Letter from the editors
Data quality is Europeana’s top priority. So much so that Europeana’s strategy for the next five years encourages contributing partners “to share their very best material” with us, that is, openly licensed high quality collections that people can create new things with it. An important aspect of data quality is how data for such collections can best be represented and described. The articles in this issue focuses on a variety of aspects of data quality.
In addition we invite you to read our publication “We want better data quality now”. This publication is an honest account of the roundtable discussion on data quality that happened during the EuropeanaTech conference. The write-up covers the issues that might lead to bad data quality and proposes solutions to tackle them. It also aims to help people understand what we mean by good quality data and why it’s so difficult to achieve.
We believe that the selection of articles and themes shows not only how positive and productive the community is, but also how diverse we are in our work. We hope that you find these papers interesting, engaging and relevant. Please let us know what you think by adding a comment at the bottom of the page.
Trust me if you dare: Data quality in the age of linked data
Gildas Illien, Sebastien Peyrard, BnF
Mittler zwischen Hirn und Händen muss das Herz sein”. Fritz Lang, Metropolis.
Data.bnf.fr was primarily designed to improve the visibility, legibility, consistency and (re)usability of library data on the web. It enhances discoverability of BnF services and assets on the web by building web pages that can be crawled by search engines.
Using semantic web technologies, the BnF has managed, in the past four years, to launch a service which has demonstrated encouraging outcomes according to its goals. There is no magic in this: data.bnf.fr only works properly when the source data is good. At BnF, hardcoded links between bibliographic records and person / organisation authority records have been directly created and curated by the cataloguers since 1987, in what can be called a “vintage linked data” spirit. Having those human-curated links was key to build a good service.
However, some elements were missing in the source data, and we needed to create them automatically. Data.bnf.fr found ways to use machines to improve the quality of the source data and create links. Algorithms have proved very helpful to automatically create useful links, especially between a Work and its Manifestations that are not made by cataloguers in a number of cases. This resulted in increasing discoverability by grouping all the editions of a Work (e.g. all the editions of the Three Musketeers by Dumas) in a single Work landing page. In this light, data.bnf.fr was used as a FRBRisation machine.

The structure and consistency of the source MARC data, and the existing links (e.g. between a person authority record and the related bibliographic records on one hand, and related uniform titles on the other hand) were key to making reliable links.
While this was not originally planned when the project was launched, we came to the realisation that we could make the source applications (the old catalogues coded in MARC) benefit from these data improvements.
The BnF is currently experimenting with this very process, which is one of several we are willing to explore in order to FRBRize our legacy data. The aim is to test the quality of those links and inspect how they could be processed back into the source catalogue.
Two main principles used are:
- start easy: we started with simple cases, where the Work level already existed in the source catalogue in the form of a Title Authority Record; and limit ourselves to Manifestations that only contained a single Work;
- speak the language of the catalogue (MARC) to leverage all the knowledge of the MARC Quality Assurance team without adding a “language barrier” with the RDF terminology.
This approach resulted in the enhancement of once very generic algorithms with new domain-specific rules. We also re-designed the algorithm to make it suggest, rather than stop, whenever it couldn’t decide between different possible works. In this light, the machine makes suggestions for the human expert to decide upon.
Another result was that the QA team decided to accept a certain level of error: if the algorithm solves a huge majority of the cases, we decided we would go for it and correct whatever specific errors we could find afterwards.
This resulted in an important shift in terms of relationships between machines and humans:
- make the algorithm “more like a librarian” by teaching it how to better parse MARC data;
- make the QA team shift from being data correctors to machine instructors as, instead of correcting the records by hand, they told the algorithm how it could work better.
The next steps to use data.bnf.fr algorithms as a FRBRisation machine for our source data will be the following:
- expand the manifestation-to-work links to aggregate (where one manifestation contains many works);
- create works whenever they do not exist
- last but not least, de-duplicate sparse records.

The risk with data.bnf.fr, a new service built on source MARC data, was instigating a divorce between the cataloguers and the machines. Though initiated with an ROI mindset, we learned a lot more during the process. With this “feedback” approach, we made data.bnf.fr and the catalogue — and the team’s — dialogue, more positive than ever, hybridising our way into building a better service together. In the end, a much wider range of people now completely own this approach of increasing discoverability, FRBRising our catalogue with tools, and putting librarianship, data QA experts and cataloguers back in charge in an approach that they understand and they can own.
