What is your current academic position and what is your research focus?
I am a post-doctoral researcher in the Digital Humanities Laboratory at the École Polytechnique Fédérale de Lausanne (EPFL). My research explores ways of extracting semantic information (citations, for example) from large collections of texts and how this changes the way scholars can access, read and analyse textual corpora. I have a background in Classics (Ancient Greek and Latin), meaning a substantial part of my digital humanities research and teaching has been devoted to Classics and Archaeology, but more recently I've been working on similar problems related to History. In the last project, Linked Books, we developed a citation index of the literature about the History of Venice - the Venice Scholar – a sort of Google Scholar for Humanities scholars. Currently, I'm working on Impresso: Media Monitoring of the Past, a project where natural language processing (NLP) specialists, computational linguists, designers and historians are collaborating to co-design a new tool for working with a very large corpus of digitised newspapers.
How has Europeana helped you to achieve your research goal?
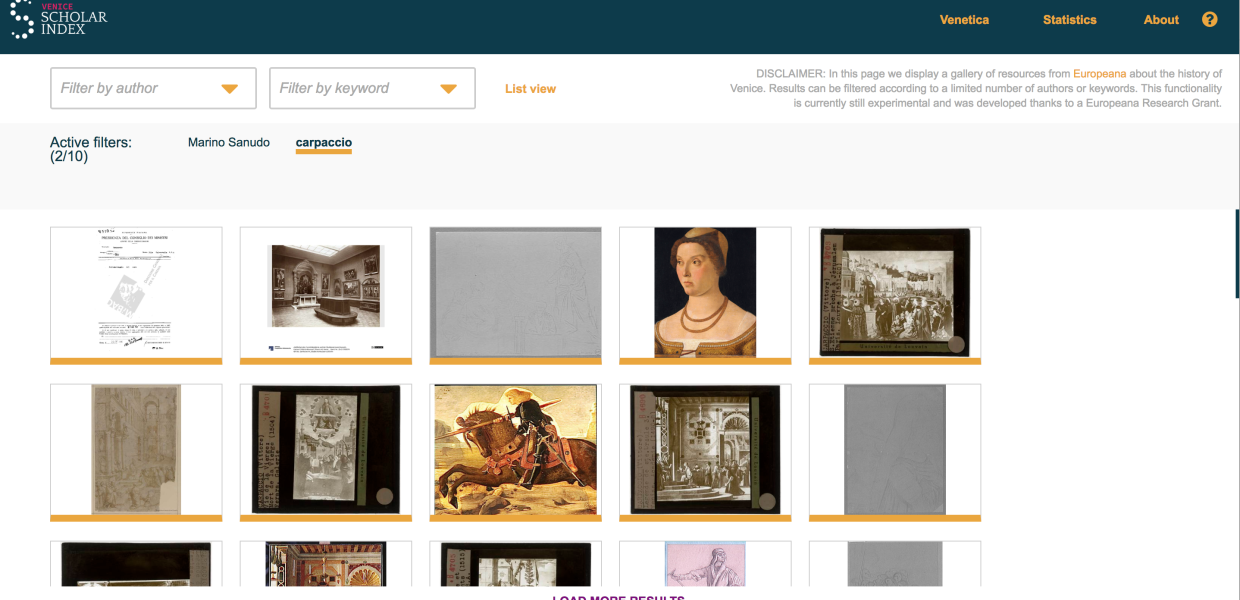
Europeana research funds (8,000 EUR) enabled us to add two new important features to a tool I had co-developed, the Venice Scholar, which makes the user experience of our users even richer. Any author or publication in our citation index now comes with a new sidebar where relevant objects from Europeana are dynamically retrieved and displayed (see Marino Sanudo's page for an example). Moreover, the Europeana grant made it possible to design and implement a new section, that we called Venetica, conceived as a visual gallery to present a thematic selection of Europeana contents. Users can pick authors and keywords related to Venice's history and start exploring Europeana's contents, without even leaving the Venice Scholar platform.
How did you discover the Europeana Grants Programme and why did you decide to apply for it?
Giovanni Colavizza, my colleague on the Linked Books project, alerted me to the Europeana call. Together we decided to apply, as this seemed a unique chance to connect the tool we'd just finished developing (the Venice Scholar) with Europeana. There is a large number of digital objects related to the literature about Venice in Europeana, and these materials can be very interesting for people who use Venice Scholar. We just needed a way of making this connection, of uncovering potential links between the two datasets.
How does access to digital cultural heritage influence your research?
In my research, the availability of digital resources through libraries, archives and museum is everything: no (digital) contents, no mining!
The increasing volume of digital resources available means I'm constantly faced with the issue of ‘finding solutions that scale’. The type of access to digital content offered by heritage institutions also varies a lot. Working with well-designed APIs, like those offered by Europeana, can almost be considered a luxury. Often – if not most of the time – we are talking to human (instead of programming) interfaces, parsing exotic or idiosyncratic metadata formats, or scraping contents from static web pages. We’d just love to have an API to query. Cultural heritage institutions are a gold mine of carefully crafted and well-structured metadata, which are an essential resource for anyone working in the field of information extraction. Often, the issue is simply of not being provided with the appropriate ways of accessing those gold mines.
Find more information in Matteo Romanello’s report below, explore the project website, and hear from our previous grant winners Krista Murchison and Caterina Preda.