Issue 8: TPDL
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community.
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community.
The annual Theory and Practice of Digital Libraries is a key event for digital libraries and heritage institutes from around Europe and the world. The event brings together hundreds of individuals from very different organizations, who for several days share best-practices and innovative approaches to sharing, cataloging, enriching.
Since Europeana’s conception it has been present at TPDL (formerly known as the European Conference on Digital Libraries). Over the years countless EuropeanaTech community members have presented at, attended or were involved with the organization of the forum.
This year in Thessaloniki, Greece several papers related to Europeana were presented along with several sessions being chaired by EuropeanaTech community members. In this issue of EuropeanaTech Insight we highlight these talks and several others presented by members of the EuropeanaTech community. We are all already looking forward to the 22nd edition of TPDL!
Europeana will be celebrating its 10th anniversary next year. At such a respectable age for a digital library, museum or archive, it’s time to look back on its developmental stages, progress and achievements. The project documented herein looks at evaluations of the Europeana Collections portal, trying to trace developmental stages and changes over time.
As a first step, we conducted a study to assess the evaluations of Europeana and the outcomes from Europeana’s launch in 2008 until early 2017. Based on an often-used framework, we categorized the methods and criteria as well as the perspectives used to assess Europeana and its components during the last decade. This text is based on a paper for the TPDL conference this year as well as the presentation given during the conference.
We used Tefko Saracevic's Digital Library evaluation framework (2000) that defines five elements for describing digital library evaluations. The Construct defines the focus of the evaluation, i.e. the object of evaluation. The Context is the perspective used for the evaluation, which can be user-centered, system-centered or interface-centered. The Methodology used as well as the Criteria and their Measures are additional components of each Digital Library evaluation.
55 studies focusing on evaluations of Europeana were selected dating from the past decade. To accumulate these studies, we used a list of evaluations in the Europeana community aggregated by the Europeana Task Force for Enrichment and Evaluation. In Google Scholar and Web of Science, we searched for further publications. We found three different types of evaluations: * 38 evaluations with Europeana as the object, * 3 evaluations using Europeana data, and * 14 meta-studies, which named Europeana as a use case. Our detailed analysis focused on those 41 evaluations, which were not meta-studies.
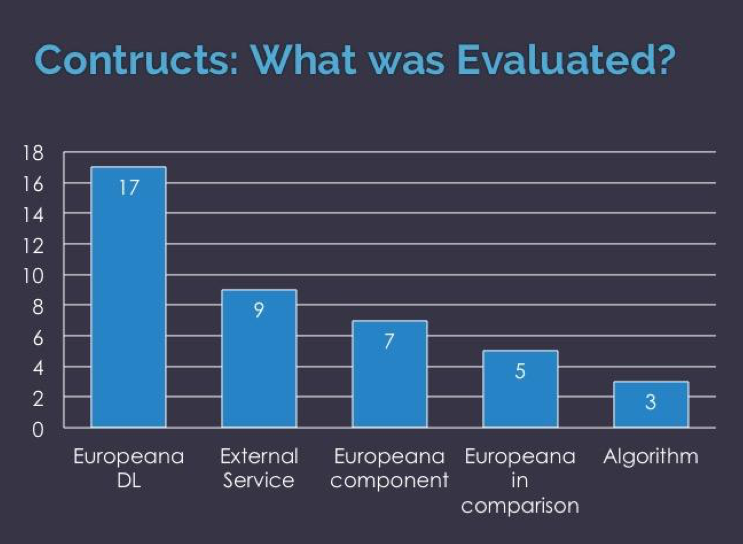
Figure 1 shows what the focus of evaluation was across the studies. Out of 41 studies, 17 evaluated the Europeana digital library holistically, nine evaluated external services, which were developed for Europeana, and seven assessed a particular component such as the metadata.
Constructs.jpg
FIG1. Categories of evaluation focus and number of studies per category.
