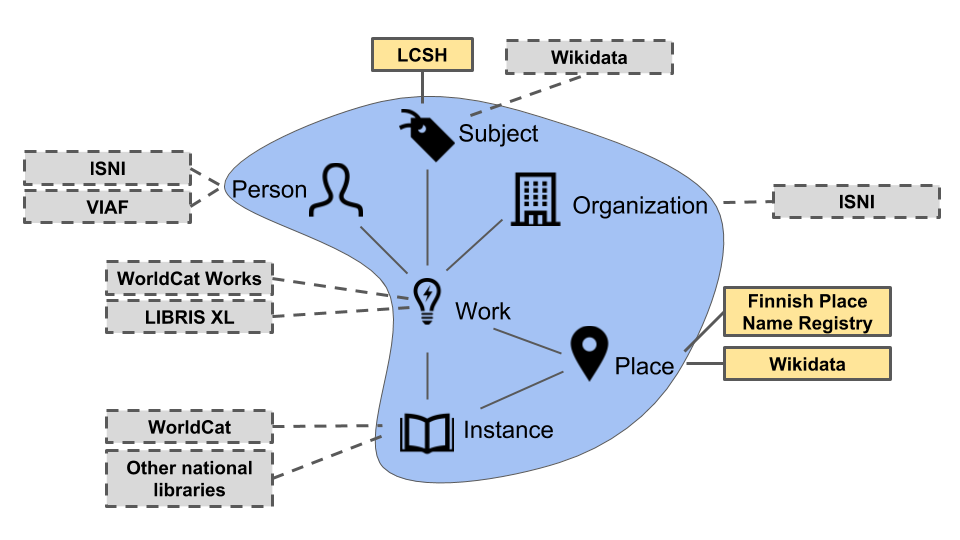
We started with 1 million bibliographic records from Fennica, as well as 200,000 subject, person and corporate name authority records. We turned those records into a graph of interconnected entities: works, instances, persons, subjects, organizations and places (Figure 1). This is not a straightforward mapping, since a bibliographic record may contain information about many different entities and a lot of the information, especially concerning the relationships between entities, which is implicit in the structure of the records.
Figure 1. Overview of the conversion from MARC records into linked entities.
Data model
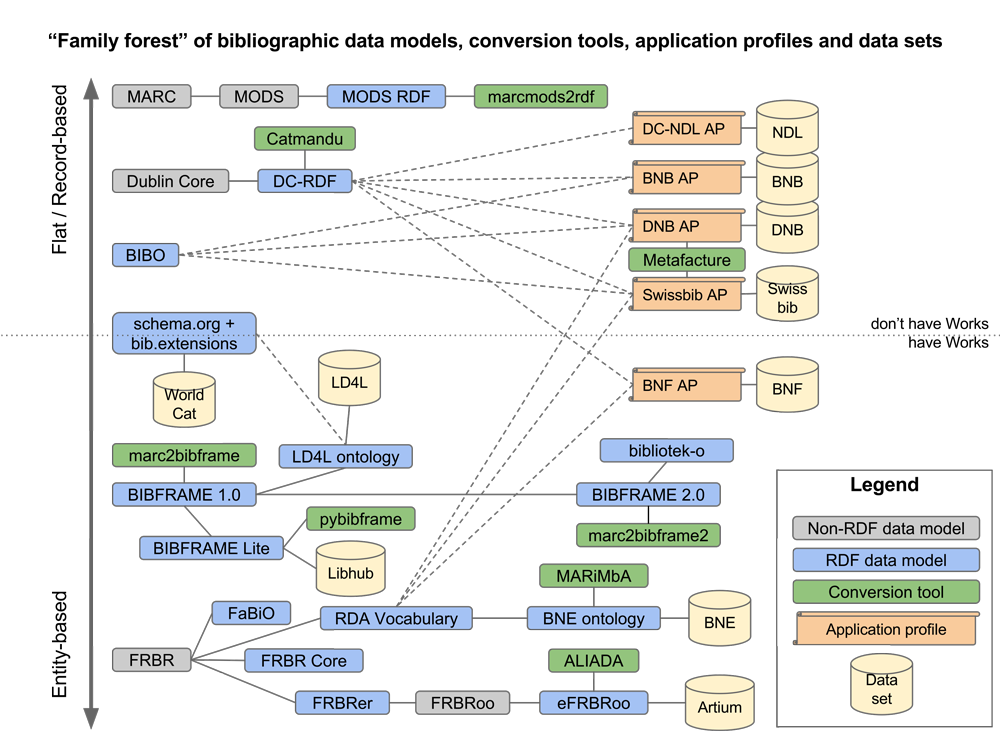
Before deciding on the data model to use, we researched how other libraries have approached the challenge. We found out that all of them had chosen different data modelling approaches. Interoperability was limited because the structure of their datasets was very different. An overview of the different data models is shown in Figure 2. The findings and the figure were presented in a paper “From MARC silos to Linked Data silos?”.