In the end, we discovered that data quality was so much more than data knowledge, the technology, tools, and FRBRisation of cataloguing alone. In the end, data quality cannot happen without love for data and people's enthusiasm !
Clean data with OpenRefine
Ruben Verborgh, iMinds
The tool of the trade
Your data is dirty. And so is mine. It's not a shame to admit it—but how do we make it better? For me, cleaning data is like washing the windows of a skyscraper:
- You can never remove all spots.
- By the time you get to the top, you'll have to start all over again at the bottom.
- …everything becomes so much easier if you have the right tools!
For cleaning, linking, and enriching data, OpenRefine is definitely the right tool. It is an open-source software package that lets you handle large datasets with ease—no IT knowledge is needed. Basically, OpenRefine is like Excel on steroids: it offers you one large table in which you can manipulate data with a few clicks and key presses. It takes only a few minutes to save you several hours.
Getting up and running
Even though it used to be called Google Refine, OpenRefine is free software that runs on your local machine. This means you don't have to send your data anywhere. Just visit openrefine.org, click the Download link, and you'll be up and running in minutes. OpenRefine loads in your browser, but runs entirely on your computer; no data ever leaves it.
Meet your data
The first step of improving your data is getting to know it. OpenRefine provides you with two handy tools for that:
- Filters allow you to see the records you are interested in. For example, you can create a text filter on a column with object titles. When you then type in “rockets”, you see only those objects that have this word in their title.
- In order to use filters, you need to have an idea of what data you have. But what if you don't? Facets partition your dataset automatically. For example, if you have a keywords field, a text facet will automatically group your keywords and allow you to see specific objects. Which keywords are there and how many items use them? OpenRefine tells you in the blink of an eye!
Find and correct mistakes
Suppose each of your records has one or more keywords. They are the result of a labour-intensive process: every keyword was typed by hand. What if there are spelling mistakes? If you search for, let's say, “photograph”, but the record reads “hpotograph”, you won't find it. Fortunately, OpenRefine has a built-in cluster function: it looks for those values that are similar—but not entirely the same. You can then pick the right spelling, so that all those “hpotographs” are gone once and for all.
Now imagine that you needed to do that manually… OpenRefine excels at automating such tedious manual labour!
Enough said—let's do this!
Try the above steps yourself on one of your own datasets. If you don't have one on hand, we suggest the collection metadata of the Powerhouse Museum, which contains several nice examples.
The screencast below guides you through your first steps of OpenRefine.
Have fun getting your hands dirty with data!
And remember, “clean data” is an action, not a given thing.
Beyond the space: the LoCloud Historical Place Names microservice
Rimvydas Laužikas, Justinas Jaronis, Ingrida Vosyliūtė, Vilnius University Faculty of Communication
What are Historical Place Names?
Historical Place Names (HPN) are not contemporary place names. Rather, they are place names which existed in history and are mentioned in different historical sources. For instance, Camelot or Atlantis. These two places appear in historical written texts, historical maps (cartographic information) and visual items (iconographical information depicted in landscape paintings, town panoramas, etc.) but never in reality. However, a Historical Place Name can also very well be a place that has actually existed or still exists but under a different name. In other words a Historical Place Name is a place appellation, which could refer to several places, and its application may have changed over time (e.g. Colonia 52 AD and Köln 2015 AD.This concept of place name is described in the CIDOC-CRM data model as E48. Place name). It may also refer to time as a historical identifier which may discern several places (e.g. medieval and contemporary Vilnius as different polygons, the concept is described in CIDOC-CRM as E42. Period) and (or) as a kind of immovable heritage as “non-material products of our minds” (e. g. linguistic origin and analysis of HPN for understanding lost native cultures.The concept is described under E28 Conceptual Object in CIDOC-CRM).
What are the problems with HPN?
