
Tristan Roddis
Director of Web Development , Cogapp
EuropeanaTech 2015 projects - where are they now? Qatar Digital Library
With EuropeanaTech 2018 just around the corner, we hear how a couple of projects presented at the 2015 conference have developed. Today, Tristan Roddis of Cogapp tells us about the Qatar Digital Library online archive.

- Title:
- Transcription search term highlighting - Qatar Digital Library
- Creator:
- Tristan Roddis
- Date:
- 2018
- Institution:
- Qatar Digital Library
- Country:
- Qatar
- Copyright:
- CC0
The project
For EuropeanaTech 2015, I presented a poster about the Qatar Digital Library online archive. The Qatar Digital Library (QDL) makes a vast archive featuring the cultural and historical heritage of the Gulf and wider region freely available online for the first time. It includes archives, maps, manuscripts, sound recordings, photographs and much more, complete with contextualise explanatory notes and links, in both English and Arabic.
The source content and structured metadata was produced by the British Library according to common archival standards. The final website, created to present this information in an engaging and highly usable way, was produced by Cogapp.
The story back in 2015
The site had launched in October 2014 and was still in its infancy, but we wanted to talk about the following:
-
The underlying data: documents digitised and catalogued by the Qatar Foundation Partnership Programme team at the British Library
-
The way the data is delivered online: Solr, Drupal, IIPImage
-
The way the data is transformed: METS and ALTO to Solr documents
-
The way the data is stored: Solr schema fields for search, categorisation and structure
-
The system architecture: redundant architecture with load balancing and GlusterFS as a clustered file store
-
The plan for data growth: the site launched with 93,000 pages, and in February 2015 had over 300,000.
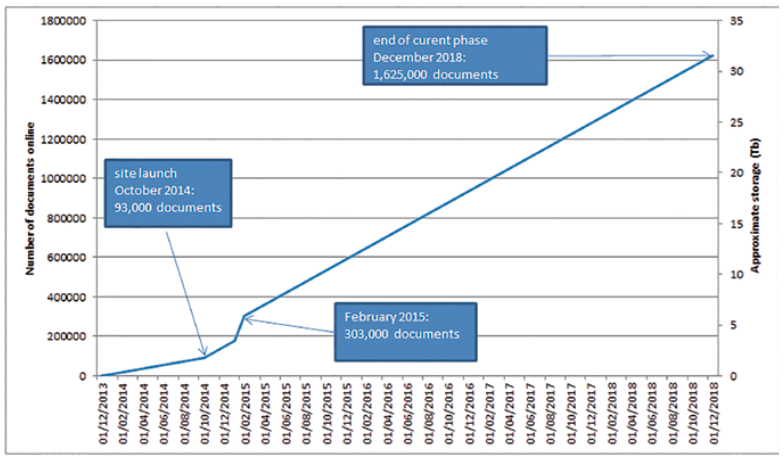
Figure 1: a graph of predicted data growth, created for EuropeanaTech 2015. Tristan Roddis. CC0.
What's happened since?
Since then, the site has continued to be maintained by Cogapp, thanks to budget allocated by the Qatar National Library, and so has evolved a lot in terms of user-facing features. But how did our initial system stack up, and did it stand the test of time? Let’s look at each point in turn.
-
The underlying data: the British Library has continued to contribute the vast majority of the online archive, but we have also been able to add several thousand pages from the Qatar National Library’s own Heritage Collection, thanks to cataloguing and translation efforts by the World Digital Library.
-
The way the data is delivered online: Solr, Drupal and IIPImage continue to provide the underpinnings of the site, but we have upgraded Solr periodically from its initial version 4 to its current version 6. We have also upgraded IIPImage so that it now supports the International Image Interoperability Framework (IIIF) Image API, and added a lot of content-management features to Drupal, most notably the ability to import linked authority file data, and to update the categorization of archival documents.
-
The way the data is transformed: we continue to transform METS and ALTO to Solr documents, but have carried out a number of optimisations to reduce the amount of storage required and to increase site responsiveness.
-
The way the data is stored: we continue to store all archival data as Solr documents, but have changed the way things are stored to allow better cross-language searching between Arabic and English, as well as to provide a grouped view of search results.
-
The system architecture: all components are still load-balanced and redundant in two different data centres, but we have swapped out the GlusterFS system (that relies on comparatively high-cost Elastic Block Storage) for a cheaper and simpler image store backed by S3.
-
The plan for data growth: the British Library continues to add content, and at the time of writing there are 1,367,012 pages visible on the site: exactly on-track for the 1.6 million documents by the end of the year.
As well as evolving the underlying systems as mentioned above, we have also kept busy in the intervening three years by adding new user-facing features to the system: full support for both the IIIF Image and Presentation APIs, a timeline search with histogram of results per year, the Farasa Arabic word segmenter, and search-phrase highlighting of transcriptions, to name a few.
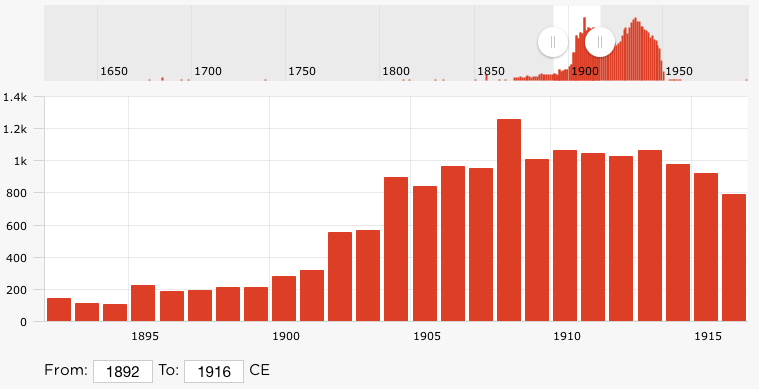
Figure 2: timeline date search, Tristan Roddis. CC0.
In conclusion, the choices we made back in 2015 have stood the test of time, although being able to evolve the underlying systems has meant we can not only keep up-to-date with improvements made to third-party systems, but also make our own code and data more robust and able to meet changing user needs.
This year at EuropeanaTech 2018
And finally, does this relate in any way to the topic of my own talk at this year’s EuropeanaTech? The answer is: partially. My subject is 'When automated analysis goes wrong' and as part of this, I’ll be looking at the challenge of extracting documents with illustrations from within the tens of thousands of pages of handwritten medieval Arabic manuscripts: where we went wrong, and how we finally managed to reliably disambiguate these without any human intervention.