Issue 4: Discovery
In this issue of EuropeanaTech Insight we look at ways that institutions are changing and improving the way users explore and discover digital heritage collections available online.







In this issue of EuropeanaTech Insight we look at ways that institutions are changing and improving the way users explore and discover digital heritage collections available online.
With this issue of EuropeanaTech Insight we take a quick look at Tech community members who are changing the way users explore and discover content in interactive, serendipitous ways. Whether it’s a collection of 1,000 or 42,000,000 items, users want firstly, to find what they’re looking for and secondly, discover items they never knew existed but realize that their creative endeavor, research, or life in general was missing this key item buried amongst the countless other treasures.
Europeana is also changing the way we empower visitors with the creation of Europeana Channels and Europeana Content Re-use Framework. Soon visitors will be able to explore and discover the collection in new and more engaging ways.
We hope you enjoy these three papers that take you from working beinging done in Amsterdam, the UK and all the way across the world to Japan.
The current generation of access tools in the cultural heritage domain are inspired by modern web search technology, yet those tools privilege ultra-fast look-up search for factual details and navigational needs. The design of these systems fails to address the dominant needs of online users of cultural heritage, who have no crisp factual information need but come to learn or discover something. This difference has fundamental consequences on the design of systems that support users to explore and experience, to learn and be amazed, and engage with the material from many different angles. It has also fundamental consequences for back office systems that should empower curators to go beyond access and object descriptions, allowing them to translate their knowledge into a rich cultural information space.
Slogan #1: Web ≠ Cultural Heritage
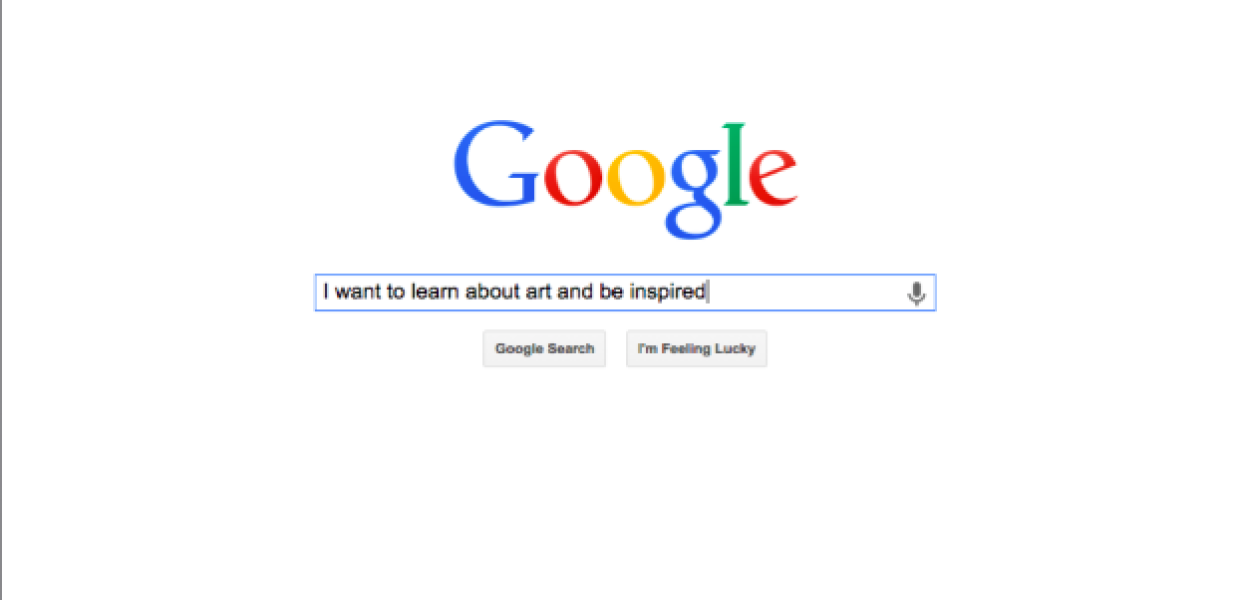
The use case of searching and exploring cultural heritage information online is fundamentally different from the use case of modern web search. Consider issuing a query like “I want to learn about art and be inspired’’ into an internet search engine. This is clearly a non-sensical query which will give no useful results. There are almost infinite differences between web search and searching and exploring cultural heritage information, in terms of the information needs (well defined factoid need vs. exploration and discovery), of the goal of the interaction (search outcome vs. search process), or the success criteria (fast fact look-up vs. slow and engaging exploratory search). In short, there is a complete mismatch between the use cases and underlying assumptions. These differences require a totally different type of system, and deeply impact and inform the design of such a system.