During digitisation, when one transcodes reality from analogue to digital, Historical Place Names are used as identifiers for a certain historical space. HPN becomes a link between past reality and contemporary virtuality, ensuring quality of digitisation, interoperability of reality and virtuality, internal interoperability of data within the information system and external interoperability of several systems, as well as efficient communication of digital data.
However, it is also important to take into account the “human factor” of HPN. We call this “historical or cultural multilingualism”, meaning terminological differences within common language. This is determined by the cultural differences of various nations (e. g. Greece in English and Ελλάδα in Greek). On the other hand, understandings of the historical space are marked through nationalistic historical narratives, thus having a huge impact on history and social geography (e. g. differences between German Königsberg and Russian Калининград).
Computing technology provides the possibility to maximise the objectivity for geographical representations in reality (e.g. using GIS data). Paradoxically, during the digitisation of cultural heritage, we link it less to modern geographical space realities than to the historical spaces of the 19>th century that were marked by historical narrative myths. For example, during March 2015 on Europeana.eu there were only 8,731 objects linked to the place named Gdansk, however the Danzig name had 34,449 objects associated with it.
What is the LoCloud HPN microservice?
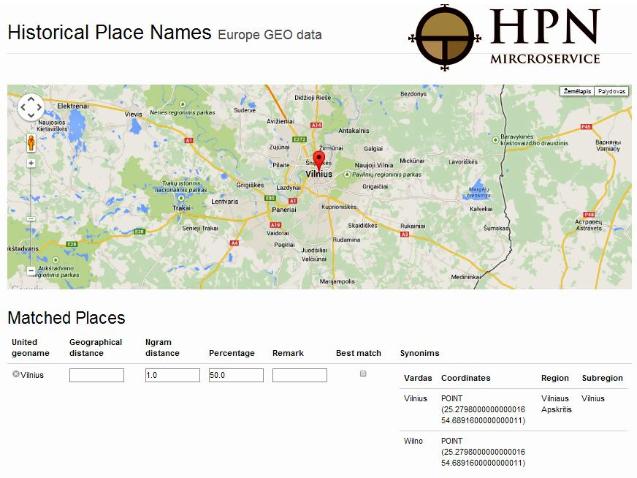
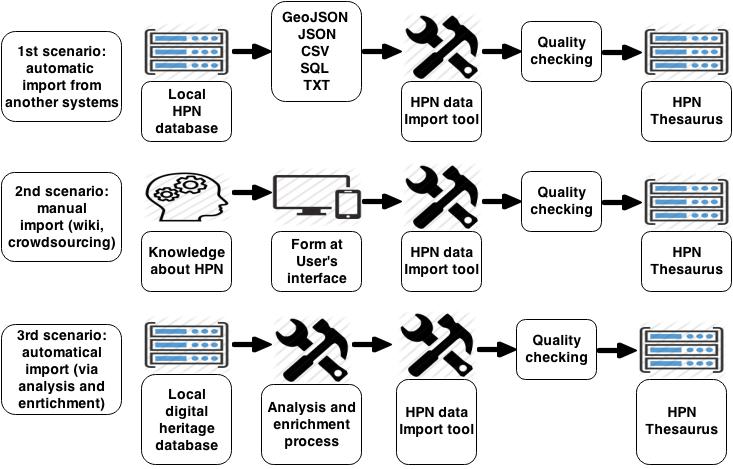
The LoCloud HPN microservice, developed by Vilnius University Faculty of Communication in collaboration with LoCloud partners, is a semi-automatic historical geo-information management tool and web service. It enables local cultural institutions to collaborate on crowdsourcing a thesaurus of HPNs, enriching metadata about cultural object with HPN references, and re-using historical geo-information across applications.
HPN microservices are oriented towards providers and aggregators rather than end-users. They perform the following functions:
- Visualisation, crowdsourcing and enrichment of providers’ and aggregators’ historical geo-data via
- automatic transfer of historical geo-data from local/international databases and information systems to the HPN Thesaurus. The system can map and transfer historic geo-data from local systems to the LoCloud HPN Thesaurus, importing geo-data inGeoJSON,JSON, CSV,SQL, TXT formats and matching it with historical geo-data already in the HPN Thesaurus using an automatic data import tool.
