Issue 5: Annotations
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community.
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community.
...and we’re back! After quite some silence EuropeanaTech is pleased to present our newest issue of EuropeanaTech Insight. With this issue we focus on annotations, which has been and continues to be a pivotal focus of the EuropeanaTech Community’s R&D efforts. Over the years, Europeana and its partner projects have been involved in developing annotation solutions and applying this to research scenarios like Digitised Manuscripts to Europeana (DM2E) and Europeana Sounds.
Over the next four articles we will check-in with our friends at Hypothes.is, Annotate All Knowledge, Pundit and Europeana Sounds to see how their collective work is improving the status of web annotations as a means of sharing knowledge. Most of these contributions were collected in the context of the IAnnotate conference, hold in Berlin in May 2016.
Thank you to all the contributors. Enjoy!
-The EuropeanaTech team
Scholars are natural annotators, as the process of creating new knowledge requires building on what’s come before. The ability and desire to underline, highlight and comment on specific parts of texts or images is as old as writing itself. For decades web pioneers imagined such an intuitive and collaborative capability, seeking to build annotation into the fabric of the Web itself. Many projects over the years experimented with approaches to this, yet we currently live with a sparse patchwork of proprietary commenting systems, largely disconnected from the parts of the documents they reference and from each other.
Within the last few years, a small but growing community has succeeded in developing a new generation of web-based annotation tools. In 2014 the World Wide Web Consortium (W3C), the standards body for the Web, established a formal Working Group to define a standard for web annotations. Much progress has been made, and many implementations are now mature enough to be deployed. Several of these were on display at the recent iAnnotate Conference, held in Berlin in May, 2016. A simple browser extension or web proxy adds an overlay to web pages and documents enabling annotation of portions of text with comments, tags, links or even images and videos. These annotations are able to be seen by visitors to the same resources, and are interactive, sharable and searchable.
Despite the emergence of an open standard, however, the predominant annotation systems today remain siloed and inaccessible. Just as with our current commenting systems appearing at the bottom of many web pages, these tools are proprietary--specific to an individual vendor. In other words, if the same scientific article or scholarly work is annotated using two different tools, users of one won’t see or be able to respond to annotations created with the other.

Some members of the AAK Coaliation such as Europeana or Pundit
The Annotating All Knowledge (AAK) Coalition aims to address these issues by unifying web annotations. AAK launched in December, 2015 (Perkel, 2015) and currently comprises more than 70 of the world’s most essential scholarly publishers and knowledge platforms. Members are joining together to define and create a robust and interoperable conversation layer over all scholarly works. Such a layer can transform scholarship, enabling cross-platform personal note taking, peer review, copy editing, post-publication discussion, journal clubs, classroom uses, automated classification, deep linking, and much more. Members understand that this layer must evolve as an open, interoperable, and shared capability aligned with the motivations and interests of scholars and researchers. In other words, members are agreeing that annotations should not belong to any one platform and that they should be designed for and operate within the web.
What, exactly, does this mean? The Coalition has been defining and refining the concept since it launched in January, 2016. Two recent meetings brought together stakeholders and interested parties: the AAK Coalition kick off meeting held in conjunction with the FORCE2016 meeting in Portland and the iAnnotate Conference.
The idea emerging from these forums is that annotation should work like email or current web browsers. We have many email clients and web browsers and many servers to support them. But users can send email across these clients and servers. Web browsers can understand web content and more specialized functions such as privacy settings regardless of the server. Each client or browser may have specialized functions and do certain things better than others, but at the core, they are interoperable. The AAK is providing a forum for those developing annotation systems to network, share use cases, and implement them interoperably.
If successful, annotation will become a ubiquitous shared knowledge layer across scholarship. If you are currently developing an annotation tool, or are interested in doing so, we invite you to join us: coalition@hypothes.is.
Reference: Perkel, J. (2015) Annotating the scholarly web. Nature, 528: 154.