Figure 2. Variety of data models for publishing bibliographic metadata as Linked Data.
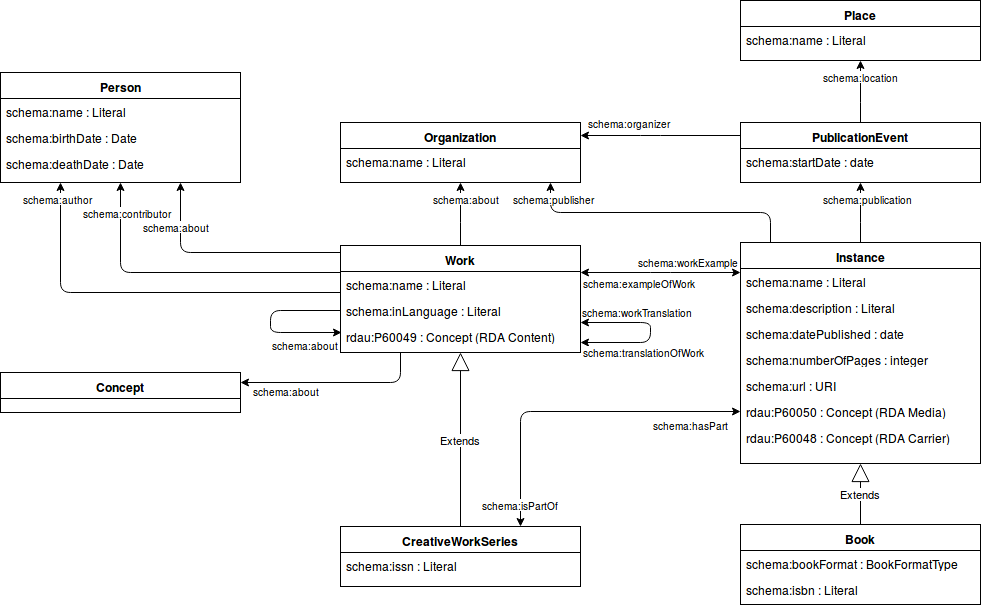
Based on the review of different data models used by libraries for exposing their bibliographic metadata as Linked Data, we found that the Schema.org data model would work well for our purposes. Schema.org allows describing resources from a common sense, Web user perspective. But instead of just converting each MARC record into a single Schema.org resource, we decided to separate out the work entities from instances, in the sense of the BIBFRAME data model. This way, different editions of the same work, such as printed books and e-books, will be connected to the same work entity. An overview of our data model is shown in Figure 3.
Figure 3. Data model for Fennica Linked Data.
Conversion from MARC to Linked Data
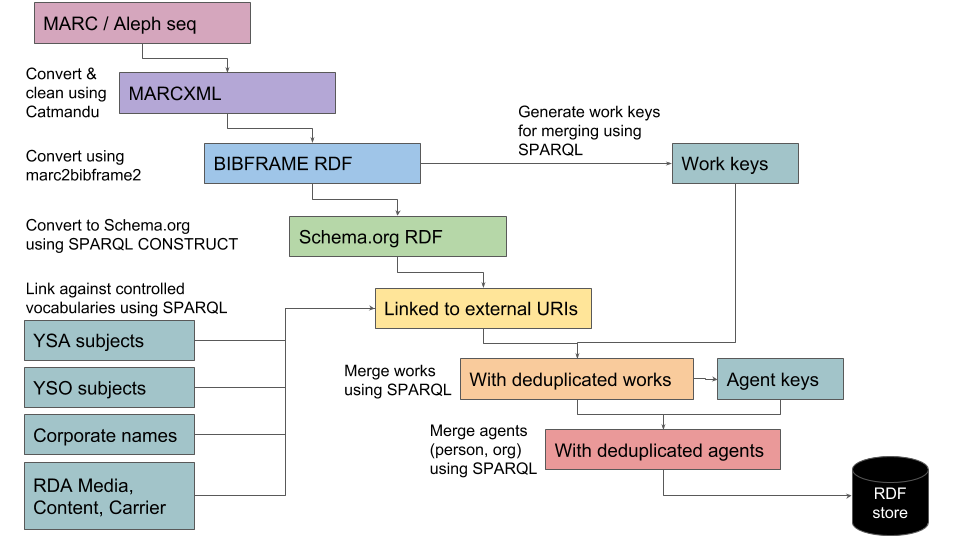
We first surveyed the available tools for conversion of MARC to RDF. Although there are many good tools, none of them could handle the whole conversion process. Thus, instead of relying on a single tool, we created a pipeline that combines existing tools (Figure 4).