Figure 2 shows the perspective of the evaluations. Most of them were system-centered, whereas 7 studies evaluated from all perspectives.
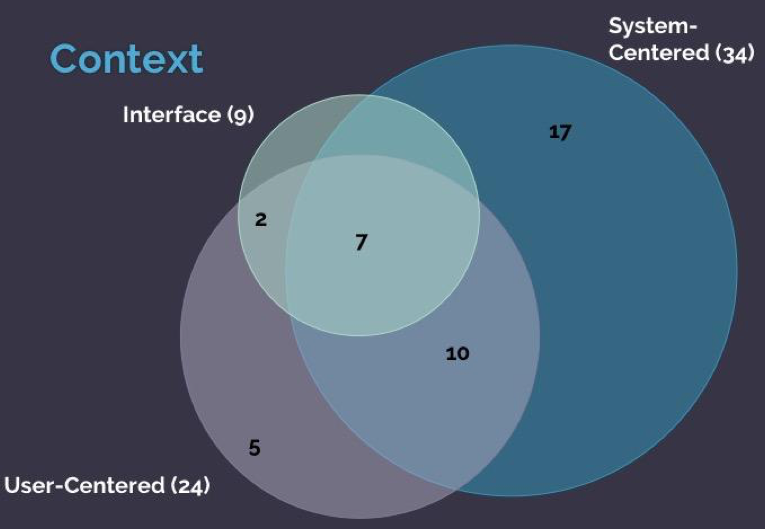
FIG2. Perspectives of evaluations and their overlap.
Most of the studies define their own criteria and measurement scales. Often, this information was not visible from the papers. In terms of methodology used, we found the categories described in table 1:
Method | Description | Number |
Criteria-based | Certain criteria were determined to assess a service or algorithm. | 16 |
Gold standard-based | Use of a manually created gold standard to assess performance. | 9 |
Logfile analysis | Uses an automatically created log file of user interactions | 8 |
Usability study | Several methods to assess usability of a service, e.g. user studies, interviews, surveys. | 7 |
Impact study | Expert assessment of the overall value of a service. | 2 |
Tab1: Methods used for evaluating Europeana.
To summarize, we found that studies with a focus on the system perspective prevail. The institutional and societal perspectives were less focused on than the individual user perspective. Studies on the overall impact of Europeana are still rare, especially as success criteria of cultural heritage systems still need to be defined and standardized. As a starting point, the Europeana Impact Framework now works on establishing these definitions and standards for assessing impact.
To benefit from evaluations in a more sustainable manner and to be able to trace developmental changes more consistently, we suggest a Europeana Evaluation Archive, which enables tracking improvements over time. We found a lack of published documentation of evaluations for many of the Europeana satellite projects. Moreover, the studies were conducted on Europeana in stages of maturity that cannot be reproduced. Commonly, evaluation studies are not linked or even dated to a particular Europeana version, making it hard to reproduce or even to retrace their results or insights. To improve that situation, we suggest that changes in Europeana should be tracked and evaluation studies should be linked to a particular version. Those new versions with changes that result from evaluations should also be linked to the evaluation to enable a clear relationship to impact indicators. Additionally, standardizing evaluations will enable comparisons among evaluation results and over time.
References:
Isaac, A., Manguinhas, H., Stiller, J., & Charles, V. (2015). Final Report on Evaluation and Enrichment (Task Force on Enrichment and Evaluation). Europeana.
Saracevic, T. (2000). Digital library evaluation: Toward an evolution of concepts. Library Trends, 49(2), 350.
Introduction
Web archives created by the Internet Archive (IA) (https://archive.org), national libraries and other archiving services contain large amounts of information collected for a time period of over twenty years. These archives constitute a valuable source for research in many disciplines, including the digital humanities and the historical sciences by offering a unique possibility to look into past events and their representation on the Web.
