Our learnings
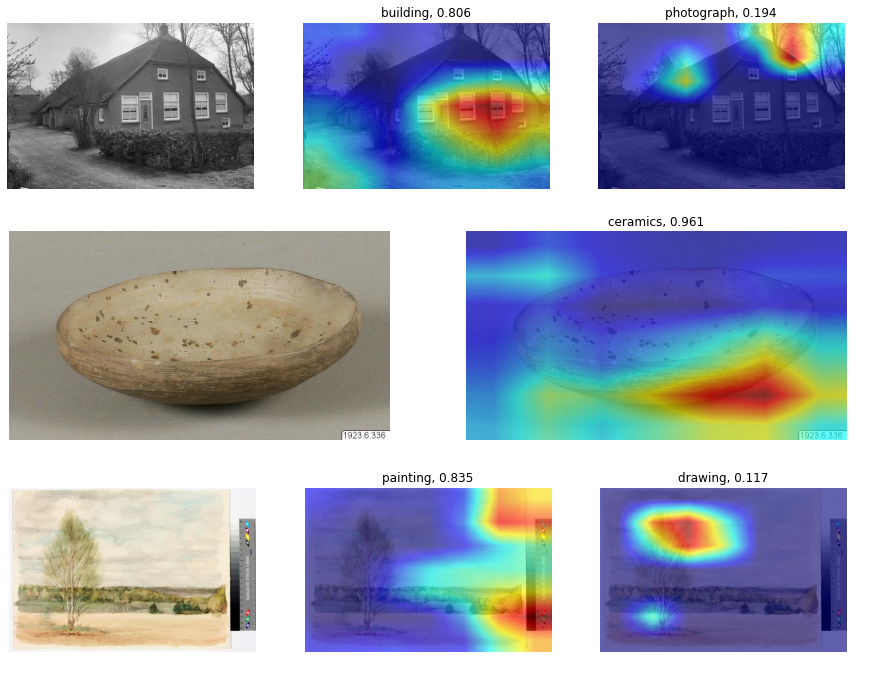
From the previous results, we can see that the model was able to successfully capture the most relevant concepts of the vocabulary for the given images. While it is far from perfect, the model can learn from our enriched collections, and can be applied to new images to generate potentially useful metadata.
The main limitation of our approach is that the concepts of the vocabulary are not exclusive, and this doesn’t align well with a single class per image. For example, an image can be a photograph and contain both a building and a sculpture, but due to the single label approach we can only train and evaluate our model to identify one of these aspects.
This gives us a model that often outputs a high confidence score for only one of the categories, with the confidence for the rest of the categories low. By setting a low threshold for the confidence scores of the output, we can get more than one label as the output. However, this approach is not ideal since all the confidence scores need to add up to one (as in any legal probability distribution), which prevents high confidence values in the case of a vocabulary with multiple categories.
Ideally, our model would be a multilabel classifier - a model that is trained with more than one label per image and that is able to output high confidence scores for several categories.
It is also worth mentioning that our dataset has been assembled without human supervision (we didn’t review the images obtained or checked whether or not they are indeed aligned with the categories). This means that the quality of the dataset will depend on the metadata associated with the cultural heritage objects and on previous automatic enrichments based on metadata. In practice not all the images from the training dataset were aligned with the correct categories.
Next steps
We are currently assembling a training dataset for multilabel classification, and will share our work and approach in a future Pro news post - stay tuned! In the meantime, you can explore our Github repository for the pilot,and this Colab notebook, where you can make your own queries to Europeana Search API and apply the single label classification model.
Feel free to contact us at rd@europeana.eu if you have any questions or ideas!