Figure 4. Pipeline that converts MARC records to Linked Data.
The pipeline starts with a dump of MARC bibliographic records from the Aleph ILS. We first clean up the records and convert them into MARCXML syntax using the Catmandu toolkit. Then we convert the MARC records into BIBFRAME 2.0 RDF using the marc2bibframe2 tool developed by the Library of Congress and Index Data. The result is a fairly verbose RDF data set with a lot of internal duplication. It also doesn’t have the correct entity URIs we would like to reference. But since the data is expressed in RDF, we can use RDF based tools such as SPARQL queries to further refine it.
We convert the BIBFRAME data into basic Schema.org using a SPARQL CONSTRUCT query, and link that with external data sets using another SPARQL query. This includes SKOS data sets such as the General Finnish Ontology YSO, the Finnish Corporate Names authority file, and some RDA vocabularies.
Clustering works
To extract works and bring together instances of the same work, we rely on a process similar to the FRBR Work-Set algorithm. First, using SPARQL, we generate key strings for works based on, e.g., title/author combinations and uniform titles. Then we merge work entities that share the same keys. The result is not perfect: in many cases, the algorithm fails to merge works that should be merged, because the metadata is incomplete or expressed differently in different records. The algorithmic clustering of works could in the future be used as a basis for a work authority file where works are curated manually, in order to support true RDA cataloguing.
Linking to other data sets
Currently subjects are linked to LCSH and places are linked to the Finnish Place Name Registry and Wikidata (Figure 5). We are making plans to link persons and organizations to ISNI and/or VIAF, and the works and instances to other bibliographic databases.
Figure 5. Current and potential linking targets for Fennica Linked Data. Publishing the data set
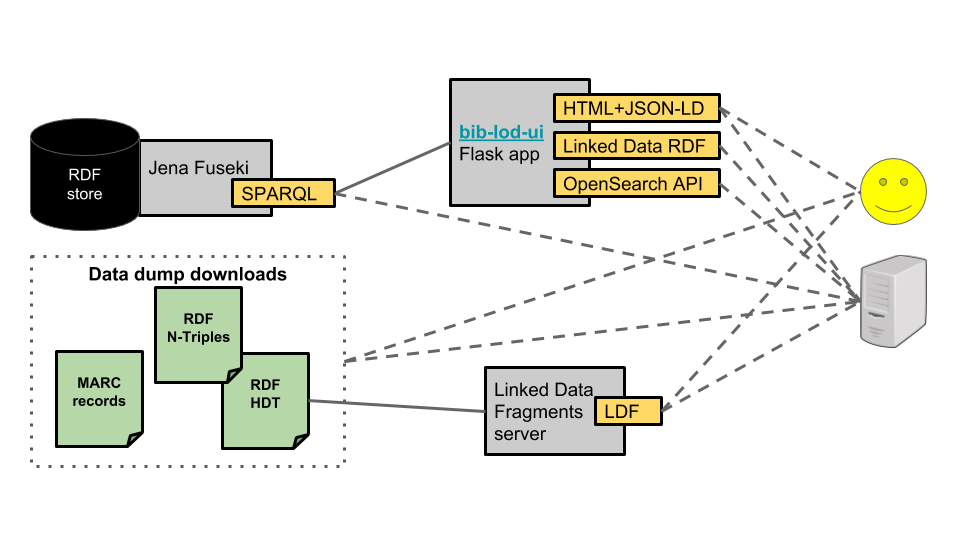
The linked data can be accessed in several ways (Figure 6). Works and other entities have been assigned identifiers (URIs) that resolve to a user interface (data.nationallibrary.fi), which can be used to browse the dataset and to perform searches for authors, titles and subjects. All relationships between entities are shown as links. We also provide machine readable data in multiple RDF serialization formats, including embedded JSON-LD in web pages. SPARQL and Linked Data Fragments APIs are also available for making queries. The full data set can be downloaded both as RDF (including the compressed HDT format) and as the original MARC records.