The Web Annotation Working Group recently released the Candidate Recommendations for the standards that will govern interoperable web annotation. Based on Linked Data, JSON-LD, the Linked Data Platform, and the work done over the past years in the Open Annotation Community Group, these specifications are the result of a great deal of research, experimentation, and discussion. They reflect the ideas of Web 2.0, where the audience is a producer of information in an interactive and participatory Web, not just consumers. They also form a bridge to the nascent Web 3.0, where machine processable data will form the semantic web, by creating third party relationships between resources that are not controlled by the annotator using Linked Data.
There are three specifications:
The first two are built upon the foundations laid by the Community Group and the third on the good work of the Linked Data Platform (LDP) specifications.
The envisioned annotation ecosystem requires that all of these components, plus one more that is still making its way through the standardization process -- a simple system for notification that a reference has been made to a resource, called Webmention. The ecosystem will allow annotations on web pages, sections of text and embedded resources within those pages, and on the annotations to enable replies and threaded discussions. The LDP based protocol will allow those annotations to be transferred between client and server, or server and server. Webmentions will let servers know that their resources have been annotated, regardless of what those resources are, and potentially feed back into either the content of the resource or the discovery of it.
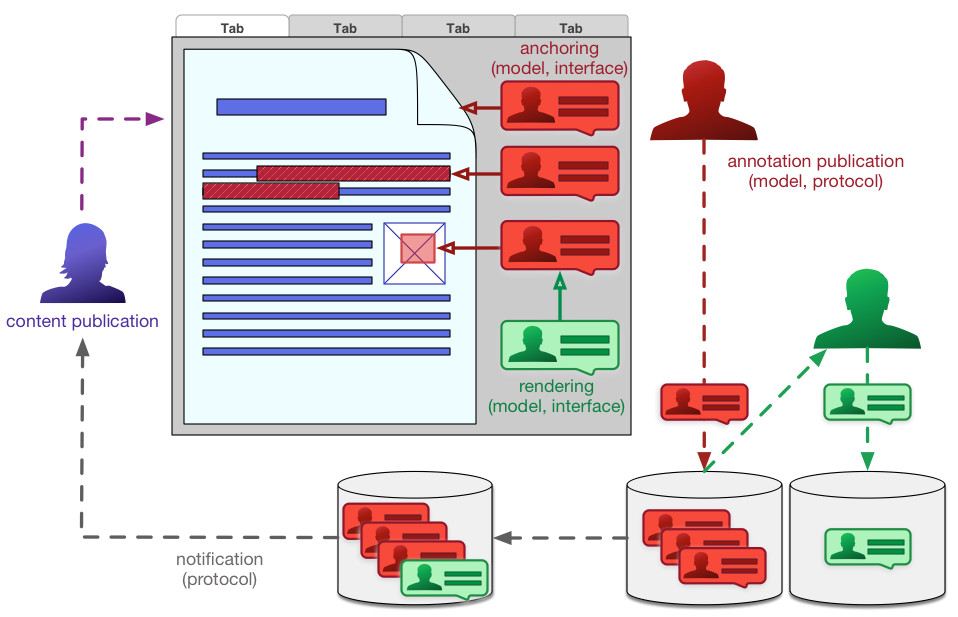
A concise and crisp definition of the scope of an "annotation" has remained elusive, and the most acceptable way to resolve the issue has been to describe the motivation of the annotation i.e. the reason why the annotation was created. This covers activities such as commenting on something, tagging it, assessing or reviewing it, identifying or classifying it as something, or just bookmarking it for later reference. Along with this why, the data model allows other provenance descriptions of who (the annotator), what (the target), when (the time the annotation was created or modified) and how (the client was used to generate the annotation).
Added to the provenance are new descriptive features beyond those identified by the Community Group. These include the audience that the annotation is suited or intended for. For example, annotations on a textbook for a teacher rather than a student, as well as the annotations’ rights statement to describe how others can make use of it. The ability to clarify the relationships between copies of the annotation was also added.
