Enriching cultural heritage metadata with better tags and descriptions makes it easier for anyone to search and find these cultural heritage objects, which means you'll find what you need quicker and more easily. Recent advances in IT and AI offer remarkable opportunities for the automatic enrichment of cultural heritage metadata with minimal resources. However, involving humans in this work remains important. In the CRAFTED project, we are taking craft heritage as a case study in order to forge, implement and test a methodology that combines algorithms with human validation for the enrichment of cultural heritage metadata at scale.
The methodology, which we outline below, consists of four main steps: data analysis; automatic enrichment; validation of the enrichments by humans; and refining enrichments based on the validation outcomes. In each of the steps in this process, we grappled with a number of crucial questions. What kinds of enrichment are useful for different types of data? How do we select appropriate samples for human validation? How can we establish acceptable quality thresholds for automatic enrichments?
Data analysis
Gaining a detailed understanding of the metadata and content in the collections selected for enrichment, as well as defining case appropriate enrichment objectives, is a crucial first step in determining the requirements that our tools have to meet. It's important to study the different languages and semantics of each metadata field, as well as the way their values are structured (for example, when looking at a field that conveys spatial information one might find out that its value is often structured in the format of ‘city / region’). Similarly, the characteristics of the content have to be scrutinised to identify meaningful features that can be derived from it, considering aspects like the available image resolution and the way objects are depicted in images.
Automatic enrichment
In the CRAFTED project we have applied a number of different tools to analyse the textual metadata and content of a large variety of collections with different characteristics and enrichment needs. For the analysis of metadata, we used the SAGE platform (Semantic Annotation and Generation of Enrichments) developed by the National Technical University of Athens. The platform is able to analyse textual metadata in different languages and identify a broad variety of case-appropriate concepts (such as materials and techniques) mentioned in the metadata. It can then link them with terms from domain-specific online vocabularies, such as the Europeana Fashion thesaurus that covers fashion-related concepts. It can also perform more general-purpose named entity extraction to identify organisations, places, and people, and connect them to Linked Open knowledge bases such as Wikidata.
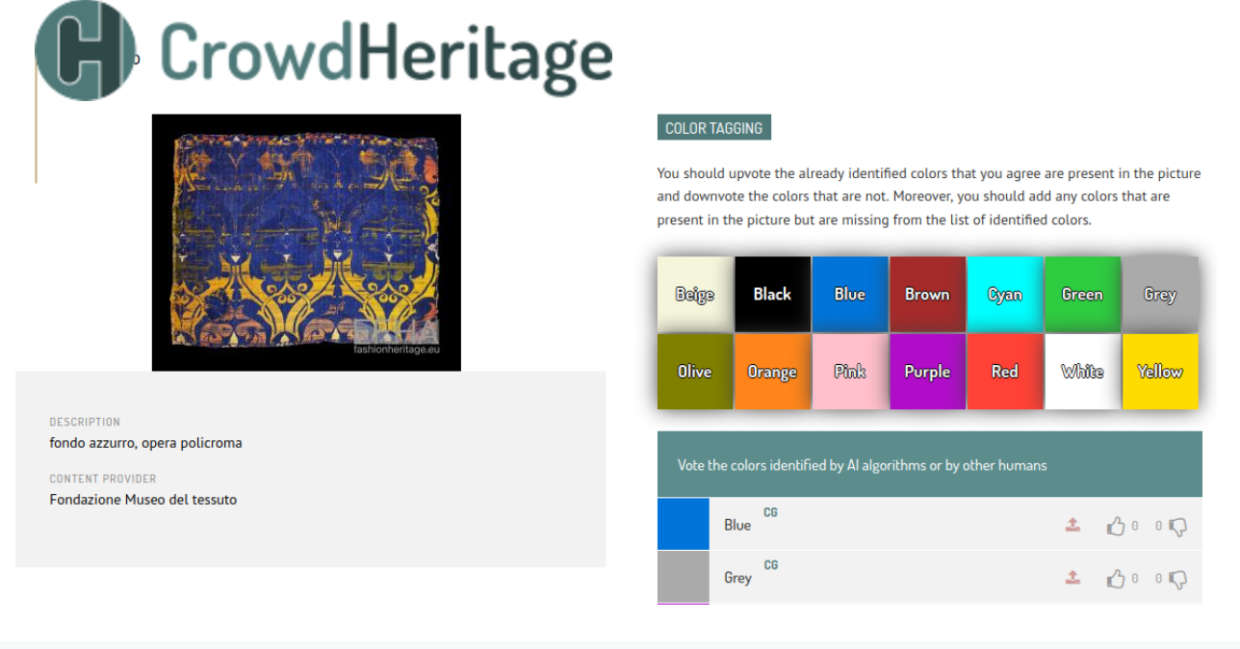
In parallel, we tried out a number of tools that analyse images and videos. We experimented with two main approaches for colour detection: the first approach distinguishes the foreground from the background, after which it tries to extract the colour(s) of the detected foreground. The second approach essentially does the same, but is assisted by a trained object detection algorithm. We also tried to detect and extract written text from images using OCR (Optical Character Recognition). Lastly, we extracted textual transcripts from videos, with mixed results depending on the spoken language.
Human validation
In the third step of the methodology, humans are invited to check the results of the automated annotation step and accept or reject them. The human validators can also add new annotations that the automatic algorithm failed to identify.
Admittedly, the more of these automatic annotations are validated, the better. However, there are thousands of these automated annotations, and having human validators go through them is a very resource-intensive process. So instead we review a sample of the annotations that is selected to allow us to draw conclusions about all automatic annotations.
A number of factors have to be considered during sample selection. For the metadata analysis, the sample needs to cover different metadata fields with various text lengths, consider the certainty scores that the annotation algorithms assigned to their annotations (which suggest how confident they feel that they are correct), and so forth. Similarly, for the content analysis, the sample has to keep a balanced representation of items with different content characteristics, for example, with different colours and different types of objects.