Figure 6. Infrastructure for publishing the data as Linked Data.
Further work
When initially publishing the Fennica data as Linked Data, our main concern was identifying the correct entities and expressing their relationships. We are now working on adding more detail and depth to the RDF data model, for example by using more specialized Schema.org classes such as Map. We are also planning to publish the Finnish national discography Viola and the article database Arto as Linked Data using the same approach and infrastructure.
A distributed network of heritage information
Enno Meijers, Wilbert Helmus, Sjors de Valk; NDE
Introduction
The Dutch Digital Heritage Network (‘NDE’) is a partnership that focuses on developing a sector wide digital infrastructure of national facilities and services for improving the visibility, usability and sustainability of digital heritage. The Network was established in 2015 on the initiative of the Ministry of Education, Culture and Science. Key partners within NDE are national heritage institutions, the National Library, the National Archives, The Netherlands Institute for Sound and Vision, the Netherlands Cultural Heritage Agency and the Humanities Cluster of the Royal Netherlands Academy of Arts and Sciences, and a growing number of partners both within and outside the heritage sector.
NDE is responsible for realizing a joint strategy program for the Dutch cultural heritage network. The goal is a distributed network build by the institutes and their stakeholders, each contributing from their own perspective and in their own capacity. The program consists of a three layered approach focussed on the management of data collections (‘sustainability’), the infrastructure for connecting the data (‘usability’) and applications for presenting and using the data (‘visibility’).
Discovery Infrastructure
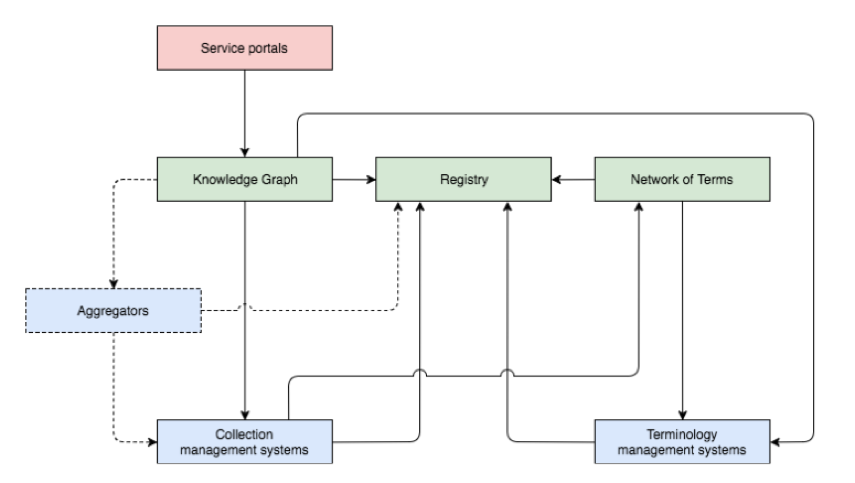
This article describes the long term vision NDE is developing for a discovery infrastructure for the Dutch heritage collections and the work that is being done in this respect at the ‘usability’ layer. We expect to improve the usability of the collection data maintained by the heritage institutions by implementing Linked Data principles in all levels of the network. The NDE program supports heritage institutions to align their collection data with shared Linked Data resources, such as thesauri, and to publish their data as Linked Open Data. Our goal is to develop a lightweight cross-domain discovery infrastructure that is built on a distributed architecture.
One of the core functionalities in the usability layer is a ‘network of terms’ that supports discovery of shared definitions for places, people, concepts, time periods. These terms are made accessible through a search API that provides URIs pointing to the terms in the distributed sources. Collection management systems can address this API to search for relevant terms when cultural heritage objects are being annotated. As a result references to formalized terms (URIs) will be added to the object descriptions. IT suppliers are encouraged to support the publishing of collection metadata as Linked Data. A reference architecture for the Dutch digital heritage network (DERA) that will formalize the publication of Linked Data is under development. The NDE program makes all relevant terminology sources, maintained by the institutions, available as Linked Data and provides facilities for term alignment and building new terminologie sources. Tools like CultuurLINK, PoolParty, OpenSKOS are being provided by the NDE network.
