Books, manuscripts, historical newspapers and many other kinds of textual cultural heritage objects (CHOs) provide valuable input for a broad range of research topics. The mission of CLARIN is to makes digital language resources available to scholars, researchers, students and citizen-scientists from all disciplines. As partners in the Europeana Digital Service Infrastructure (DSI), Europeana and CLARIN have worked together to embed cultural heritage material into CLARIN’s infrastructure. Based on the experience gained during the pilot, and building on improved dissemination services and metadata quality offered by Europeana, CLARIN recently carried out a new evaluation of the available datasets and made a new selection. The selection process focused on full text content such as digitised books, periodicals and newspapers with textual content obtained through optical character recognition (OCR). Other types of objects that were also considered are high resolution scans of manuscripts and speech audio. In order to qualify, resources had to be directly available in their raw form and have no legal restrictions for reuse. Currently, 22 collections containing about 135,000 cultural heritage objects have been identified as meeting these criteria.
Connected tools for seamless processing
After finalising the selection, CLARIN set up a mechanism for regular retrieval of metadata for the selected collections. Once retrieved, the metadata is ingested into CLARIN’s language resource catalogue, the Virtual Language Observatory (VLO).
Straightaway, we can see that the newly introduced resources provide a substantial contribution to the number of relevant search results for certain queries. For example, searching for Slovenian text resources, almost all of the 73,000+ results originate from a Europeana data provider - in this case the Digital Library of Slovenia. Similarly, the availability of Hungarian and Polish text resources have been greatly enhanced.
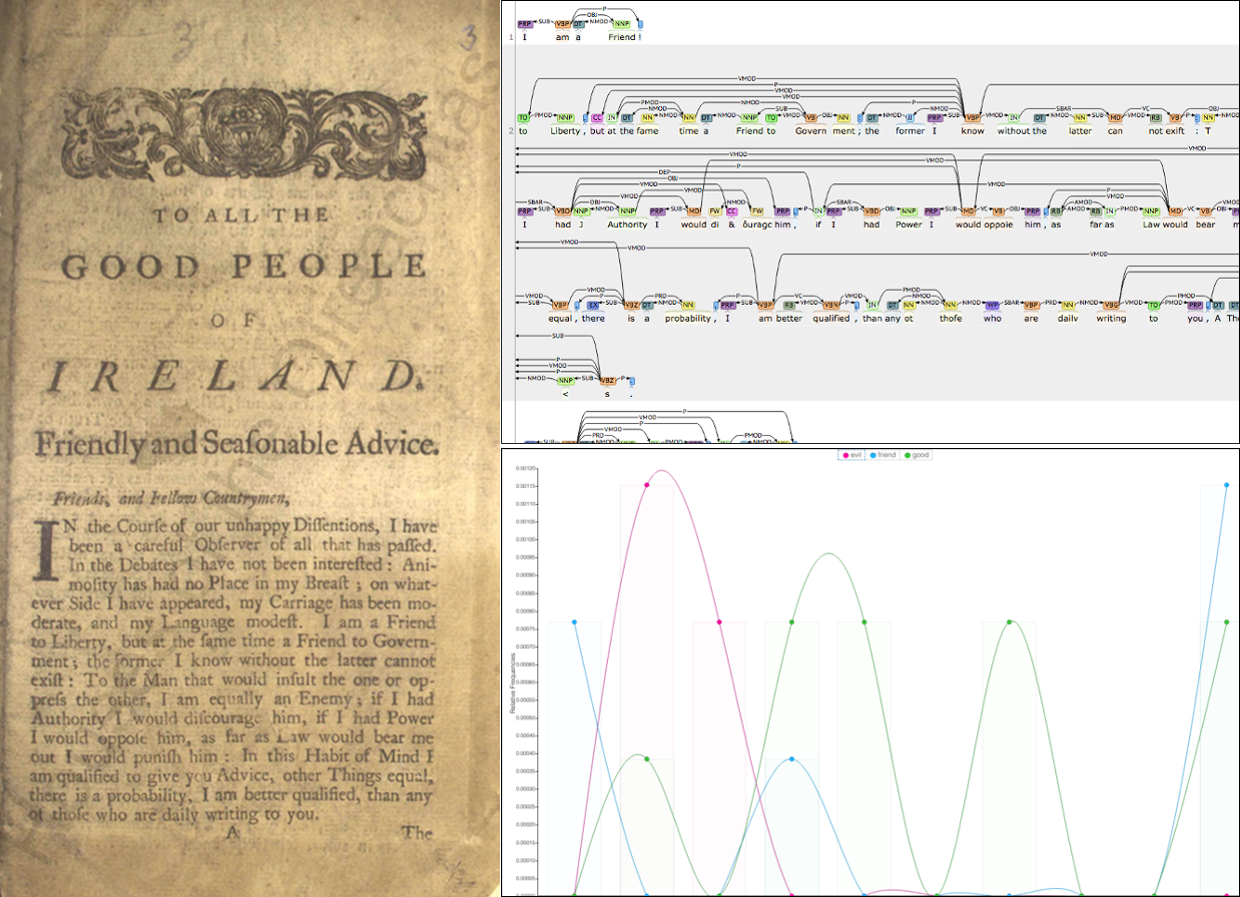
As well as offering researchers a familiar way of discovering cultural heritage objects relevant to their research, the VLO also provides a direct path to analysis of discovered resources. For example, this 18th century pamphlet, offered as a PDF with embedded full text content by the Irish Manuscripts Commission and the Oireachtas Library, can now be found via the VLO.
By going to the Resources view and selecting the Process with the Language Resource Switchboard option, you see a list of invokable tools - nine at the time of writing. Among the options are grammatical analysis through the Weblicht Dependency Parsing chain and the Voyant suite for computer-assisted text analysis. Note that, although the LRS can be invoked for any resource, it does not have linked tools for all language or resource types, and that a file size limitation applies in the current version. An upcoming version will see this limitation lifted.