Most Web archive services aim to capture the entire Web (IA) or national top-level domains and are therefore broad in their scope, diverse regarding the topics they contain and the time intervals they cover. Due to the large size and the broad scope it is difficult for interested researchers to locate relevant information in the archives as search facilities are very limited. Many users are more interested in studying smaller and topically coherent event-centric collections of documents contained in a Web archive [1,2]. Such collections can reflect specific events such as elections, or natural disasters, e.g. the Fukushima nuclear disaster (2011) or the German federal elections.
Event-Centric Collection Extraction
Events are typically characterized through a certain date or a time interval. Nevertheless, event-related documents also appear outside of this time interval. For planned and regularly recurring events such as sports competitions or elections, relevant documents are often published in advance of the actual begin of the event during the event lead time, and are still published after the event completion during the cool-down time period. For non-recurring events such as natural disasters, event-related documents are published from the start of the event and during the cool-down time. Given an event of user interest and a large-scale broad-scope Web archive, our goal is to generate an interlinked collection of documents relevant to this event. A naive approach to create an event-centric collection is to iterate through all documents in a Web archive and check their relevance using an automatic method. However, this is computationally expensive and does not scale. While a full-text index could reduce the iteration cost, it requires high up-front computation [3]. Furthermore, such an index can only be used to retrieve individual documents instead of interlinked documents. In [4] we proposed an alternative approach that uses the hypertext characteristics of the archived documents by adapting focused Web crawling. A focused Web crawler collects documents by recursively following the prioritized links from a Web document to other documents within the archive.
Relevance Estimation
For Web Archive re-crawling we need to prioritize the URLs during the focused crawl to effectively extract event-centric collections based on a relevance function. The relevance function we proposed is a linear combination of the temporal and topical relevance of a Web document.
Temporal relevance is estimated based on a time point associated with the Web document (e.g. the creation or capture date). We assume that in general the relevance of documents decreases rapidly as the distance to the event time increases and therefore define a temporal relevance function based on the exponential decay function.
The topical relevance of Web documents is estimated by computing the similarity of the textual content of Web documents to the topical scope of the collection. The topical scope is specified primarily through a set of reference documents that describe the event (e.g. Wikipedia pages). In case of an ambiguous event description or if the scope of the collection should be narrowed down further, keywords can be provided to clarify the topical intent.
Evaluation
The Web Archive we used for the evaluation consists of 4.05 billion captures of Web pages from the .de top-level domain as collected by the Internet Archive between 1994 until 2013. We manually defined 28 events to be extracted from the Web archive likely to be represented in the archive like the Fukushima nuclear accident or German federal elections. The topical scope of the events is described by relevant Wikipedia pages. We also defined a start and end date, as well as an estimated event lead and cool-down time. The outgoing links of the Wikipedia pages were used as seed URLs.
The goal of the evaluation is to assess the precision of the proposed collection extraction method in light of different event types and to better understand the influence of this method on the quality of the resulting event-centric collections. We compare our combined relevance function (CT-F) with two baselines that use state-of-the-art functions for topical [5] (C-F) or temporal [6] (T-F) relevance estimation. We also use an unfocused crawl that does not use any relevance estimates as an additional baseline. For each of the 28 events we started a crawl using each of the configurations described above. Each crawl ran until it had retrieved 100,000 documents or until the crawler queue was empty.
![Accumulated relevance of different event collections: combined relevance (CT-F), topical relevance [5] (C-F), temporal relevance](/files/Europeana_Professional/EuropeanaTech/EuropeanaTech Insight/Images/TPDL/risse1.png)
Figure 1: Accumulated relevance of different event collections: combined relevance (CT-F), topical relevance [5] (C-F), temporal relevance [6] (T-F).