Browsable Linked Data
Having cultural heritage institutions publish their data as Linked Open Data with references to shared definitions for places, people, concepts and time periods is one part of the challenge. The other is to provide means for navigating in a cross-domain, user-centric fashion. Based on possible relevant URIs identified in the user queries we want to be able to identify the relevant and available Linked Data in the cultural heritage network. In general the concept of ‘browsable linked data’ is still a challenging concept. Although Tim Berners-Lee describes the concept of ‘browsable graphs’ and even states that statements which relate things in two documents must be repeated in each, this is not a common practice in the Linked Data world. The current practice is to offer Linked Data in a ‘follow your nose’ fashion which is only based on using forward links to point to other resources.
In order to navigate in a bidirectional way through the Linked Open Data cloud, support for navigation based on backlinks is needed. Most Linked Data projects support bidirectional browsing by physical aggregation of Linked Data sources. Using this aggregated data in triplestore databases both entries to the resource can be queried. This approach requires data replication and large central infrastructures and does not comply with our vision for a distributed network of digital heritage information.
An alternative approach is virtual data integration using federated queries. Unfortunately the current Linked Data solutions (triplestores with SPARQL endpoints) are hard to implement for small organizations and often suffer from performance issues in a federated setting. A promising approach is the implementation of the Linked Data Fragments framework, which we are currently investigating. But even using federated querying based on Linked Data Fragments leaves the question which endpoints have relevant data for a specific user question. Random querying all the possible endpoints in our network using Linked Data Fragments would be impractical and unrealistic. A preselection of data sources relevant for the query is necessary.
Registry
These considerations have lead to our decision to build a (preferably distributed and automated) registry that records backlinks for all the terms used in the digital heritage network. The registry contains the formal Linked Data definitions of the institutions and datasets in our network. Based on this information a Knowledge Graph is constructed as a ‘network of relations’ describing the relations between the data sources and the shared terms in our network. These relations facilitate navigating from URIs related to the user query back to the object descriptions in the collections.
We have described the intended functionality for our distributed network of heritage information in a high-level design [6], which will be updated in May 2018. We are maturing the design and implementing parts of the functionality together with a range of heritage and research institutions. One of these projects is in cooperation with Europeana and the National Library and focuses on the delivery of metadata in EDM based on linked data that is described in schema.org. If successful this could become the preferred approach for the delivering metadata from the NDE network to Europeana.
Integrating Linked Open Data with the Library’s Digitized Special Collections
Myung-Ja K. Han, Timothy W. Cole, Deren Kudeki, Caroline Szylowicz; University of Illinois Urbana-Champaign
Motivation
While many cultural heritage institutions curate their special collections into digital collections, most of those special collections have been relegated to information silos largely disconnected from the broader Web or even from their own library collections. Describing resources using an RDF compatible vocabulary and adding links to external authorities and other Linked Open Data (LOD) services helps connect special collection items and break down silos. We selected Schema.org as our RDF vocabulary for the following four reasons: it was developed by and is used by the major web search engine vendors and so presumably will help connect our collection's data to other web resources; other relevant schemas considered (e.g., BibFrame 2.0, etc.) were less mature at the project's outset; other schemas were too “heavy-weight” for the project’s needs and goals (e.g., FRBROO, CIDOC-CRM, etc.) and considering the limited depth of pre-existing metadata available; and some existing schemas had much less adoption (e.g., the SPAR family of ontologies).
Funded by the Andrew Mellon Foundation, the University of Illinois at Urbana-Champaign Library tested the benefits of LOD for digitized special collections from 2015-2017. We tried to see how these unique resources could be better connected to the Web, and how we can use LOD to achieve this. Objectives of the project include mapping legacy metadata schemas to LOD-compliant schemas, and actively linking to and from DBpedia, VIAF, and related Web resources that are relevant to the collections and items included in the collections.
We tested three collections created and housed in the University of Illinois at Urbana-Champaign Library’s Rare Book and Manuscript Library for this project, two image collections with theater events that use customized Dublin Core (the Motley Collection of Theatre & Costume Design and the Portraits of Actors, 1720-1920), and a text collection with research cards that uses TEI as its encoding standard (the Kolb-Proust Archive for Research).