Slogan #2: Rage against the machine
Users are often powerless. This is how I often feel when using current systems: there is clearly something wrong with the search results, yet there is no transparency or control for me to change this around. This is not only the case in cultural heritage systems but even on the web. Search experts like me can figure out how to adapt my search to still find the desired results, but this requires me to adapt to the algorithm, rather than the algorithm adapting to me. This is a question of who is in control — we must put our users back into the driver’s seat. This holds for both the back-office systems meant for curators and heritage professionals and for the front-office systems aiming at the visitor or end-user. Systems are powerful tools to present options and alternatives, even give directions, but curators should be in control of the data, and visitors should be in control of the narrative created by their chosen path through the data.
Slogan #3: Embrace complexity
Enriching data is key, as heritage objects and narratives are complex objects with many perspectives and layers. The last thing we would want to do is to hide this complexity, and simplify the material until nothing more remains than a set of attractive visual images, with some tags or metadata hidden in the back. We need to give curators and heritage professionals the tools to go beyond traditional metadata, and enrich the digital objects with the stories and narratives surrounding them. In terms of the online visitors, it makes sense to have an easy starting point, but the goal would be to tempt each searcher to go further. There is no end to the wonderful narratives in the data, and the system should support users to explore multiple views and perspectives — of increasing complexity and depth — and be inspired to return for more.
Slogan #4: Art is all about interpretation
There are different definitions of heritage: the classic view is extensionalist, with the meaning coming from the object itself, leading to an object-centric meaning of heritage as captured by traditional metadata features. However, modern heritage theory has a constructivist view: the meaning of heritage is what it means to users, or group of users, or society at large. That is, a narrative-centric meaning that is “in the eye of the beholder’’ — allowing for different parallel and subjective meanings, and all of them of importance. One key consequence is that we need to bring back the social aspects into the digital realm. In fact any collaborative recommendation algorithm already recommends trails similar to those already made by other visitors, and we can explicitly show these paths of previous like-minded people. This was in fact the main idea of Vannevar Bush’s Memex: we discover useful information by following the footsteps of earlier users rather than through hierarchical controlled systems. It is these footsteps that are missing in our current tools, and adding them will make the experience feel alive and curiosity-driven rather than shallow and empty.
The conclusion is a very positive message: we invested heavily in the ground work of digitisation and made great strides to bring a wealth of content online. This is something to be proud of. I am very optimistic that we can dramatically increase the value of our tools in the coming decade to come, by building the next generation of more user-centric tools, that empower users and curators to shape the online experience far beyond the current access view, and realise the full potential of digital heritage online.
Significant amounts of cultural heritage material are readily available through online portals; however, this vast amount can be overwhelming for many users who are provided with little or no guidance on how to find and interpret this information. The PATHS(Personalised Access To cultural Heritage Spaces) project was funded to investigate ways of supporting experts (e.g., scholars and curators) and non-experts (e.g., students and the general public) with exploration and discovery within large and heterogeneous cultural collections. The project combined the efforts and expertise of academic and non-academic partners from the fields of cultural heritage, library and information science, and computer science.
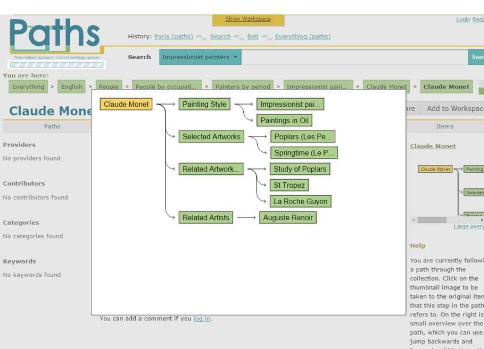
We made use of a standarduser-centred development process to create various prototype systems that involved identifying user requirements, prototyping and evaluating. Expert and non-expert users of cultural heritage were involved in establishing a functional specification for the system and evaluating prototype applications. Based on the user studies we carried out in the project, we developed a simple model of user interaction consisting of the following stages: ‘Find’, ‘Collect’ and ‘Use’. The find stage includes modes, such as search, browse, explore and discover; during collect users can gather materials for later use, supported by a workspace or bookmarking functions; and use supports making subsequent use of collected items, for example creating learning objects and narratives, and being able to share them (i.e., social interaction). A central aspect of the system was the use of paths or trails to allow users of the system to organise digital content into guided pathways, or stories, resembling exhibitions and tours commonly provided for physical collections, such as those found in museums.