Compared to the output of the Community Group, the new model improves consistency at the same time as being simpler in some of the more complex cases, such as using structure rather than typed objects for the interactions between multiple selectors. It has been more developer friendly by adopting a more familiar style of JSON representation and by adding new web-focused selectors using the CSS and XPath standards. Finally internationalization and accessibility have been improved with the ability to describe the language to use for processing the text as well as its direction, and allowing accessibility features defined by Schema.org to be added to resources such as whether a video has captions, or whether braille or an audio description are available.
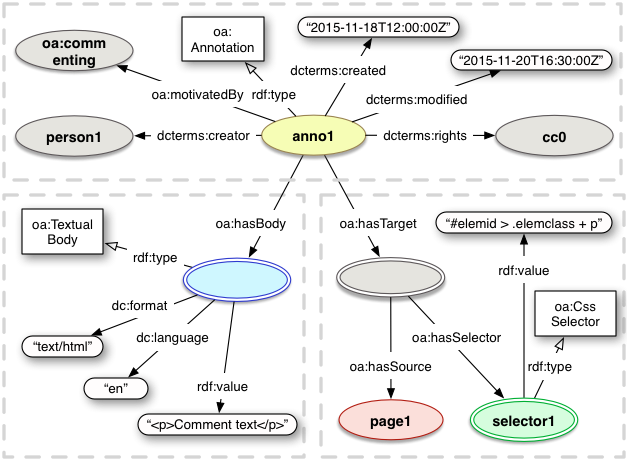
Overall, the model remains the same in the critical, structural features and expands around the edges to provide more functionality and better clarity. The necessary system interaction definitions that were not part of the scope of work for the community group have been added. The rough edges have been smoothed off for developers. All that remains is for implementations to be updated or created. The Working Group requests that references to any such implementations are sent to the group, such that they can be used as the evidence of adoption necessary to become a full W3C standard.
Cultural heritage institutions are looking at crowdsourcing as a new way and opportunity to improve the overall quality of their data and contribute to a better semantic description and link to the web of data. This is also the case for Europeana, as crowdsourcing under the form of annotations is envisioned and being worked on in several projects.
As part of the Europeana Sounds project, we have identified user stories and requirements that cover the following annotation scenarios: open and controlled tagging; geotagging, enrichment of metadata; annotation of media resources; linking to other objects; moderation and general discussions.
The central point for all the efforts around annotations is an agreement on how these should be modelled in a uniform way for all these scenarios, as it is essential to bring such information to Europeana in a way that can also be easily exploited and shared beyond our portal. For this, we are using the recent W3C Web Annotation Data Model (WADM) supported by both the W3C Web Annotation Working Group and the Open Annotation Community Group as it is the most promising model at the moment.
Due to its flexible design and ongoing stage of development, at the moment, there is insufficient recommendations on how some of our user stories and requirements can be modelled. We will make proposals on how the WADM can be applied for these scenarios and we are looking for discussion/feedback from the community in the hope that it will help cultural heritage institutions and other communities better understand how annotations can be modelled.
In particular, we are focusing on the following topics:
The outcome of these efforts will be an extension to the Europeana REST API which provides support for the management of annotations. The Annotations API was released as a public Alpha version in March (and it is now in its version 0.2.2), allowing developers to create and retrieve annotations in a RESTful way in accordance to the Web Annotation Protocol also supported by the W3C Web Annotation Working Group. The first platform which will fully exploit its functionality is the Europeana Collections, ensuring that the API is developed to solve and address validated user needs.
Web annotation is a means of interacting with web content that has been in the DNA of the web since its beginning. Mosaic, the first web browser ever released, included a native system for web annotation and since then there has been a long history of projects trying to get the annotation of web pages to become standard practice. Sadly, most of these projects have failed and still today web annotation is only used by a restricted niche of people.
At the same time making notes on books is still one of the best ways to engage with the text.