Mapping Legacy Metadata to Schema.org
Metadata for Image Collections
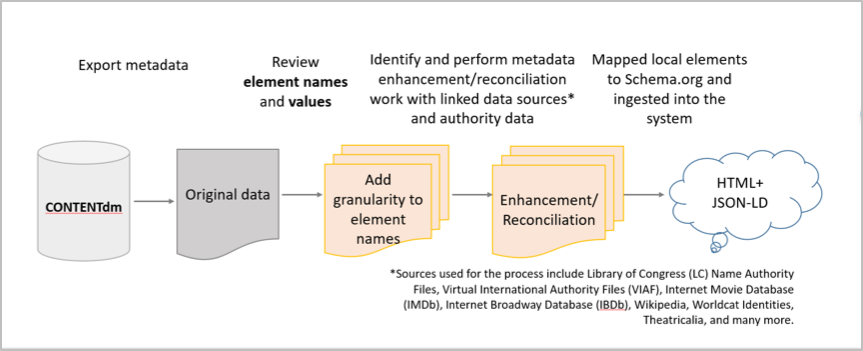
Metadata assessment carried out at the start of the project revealed that the metadata for the image collections describe not only the image itself, but the performance in which the costume was used, the theatre in which the play was performed at as well as the performance date, production notes, and the authors or composers who wrote the related work(s). As a first step, we performed metadata cleanup of both values and elements, e.g., we added granularity to the element names and corrected locally developed terms to more widely recognized controlled terms. Then we identified and performed metadata enhancement and reconciliation work to align with LOD and established Web sources and authorities. These sources included theater-specific Web resources such as internet movie database and internet Broadway database as well as the virtual international authority file and Wikipedia and so on. As a last step, we mapped local elements to schema.org and ingested them all into our system. Figure 1 captures the whole process from the metadata cleanup to the publishing as JSON-LD.
Figure 1. Metadata cleanup process for two image collections
After mapping (Appendices 1 and 2 show mappings for two image collections in detail), our original object descriptions are represented with three Schema.org classes: · schema:VisualArtWork which describes the image · schema:CreativeWork which describes performance work and for which we would propose a new subclass, StageWork · schema:Book which describes the work from which the performance was adapted.
Metadata for a TEI-Encoded Text Collection
Metadata for our third collection, the Kolb-Proust Archive Research is encoded in TEI originally from the research notecards, which means that digital objects are TEI-Encoded note cards, not metadata records describing images or textual works directly. For the mapping, we decided to treat individual cards as schema:Dataset, which we thought the best match from the Schema.org, and to use Professor Kolb as the author of the datasets. Appendix 3 shows a mapping from TEI elements to Schema.org properties.
Brining Linked Open Data to Users
Mapped metadata that are encoded in Schema.org properties are embedded into HTML JSON-LD page as shown in Appendix 4 to help discovery of special collections on the web. With URIs found from the LOD sources for entities mentioned in the metadata, we designed two new services for our local users.
Providing Contextual Information to Users
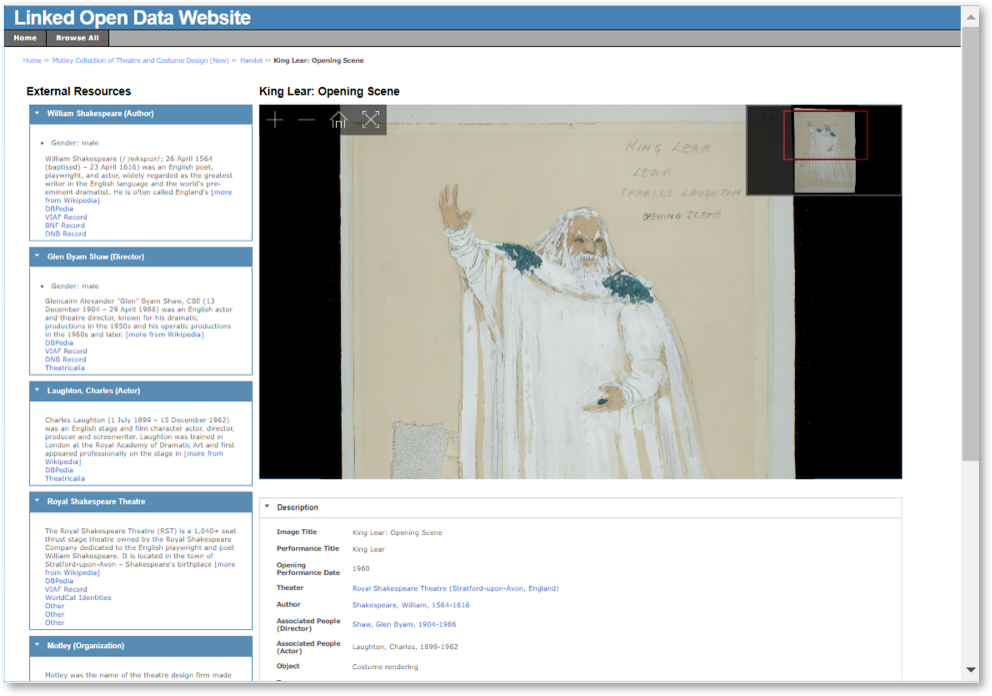
Relying on JSON-LD image descriptions saved on the local server, Web page (client) JavaScript dynamically fetches information from LOD services that we want to provide as context to users viewing our images. For example, entities that have LOD URIs (including author, director, actor, theater, and sometimes the performance) are displayed in the left pane of the item display page as shown in figure 2 below. Most entities have a VIAF URI and/or a Wikipedia URI, both of which can be called to find additional LOD URIs, like WorldCat Identities, plus VIAF and Wikipedia. These retrieved URIs are displayed alongside any URIs stored locally in the JSON-LD. Wikipedia URIs are also used to retrieve blurbs and other select data about an entity. The links and the data from Wikipedia are included in the left pane to give users an opportunity to explore additional web resources right away.