- manual provision of historical geo-data via a dedicated user interface.
The HPN enrichment scenarios are presented below:
2. HPN interoperability provision is achieved via automatically checking the transferred data and linking local HPN with contemporary geographical names during the metadata harvesting process. It connects various forms (historical, linguistic, writing system) of historic place names in local systems with contemporary place names and GIS data as latitude and longitude. Geonames are stored in the HPN Thesaurus (which connects historic name with current name and/or administrative dependences, or connects different variations of the same place name, etc.). This is based on an integrated algorithm that rationalises and reconciles similar place names, by estimating similarities between names and geographic coordinates. The algorithm also performs an accuracy check (e.g. if a name and relevant coordinates are exact, it is ranked at 100%; if the name is exact, but the coordinates deviate by 50%, it would be 75%; if the name is not exact and the coordinates do not match the allowed deviation, it will be 0%). The whole process of analysis and enrichment is presented below:
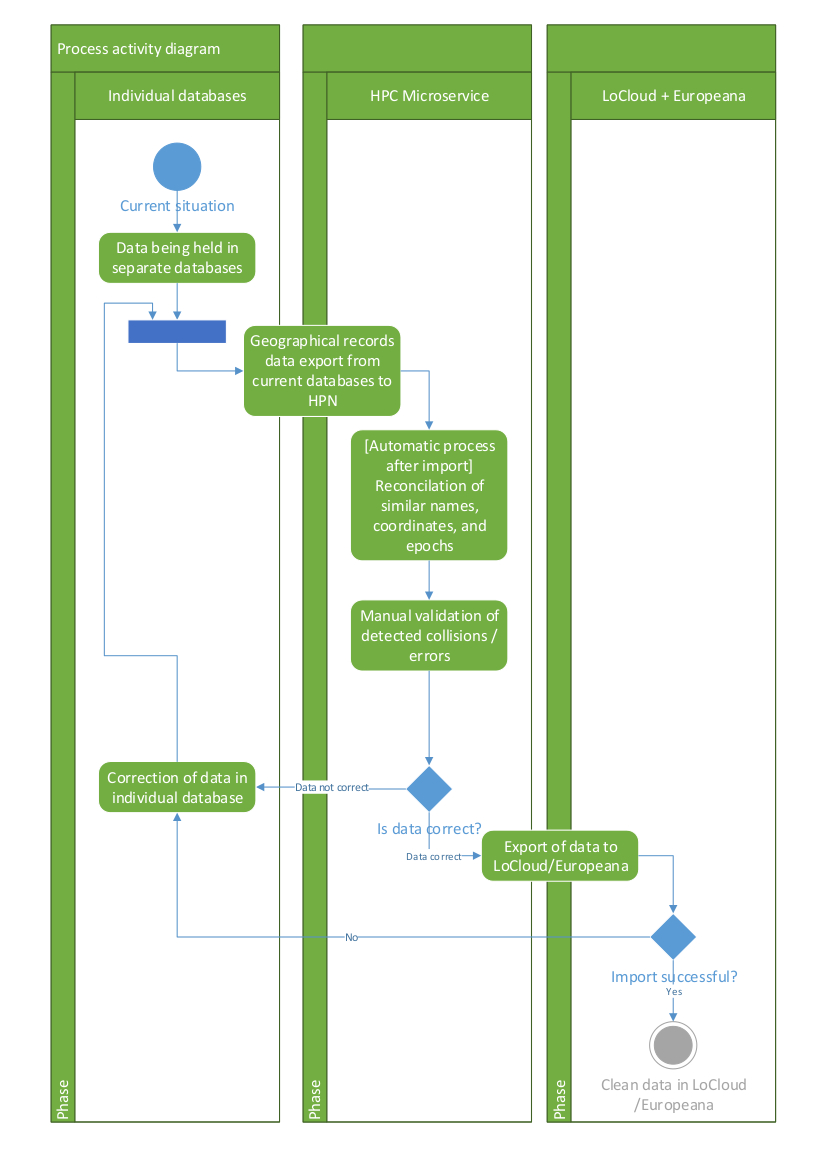
More technical documentation about the HPN microservice can be found at http://tautosaka.llti.lt/en/unitedgeo and http://support.locloud.eu/tiki-index.php?page=HomePage.