Figure 1 shows the accumulated relevance of document collections for selected events in relation to the number of documents crawled. This function should ideally start with a strong incline, meaning that the crawler fetches many relevant documents early on, flattening into a plateau when no relevant documents are available anymore. We see that for all topics the combined function outperforms the temporal function and the unfocused baseline both in terms of average relevance of documents retrieved at any given point and total relevance. The content function often performs slightly better than the combined function. The relevance focused strategies manage to uncover more potentially relevant URLs even if they are not contained in the locally available Web archive.
We crawled each event using an exponential decay function with a fixed decay and compared it to the crawl using the user-specified lead and cool-down times. We see that the event-specific parameters cause a significant improvement for most of the events (see [4]).
Conclusions
We presented a summary of our work in [4] to create interlinked event-centric document collections from Web archives by adapting focused Web crawling. We showed that our re-crawling method can effectively retrieve event-centric collections. Further research is needed to better understand the influence of extraction methods, relevance functions and parameters in regard to different events, time periods and Web archives.
References
[1] Gossen, G., Demidova, E., Risse, T.: Analyzing web archives through topic and event focused sub-collections. In: WebSci 2016. pp. 291–295, May 2016
[2] Risse, T., Demidova, E., Gossen, G.:What do you want to collect from the web? In: Proceedings of the Building Web Observatories Workshop (BWOW) 2014
[3] Jackson, A., Lin, J., Milligan, I., Ruest, N.: Desiderata for exploratory search interfaces to web archives in support of scholarly activities. In: JCDL2016 (2016)
[4] Gossen, G., Demidova, E., Risse, T.: Extracting Event-Centric Document Collections from Large-Scale Web Archives. Research and Advanced Technology for Digital Libraries: 21st International Conference on Theory and Practice of Digital Libraries, TPDL 2017, Thessaloniki, Greece, September 18-21, 2017, Proceedings (p. 116--127). Springer, Cham (2017)
[5] Pant, G., Srinivasan, P., Menczer, F.: Crawling the web. In: Web Dynamics (2004)
[6] Pereira, P., Macedo, J., Craveiro, O., Madeira, H.: Time-aware focused web crawling. In: ECIR 2014. LNCS, vol. 8416, pp. 534–539. Springer, Cham (2014).
In the World Wide Web, a very large number of resources are made available through digital libraries. The existence of many individual digital libraries, maintained by different organizations, brings challenges to the discoverability and usage of the resources by potentially interested users.
An often-used approach is metadata aggregation, where a central organization takes the role of facilitating the discovery and use of the resources by collecting their associated metadata. Europeana has the role of facilitating the usage of CH resources from and about Europe, and although many European CH Institutions (CHIs) do not yet have a presence in Europeana, it already holds metadata from over 3,700 providers.
Since its very beginning, Europeana’s approach for supporting the discovery of cultural heritage (CH) resources has been metadata by aggregation, based on the OAI-PMH protocol, a technology initially designed in 1999. However Cultural Heritage Institutions (CHIs) are increasingly applying technologies designed for wider interoperability on the World Wide Web. Particularly relevant are those related with search engine optimization, social networks, and the International Image Interoperability Framework (IIIF). Regardless of the metadata aggregation process for Europeana, CHIs are already interested in developing their systems’ capabilities in these areas. If Europeana also uses these technologies then their participation in Europeana may become less demanding.
Research and development during 2017 included activities on rethinking Europeana’s technological approach for metadata aggregation, with the aim to make the operation of the aggregation network more efficient and lower the technical barriers for data providers to contribute to Europeana. Note that our research merely complements other Europeana efforts to further develop and innovate Europeana's aggregation process. We do not make any assumption on the organization of the aggregation process, especially on whether the data is 'pushed' by CHIs to Europeana or pulled by Europeana from CHIs or data aggregators. We rather explore components, which could be used by either framework - some of our proposals have actually been already tested or included in them.