Figure 2. When an entity has URIs from linked open data sources, JavaScript service widget calls out the semantic web data store and dynamically fetch several information that we want to provide to users.
Creating a Knowledge Card for an Entity
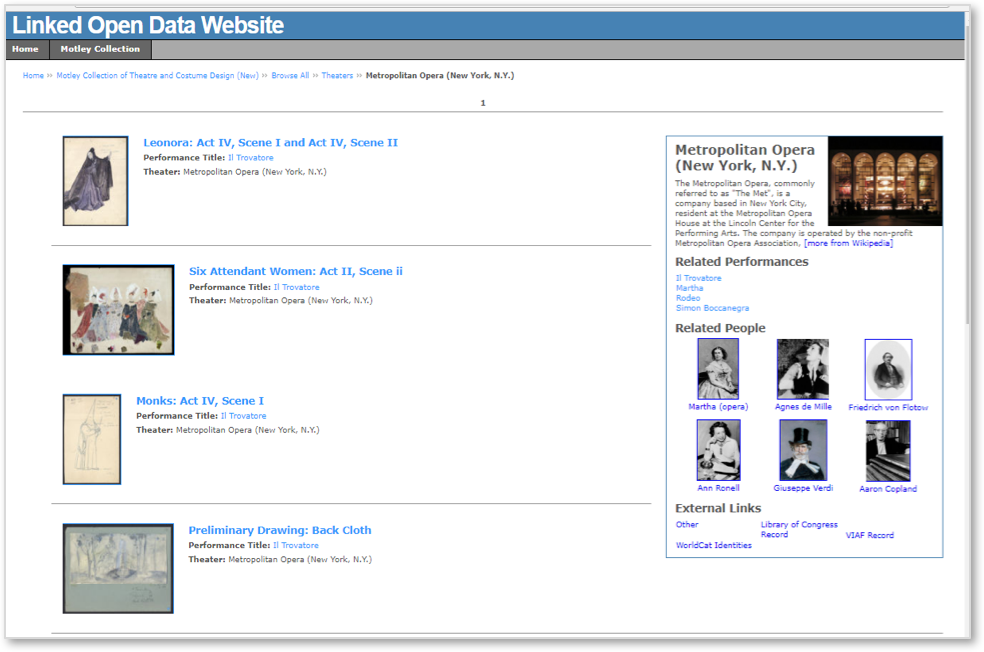
When users use a specific entity name to browse the collection, local RDF graphs related to that specific entity can be used to create a knowledge card as shown in figure 3. This is similar to the feature used by the major web search engines that provide users information about the entity available, and provides links to further information both included within the special collection and available elsewhere on the web. A database (Solr) of all the metadata in the collection is used to find the entities associated with the entity that is being viewed. Associated performances or theaters are used to generate internal links that the user can follow to browse by. The people that most often appear alongside the entity being browsed are also retrieved, and their Wikipedia links are included and called to retrieve images when available.
Figure 3. Linked open data also makes it possible to create a knowledge card for the entity that provides users with information in the collection and on the web.
Lessons Learned
When publishing LOD, digitized special collections require ‘special’ care when mapping legacy metadata to LOD-compliant vocabularies including additional entities and properties, or using additional linking properties like schema:mentions and schema:citation when insufficient information is available to use more specific properties.
When using LOD for users, the user experience can be enriched by adding contextual information through dynamically added sidebars and clickable links that leverage existing semantic web sources and provide opportunities for users to escape the siloed environments of traditional digital libraries.