How could the LoCloud HPN microservice be used?
The LoCloud HPN microservice could be used by local history researchers (as unregistered users) to verify the availability of a Historical Place Name in the LoCloud HPN Thesaurus or to get information about the interconnection of HPN with contemporary place names, linguistic variations and geographical coordinates of place names. The service can also support the crowdsourcing of new Historic Place Names to augment the LoCloud HPN Thesaurus. A visual example of HPN in the microservice is presented below:
In a more controlled setting, the service can also be used by heritage database administrators (as registered users) in order to:
a. export selected LoCloud HPN Thesaurus datasets and make them available for enriching the other applications (for instance local systems);
b. interconnect contemporary place names, or add different historical and linguistic forms as well as geographical coordinate for place names in the system;
c. collaborate in developing the LoCloud HPN Thesaurus by contacting us and sending local data to be integrated as a batch by the service.
Biblissima and Data Modelling
Matthieu Bonicel, Stefanie Gehrke,Biblissima
The objective of the Biblissima project is to enrich and bring together existing data on medieval manuscripts and early printed books, their former owners and the transmission of texts and collections. The Biblissima portal aims to provide access to data deriving from more than 40 different databases via a single access point.
For data mapping to a common format, the ontologies CIDOC CRM and FRBRoo were chosen. Both approaches are event-centric, especially FRBRoo, which combines the CIDOC CRM approach with the vocabulary for the transmission of work (W-E-M-I, used in the library domain). It was considered to be relevant for a project focused on the history of collections and the transmission of texts. Furthermore, the outcome of the EuropeanaTech Task Force “EDM – FRBRoo Application Profile” was taken into account.
In addition, a thesaurus compliant to ISO 25964, containing technical terms and a set of descriptors will be included. It is currently under development and is making use of the open-source software GINCO, developed by the French Ministry of Culture.
The Biblissima data will be retrievable via a portal, providing search facilities for current and former shelfmarks, authors and contributors, work titles, places and dates. To give an impression of these features, an online prototype gathering data from two iconographic databases, Initiale (IRHT, Paris) and Mandragore (BnF), was developed using the semantic web framework CubicWeb and will be available in spring 2015.
Within the context of the prototype, the metadata related to specific illuminations (e.g. the illumination on folio 11r of the manuscript Français 5594) is mapped in the following way:
An instance of the class bibma:Illumination (subclass of crm:E26_Physical_Feature) is linked to the bibliographic record (instance of crm:E31_Document) http://mandragore.bnf.fr/jsp/feuilleterNoticesImageArk.jsp?id=44206 via the property crm:P70_ is_documented_in(a bibliographic record is an instance of crm:E31_Document).
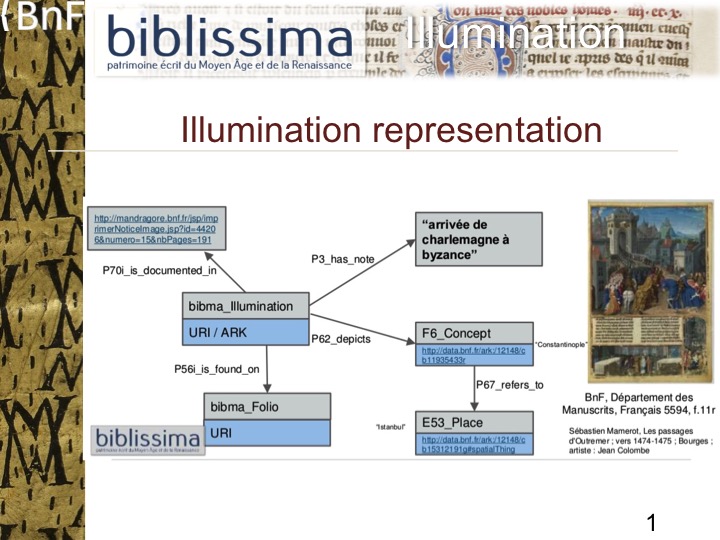
In the sample above, the class bibma:Illumination is linked to the Concept http://data.bnf.fr/ark:/12148/cb11935433r (the skos:Concept “Constantinople” is also an instance of crm:E89_Propositional_Object) via the property crm:P62_depicts. The Concept is then linked to the Place http://data.bnf.fr/ark:/12148/cb15312191g (the place called “Istanbul”, instance of crm:E53_Place) via the property crm:P67_refers_to .