So on the one hand we have a paradigm of human-text interaction that has been utilized for centuries and on the other hand we have a technology (web annotation) that has failed to catch on since the beginning of the web. So what has gone wrong? What do we need to do to take the big step forward and fully exploit web annotation and make it available to a wider audience of users?
At Netseven we think that with these strategies we will be able to introduce web annotation to a wider audience: specialized users belonging to niche markets and contexts but also general users.
We also consider interoperability a fundamental feature to ensure the success of web annotation: in fact it was one of the “hot topics” during the iAnnotate 2016 conference and is supported by Hypothes.is and many other participants.


The Pundit project was set up in 2011 within the framework of several European-funded projects dedicated to the application of data technologies linked to the field of Digital Humanities, and in particular to Digital Libraries. The first version of Pundit was developed within the EU Semlib project, and continued within the framework of the EU DM2E project (2011-2013). In 2014, the StoM project was launched in order to bring Pundit to the market as a software-as-a-service platform. The specific features of Pundit have also been developed within the EU Europeana Sounds project. Pundit is used for semantic annotation in research projects such as the ERC AdG LOOKINGATWORDS and ERC AgG EUROCORR funded projects.
The original version of Pundit was designed to allow users to create semantic annotations of web pages selecting a part of the text and using it as a subject of one or more semantic triples, to build well described relations with the respective objects. It was a tool designed for scholars in the field of Digital Humanities. In late 2015 we decided to design a lightweight annotator (not for semantic annotation) and an annotations dashboard to see if we could provide more usable features for our existing users and at the same time if we could expand the field of application of Pundit.
Today Pundit is a suite of products:
All the data is stored in an Annotations Server, which was modeled following the W3C Web Annotation Working Group (draft December 2014). Since data export and interoperability are fundamental concepts for the future success of web annotation, we decided to follow W3C standards and to focus on data export to enable the annotations produced to be reused (which we want to prevent from being locked into our own system). However, there is still a lot of work to do on interoperability.
The Pundit platform has more than 800 registered users and a total of more than 40,000 annotations.
Web annotation could become the next big thing in terms of user interaction on the web, bringing some of the social discussion away from social networks and back to its original context: the web page. It’s up to us to understand which strategies and methodologies are needed to tackle this challenge, and my suggestions are user centered design, use cases, interoperability and technology focused on the user.
The Pundit project is moving in this direction by providing more usable tools, researching and experimenting with new use cases and working in the direction of a fully interoperable system. In May 2016 Pundit joined the Annotating All Knowledge Coalition and we plan to support the coalition both by providing Pundit as an interoperable set of tools and by collaborating in the discovery of use cases and fields of application.
You can comment this article using Pundit Annotator, get it here!
Dr. Maryann E. Martone is co-director of the National Center for Microscopy and Imaging Research at University of California, San Diego and serves as Director of Biosciences and Scholarly Communications for Hypothes.is.
Rob Sanderson is the Semantic Architect at the J. Paul Getty Trust, and has played a leadership role in the development and publication of the IIIF Image and Presentation APIs, W3C Open Annotation, and Shared Canvas specs.
Hugo Manguinhas works as a Technical Coordinator for Research & Development at Europeana Foundation. He advises and coordinates the scientific work on Europeana-related projects and participates in the development of Europeana’s own services, in particular for the areas of Linked Open Data, Metadata Enrichment, Vocabulary services and alignment, Data Quality and Crowdsourcing Infrastructure. He has collaborated in projects such as Europeana DSI1, EuropeanaSounds, EuropeanaCreative, EuropeanaChannels and Europeana v3.
Giulio Andreni is a Project Manager and Graphic Designer at Net7 based in Pisa, Italy. Net7 is the team behind the widely known web annotation tool, Pundit. Giulio and Net7 are directly involved in the annotation work being conducted as part of Europeana Sounds project and have been closely involved in numerous Europeana affiliated efforts over the years.