A selection of 1.7 million Europeana objects was used, and semantic enrichment was carried out to support the provision of enhanced search and browse functionality. During this, two issues were identified with Europeana metadata: (i) limited information associated with many items and (ii) the lack of a unified indexing scheme across aggregate collections. These issues were addressed through semantic enrichment[1] that included: (i) identifying key entities, such as people, locations and dates; (ii) identifying the similarity between pairs of artefacts, including categorising how items were similar (e.g., similar description, similar location or similar event); (iii) identifying ‘background links’ to relevant Wikipedia articles; and (iv) the automatic creation of data-driven subject hierarchies to organise items. The enriched data was encoded using a custom format (ESEPaths) derived from >Europeana Semantic Elements (ESE).
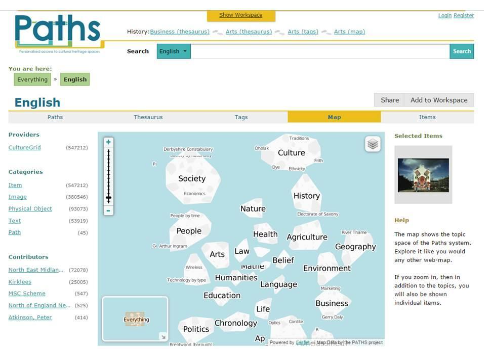
Prototype systems[2], including desktop and mobile applications, were developed to support users with exploring and making sense of Europeana materials. The prototypes included functionality to support users with the find, collect and use stages. The semantic enrichment of Europeana content enabled us to develop novel interfaces, for example map-based visualisations of the semantic space (Figure 1), support for the manual creation of guided tours or paths (Figure 2) and the use of personalised (and non-personalised) recommendations to promote information discovery and help convey the rich content of Europeana to various types of user. User interfaces consisted of the following features: (i) a standard search box and facets, (ii) map-based visualisation, (iii) a thesaurus based on a data-driven subject hierarchy, (iv) links to related items, (v) item-level recommendations, and (vi) features for creating, editing, publishing and following paths.
Videos have been created that show how users of the PATHS system can:
To sum up, the PATHS project enabled us to investigate ways of helping users with exploring large collections of digital cultural heritage, and in particular being able to make use of items of interest found during their interactions with the system to create paths or stories around topics of interest. The objectives of the PATHS project fit with themes emerging from the 2015 EuropeanaTech conference: (i) systems providing access to digital cultural heritage need to go beyond keyword search and support users with their wider information discovery and subsequent use of content; (ii) the semantic enrichment of content an important factor in being able to provide new and engaging interaction functionalities; (iii) narratives and storytelling are commonplace within cultural heritage, enabling the surfacing and contextualisation of digital content.
A summary of the PATHS project can be found in the new Facet book "Cultural Heritage Information: Access and Management”, edited by Ian Ruthven and Gobinda Chowdhury.
To find out more about specific aspects of the PATHS project, see the following publications:
Otegi, A.; Agirre, E.; Clough, P., "Personalised PageRank for making recommendations in digital cultural heritage collections," Digital Libraries (JCDL), 2014 IEEE/ACM Joint Conference on, vol., no., pp.49,52, 8-12 Sept. 2014 [Recommendations]
Hall, M., Fernando, S., Clough, P., Soroa, A., Agirre, E., and Stevenson, M. (2014) Evaluating hierarchical organisation structures for exploring digital libraries, Information Retrieval, Volume 17(4), pp. 351-379. [Automatic hierarchy induction]
Aletras, N., Stevenson, M. and Clough, P. (2013) Computing Similarity between Items in a Digital Library of Cultural Heritage, Journal on Computing and Cultural Heritage, Volume 5(4), Article 16. [Similarity of items]
Goodale, P., Clough, P., Hall, M., Stevenson, M, Fernie, K., Griffiths, J., and Agirre, E. (2013) Pathways to Discovery: Supporting Exploration and Information Use in Cultural Heritage Collections. In Proceedings of Museums and the Web Asia 2013, Hong Kong, 9-12 December, 2013. [Analysis of manually-created paths]
Agirre, E., Aletras, N., Clough, P., Fernando, S., Goodale, P., Hall, M., Soroa, A., and Stevenson, M.,(2013) PATHS: A System for Accessing Cultural Heritage Collections, In Proceedings of 51st Annual Meeting of the Association for Computational Linguistics (ACL’13), Sofia, Bulgaria, August 4-9 2013. pp. 151-166. [Project overview]
Hall, M. and Clough, P. (2013) Exploring Large Digital Library Collections using a Map-based Visualisation, In Proceedings of The International Conference on Theory and Practice of Digital Libraries (TPDL 2013), pp. 216-227. [Collection visualisations]
A freely-available web service can be accessed at:http://ixa2.si.ehu.es/paths_wp2/paths_wp2.pl
The PATHS system can be accessed at:http://paths.sheffield.ac.uk/pathsui/europeana
Keyword search technologies dominate current user environments for finding information in the exploding cyberspace. But more often than not, simple combination of keywords are not enough to express our intended search. We desperately need a more powerful and sensible way to express our wish for information as queries. Thus we have proposed so-called “Associative Search” where a query is a collection of documents and a collection of related documents is returned as the result. Full relevance feedback can be naturally realised by repeating the associative searches after modifying the selection of documents that constitute the query. Statistical metrics for measuring distance between documents and words are defined, which provides the mathematically and computationally sound basis for association.