Furthermore, this bibma:Illumination is linked to the Folio URI (might be http://www.biblissima-condorce..., that is in our example the “Folio 11r”) via the property crm:P56_is_found_on.
Finally, the bibma:Illumination is linked to the note statement “arrivée de charlemagne à byzance” via the property crm:P3_has_note.

As an instance of the class bibma:Manuscript, a medieval manuscript, is frbroo:F4_Manifestation_Singleton (“This class comprises physical objects that each carry an instance of F2 Expression and that were produced as unique objects, with no siblings intended in the course of their production.”). It carries a frbroo:F2_Expression that realises a frbroo:F1_Work. In our example, the manuscript “Français 5594” carries a realisation of the frbroo:F1_Work “passages oultre mer” (URI could be http://data.bnf.fr/ark:/12148/cb16712705j) written by Sébastien Mamerot. The expression carried by the manuscript is composed of both text and illuminations. The latter were created by Jean Colombe.
Not covered by the prototype but already in preparation is the modelling of the inventories’ content. Several sales catalogues and inventories are serving as sources for metadata about collections and their objects at a certain time.Montfaucon’s Bibliotheca Bibliothecarum manuscriptorum nova, for example, lists a manuscript that is considered by a researcher as being identical to the manuscript currently kept by the Bibliothèque Municipale d’Avranches carrying the shelfmark “BM 161”. We propose to model this identification as an event by using the class crm:E13_Attribute_Assignment in order to relate the inventory’s entry about the manuscript to the physical object kept in the Avranches library today :

The class bibma:Item (still in discussion) could be linked to the class crm:E13_Attribute_Assignment via the property crm:P140i was attributed by. In the same way the class bibma:Manuscript is linked to the class crm:E13_Attribute_Assignment via the property crm:P141 assigned.
Suggested extensions to both CIDOC-CRM and FRBRoo to match Biblissima’s needs will be published on the new website of the project to be released later in 2015. An instance of Ontology Browser will be set up to present this modelling.
For more information see the recent presentations on slideshare:
Achieving interoperability between CARARE schema for monuments and sites and EDM
Valentine Charles, Europeana Foundation and Kate Fernie, 2Culture Associates Ltd
CARARE was a three-year project that made digital content from the archaeology and architecture heritage domain available to Europeana. CARARE took advantage of the Europeana Data Model (EDM) to model the network of connections existing between the heritage assets themselves (such as monuments, buildings) and other resources related to these assets. These resources specifically describe either real objects with their digital representations or born-digital objects. In addition, it used the EDM contextual classes to model entities such as places and concepts. When mapping its metadata to EDM, the project had to face a few challenges that are representative of the difficulties data providers can encounter when mapping their data to EDM.
Among these issues is the definition of the Cultural Heritage Object (CHO) mapped to the class edm:ProvidedCHO. EDM allows for the distinction between “works”, which are expected to be the focus of users’ interest, and their digital representations. Therefore, data providers are asked to define the focus of the description according to their represented domain. For the CARARE project, the CHO representing the archaeological and architectural domain, can be:
- Heritage assets, such as monuments, buildings or other real world objects, identified by a set of particular characteristics that refer to their identity, location, related events, etc. Information carried by a heritage asset includes: textual metadata (such as title, etc.), thumbnails and other digital objects.
- Real world cultural objects with their digital representations which provide other sources of information about the heritage asset (historic drawings and photographs, publications, archive materials etc.).
- Born-digital resources related to these objects, such as 3D models.
The datasets aggregated by CARARE present a lot of differences in terms of data granularity. When converting this data to EDM, CARARE had to make decisions that were specific to each dataset. Three scenarios were defined:
- Scenario 1: a heritage asset is represented by a series of other cultural heritage objects such as historic drawings, books and photographs which are published online with simple descriptive metadata. A provided CHO is created for the heritage asset and is aggregated together with 'edm:WebResources' created for each of the other resources.