We also learned that additional opportunities for leveraging the semantic web remain to be explored, such as pushing information back out to the semantic web through Wikipedia edits and new articles that would increase discoverability of special collection resources, and visualizations that would show users relationships between resources. The question is how we, cultural heritage institutions, can work together to find effective ways of publishing and using LOD for digitized special collections and for users.
Managing Assets as Linked Data with Fedora
David Wilcox; Fedora
Fedora is a flexible, extensible, open source repository platform for managing, preserving, and providing access to digital content. Fedora is used in a wide variety of institutions including libraries, museums, archives, and government organizations. The Fedora project and community have been interested in linked open data for some time, but the latest version of the software, Fedora 4, takes a much more robust approach with native linked data support and alignment around modern web standards such as the W3C Linked Data Platform (LDP). A Fedora workshop delivered at SWIB17 provided a broad overview of Fedora’s features and benefits, with a particular focus on the support for linked open data. Attendees had an opportunity to create and manage assets in accordance with linked data best practices and the Portland Common Data Model using pre-configured virtual machines. The workshop also demonstrated workflows for exporting resources from Fedora in standard RDF formats, as well as importing these resources back into a Fedora repository.
DuraSpace, the not-for-profit organization that stewards Fedora, hosts over a dozen half and full day Fedora workshops at conferences and events around the world each year. Workshop materials, including slides and notes, are made available under open Creative Commons licences for reuse, and attendees are provided with a pre-configured Fedora virtual machine that can be installed on virtually any modern laptop and operating system. This virtual machine comes not just with Fedora, but also with the Solr search application, Fuseki triplestore, and Apache Camel middleware that uses asynchronous, message-driven integrations to populate both the search index and triplestore with each change made to resources in Fedora.
The first half of the workshop provided a broad overview of Fedora, including the value proposition and example implementations, before moving to discuss specific features. Fedora has a very narrow, well-specified set of features, each of which is aligned with a standard:
Along with this set of core features, Fedora provides well-documented patterns for integrations with other applications and services, primarily through the HTTP REST-API and the messaging system.
Creating and managing resources in Fedora is done primarily via the REST-API in accordance with the Linked Data Platform, a recommendation from the World Wide Web Consortium that “defines a set of rules for HTTP operations on web resources, some based on RDF, to provide an architecture for read-write Linked Data on the web.” By implementing the LDP specification in this way, Fedora acts as a linked data server; RDF is the native response format when interacting with Fedora resources via the REST-API. Workshop participants had an opportunity to experience this functionality fist-hand by creating and managing resources in Fedora using the built-in HTML interface, which exposes a subset of the REST-API using content negotiation. This interface also provides a SPARQL-Update query box, allowing users to insert or modify RDF triples on Fedora resources. This is useful for providing descriptive metadata, as well as other related metadata for things like access control and administration.
After learning about and exercising core Fedora features, workshop participants received a brief introduction to the patterns that support common external integrations. In addition to the REST-API, Fedora supports asynchronous integrations via message-based frameworks. Fedora emits a message each time a resource is created, updated or deleted, which can be intercepted and used to kick off external application workflows. This is commonly achieved by using Apache Camel (included in the workshop VM), which has been configured to intercept Fedora messages and update external indexes; in this case, Solr and Fuseki. Fuseki is particularly useful for linked open data use cases as it exposes a SPARQL-Query endpoint that can be used to run complex queries across the RDF stored in Fedora. This endpoint could be exposed publicly as well, allowing external agents to search a Fedora repository and potentially combine the search results with other publicly accessible linked open data.
The workshop included a section on linked data basics, where participants learned about concepts like RDF, ontologies, vocabularies, and the linked open data rules set forth by Sir Tim Berners-Lee. Following this brief introduction, attendees learned about a specific data model based on linked data concepts, the Portland Common Data Model. This model takes a low-level approach to interoperability by providing basic entities and relationships that are broadly applicable across domains. PCDM is not specific to Fedora, but it can be implemented in a Fedora repository using the basic CRUD functions and SPARQL-Update queries that participants learned in the previous section. By implementing these techniques, workshop attendees were able to create resources and relationships in Fedora that mapped on to a PCDM example provided in the presentation materials.
The workshop concluded with a discussion on the Fedora project roadmap, how to get involved and get support, and how to ensure Fedora continues to be a successful and sustainable open source project into the future. DuraSpace is a member supported not-for-profit, and institutions that use and benefit from Fedora join as members and contribute financially on an annual basis to ensure the project is staffed and maintained.