The information stored in libraries, museums, archives, and other memory institutions are not connected to each other and feel like isolated silos. Because associative search does not require the uniform structure of metadata it is especially useful when connecting these isolated silos of knowledge. We promote research on information technology that enables linkage between unified cultural information and memories or knowledge in broader areas.
This is why computation for realising “Association” is the main theme of our research. We developed the world’s fastest association engine called GETA (Generic Engine for Transposable Association) in 2002. And since 2009, GETAssoc, the latest and web service ready version of GETA, has been freely available under the Revised BSD License. GETA and GETAssoc have been widely used to implement various information services that follow our “informatics of association” approach.
“Webcat Plus” is the service for books, covering library catalogues from 1,000 university libraries and National Diet Library of Japan. “Cultural Heritage Online” provides Japanese cultural heritage information including 115,000 items from 953 museums. In both of the services, users can use the selected items as their query to find similar items. For example, by selecting a Shino cup and a kettle, users can collect various items about tea ceremonies by using a single associative search in Cultural Heritage Online.

Two information services equipped with association can easily be coordinated dynamically through associative search. The selection in one service is summarised as a collection of words (Topic Words), and this is used to find the related items in the second service by an associative search. This mechanism for dynamic coordination can naturally be extended to federating many information services. “IMAGINE Book Search” is the first implementation of this scalable association Hub for federated association. The IMAGINE interface consists of a collection of vertical item lists, where each list corresponds to an information service. Users can select items from any list and the system returns the result full of relevant feedback from each information service. Intention from users can be captured through the selection of items, and it affects every participating service using associative searches. IMAGINE can provide a field of association where users can create context for the information they want. By starring and examining the information through IMAGINE, relevant memory from the users is built up unconsciously, which helps users be inspired in very individualistic way.

The PONGEE reading environment can be seen as a variation of the IMAGINE interface. The pages displayed from the book are automatically indexed with selected dictionaries or Wikipedia, and the sidenotes are created dynamically. Some sidenotes are just for when head terms occur, but other sidenotes are the result of associative search, using the contents from displayed pages. As users turns pages, the sidenote axes change the view. It can be seen that the connections amongst items in the sidenotes, which had implicitly been recorded in the pages, have been unearthed. It is expected that the book’s content serves as unconscious memory to enhance the users’ imagination.
Paul Clough is Professor in Information Retrieval at the Information School, University of Sheffield. He received a B.Eng. (hons) degree in Computer Science from the University of York in 1998 and a Ph.D. from the University of Sheffield in 2002. Prior to joining Sheffield he worked for British Telecommunications Plc. His research interests mainly revolve around developing technologies to assist people with accessing and managing information. In particular Paul has published work in the areas of multilingual information retrieval, information access to digital cultural heritage, evaluation of IR systems, geo-spatial search, text-based image retrieval, plagiarism detection, text re-use, and search analytics. Paul is co-author of a book on multilingual information retrieval and contributed to over 100 peer-reviewed publications. He is head of the Information Retrieval group at Sheffield and Programme Coordinator for a new MSc in Data Science.
Jaap Kamps is an associate professor of information retrieval at the University of Amsterdam’s iSchool, Project Leader for a stream of large research projects on information access funded by NWO and the EU, member of the ACM SIG-IR executive committee, organizer of evaluation efforts at TREC and CLEF, and a prolific organizer of conferences and workshops.
Akihiko Takano is Professor in Informatics of Association at National Institute of Informatics and University of Tokyo, Japan. His research interests are functional programming, program transformation and informatics of association. He has been enthusiastic about building the associative information services based on Generic Engine for Transposable Association, such as Webcat Plus, Book Town Jimbou, and IMAGINE Book Search. His team has been responsible for Japanese Cultural Heritage Online since its beginning in 2004. The team also leads the development of NHK’s Broadcasting Culture Archive.