- Scenario 2: a book, photograph or map representing a heritage asset and contained in more than one CARARE object. Each heritage asset creates a provided CHO and each cultural object creates a provided CHO. Any duplicate provided CHO created as a result of the book or picture being referenced by more than one heritage asset is removed.
- Scenario 3: a heritage asset such as a building is referenced by a series of cultural objects such as historic drawings, books and photographs in a CARARE object. The heritage asset and each of the cultural object give rise to provided CHOs.
Achieving interoperability between CARARE schema for monuments and sites and EDM from Valentine Charles
In conclusion, CARARE provides a better “profile” for archaeology/architecture heritage and richer metadata for Europeana. The solutions found as part of this data modelling effort prompted updates to the CARARE schema which is now re-used in the 3D icons project.
The full case study can be accessed here: http://pro.europeana.eu/carare-edm.
Contributing authors
Matthieu Bonicel is a curator at the Bibliothèque nationale de France’s Manuscripts department where he is in charge of digitisation and information technologies. He is also the coordinator of Biblissima, a Digital Observatory for the Written Heritage of the Middle Ages and the Renaissance.
Valentine Charles is the Data Research & Development coordinator for Europeana. She is responsible for advising, sharing knowledge and communicating Europeana’s scientific coordination and R&D activities. She is also coordinating the further development and adoption of the Europeana Data Model.
Kate Fernie is a consultant with a background in archaeology who has been involved in Europeana and digital libraries projects since 2004. She is currently the project manager for LoCloud and participates in the ARIADNE research infrastructure. She is one of the authors of the CARARE metadata schema and works with people who are using the Europeana Data Model.
Stefanie Gehrke has been metadata coordinator of the équipex Biblissima since 2013. Before that from 2010 to 2012, she participated in the project Europeana Regia, in the work package responsible for metadata.
Gildas Illien is Director of the Bibliographic and Digital Information Department at the Bibliothèque nationale de France (BnF). This department is responsible for metadata standardisation, coordination and diffusion. It is also a strong driver in transforming BnF heritage catalogues and metadata into linked open data and services. He has an academic background in political sciences and communications.
Justinas Jaronis is a Director of “Atviro kodo sprendimai” Ltd. He has designed and administrated the biggest interdisciplinary information system in Lithuania - “Aruodai” IS.
Rimvydas Laužikas is an Associate Professor of digital humanities and the Head of the Department of Museology in the Faculty of Communication of Vilnius University. He has represented the Faculty in European projects such as Connecting Archaeology and Architecture in Europeana, Local content in a Europeana cloud, and Europeana Food and Drink.
Sébastien Peyrard is a metadata analyst at BnF, in the Bibliographic and Digital Information Department. Since 2014, he has worked as a linked data expert at BnF. He is part of the team behind data.bnf.fr and is specifically working on the relationship between this service and the BnF’s traditional catalogue. He is the librarian coordinator for ARK implementation at BnF.
Ingrida Vosyliūtė is a doctoral student in the Faculty of Communication of Vilnius University. She has collaborated in European projects such as Connecting Archaeology and Architecture in Europeana, Local content in a Europeana cloud, and Europeana Food and Drink.
Ruben Verborgh is a researcher in semantic hypermedia at Ghent University – iMinds, Belgium, where he obtained his PhD in Computer Science in 2014. He explores the connection between semantic web technologies and the web’s architectural properties, with the ultimate goal of building more intelligent clients. Along the way, he became fascinated by Linked Data, REST/hypermedia, web APIs, and related technologies. He co-authored a book [1] on using OpenRefine to clean and publish datasets, and a handbook on Linked Data[2]. You can read a sample chapter from Ruben’s book Linked Data for Libraries, Archives and Museumshere and browse a sample of his book on OpenRefine here.
[1]Seth Van Hooland and Ruben Verborgh (2014). Linked Data for Libraries, Archives, and Museums, http://book.freeyourmetadata.org/
[2]Ruben Verborgh and Max De Wilde (2013). Using OpenRefine, https://www.packtpub.com/big-d...