In the work presented at TPDL 2017, we (Europeana and data providers) report on case studies that trialled the application of some of the most promising technologies, exploring several solutions based on the International Image Interoperability Framework (IIIF) and Sitemaps. Our motivation for researching the application of these two technologies comes from IIIF getting increasing traction in CH. Moreover, IIIF is a community developed, open framework, thus our requirements for metadata aggregation may be incorporated into future versions of IIIF. Our case studies indicate that data acquisition via IIIF is feasible, and presents little technological barriers for data providers that already have a IIIF solution in place for their own purposes. Researching the application of Sitemaps was motivated by its wide usage within the Europeana data providers. In addition, Sitemaps is a very simple technological solution, with a very low implementation barrier to those providers that are not currently using it.
IIIF is a family of specifications that were conceived to facilitate systematic reuse of image resources in digital repositories maintained by CHIs. It specifies several HTTP based web services covering access to images, the presentation and structure of complex digital objects composed of one or more images, and searching within their content. IIIF’s strength resides in the presentation possibilities it provides for end-users. From the perspective of data acquisition, however, none of the IIIF APIs was specifically designed to support metadata aggregation. Nevertheless, within the output given by the IIIF APIs, there may exist enough information to allow HTTP robots to crawl IIIF endpoints and harvest the links to the digital resources and associated metadata.
Sitemaps allow webmasters to inform search engines about pages on their sites that are available for crawling by search engine’s robots. A Sitemap is an XML file that lists URLs of the pages within a website along with additional metadata about each URL (i.e. when it was last updated, how often it usually changes, and how important it is in comparison to other URLs within the same site) so that search engines can more efficiently crawl the site. Sitemaps is a widely-adopted technology, supported by all major search engines. Many content management systems support Sitemaps out-of-the-box and Sitemaps are simple enough to be manually built by webmasters when necessary. Moreover, there are Sitemaps extensions, like Google’s Image Sitemaps and Video Sitemaps , which have potential usage in metadata aggregation.
We have undertaken several case studies to investigate the feasibility of performing metadata aggregation via IIIF and/or Sitemaps. These studies were conducted in cooperation with data providers of the Europeana Network, namely, the National Library of Wales and University College Dublin, which were actively deploying these two technologies within their own information systems.
IIIF played a double role in our work. It was used as the data source from where the source metadata was aggregated from providers, and as a technology that can be used with other suitable web-based technologies to facilitate aggregation processes. We have specifically studied how the functionality available in the IIIF Presentation API could be used to provide similar aggregation functionality as OAI-PMH and Sitemaps. The TPDL 2017 publication describes in detail the case studies and how the two technologies were used for metadata aggregation. The solutions were trialled successfully and leveraged on existing technology and knowledge held by the CHIs, with low implementation barriers. The future challenges lie in choosing among the several possibilities and standardize solution(s). Europeana is currently engaged with the IIIF community, aiming to establish a standard, or guidelines, that will facilitate the metadata aggregation process of IIIF services. Currently, Europeana co-chairs the IIIF Discovery Technical Specification Group and has its use-case under discussion there.
The navigation in an ever-changing overloaded bibliographic universe that preserves the contextual semantics of the bibliographic descriptions largely depends on the control of content relationships and bibliographic families. According to Tillett [1] content relationships exist between different bibliographic entities and can be considered as a sequence of intellectual/artistic content; as this continuum gets distant from the original parent, the relationship becomes remote. The term bibliographic family is defined as ‘a set of related bibliographic works that are somehow derived from a common [parent]’ [2]. Library conceptual models include constructs to describe and control relationships and bibliographic families. The identification of bibliographic families and the clustering of all related entities shall enable future library catalogs’ navigation functionalities. The preservation of bibliographic families maintains the information that two or more Works originate from a common progenitor. Hence, successful mappings between different conceptual models presuppose the preservation of content relationships and bibliographic families after data transformation [3–5].
This paper is based on [6] and examines if and how information about content relationships and bibliographic families may be preserved in mappings from FRBR to BIBFRAME. The cases of a Work with a single Expression, as well as bibliographic family cases e.g. Work with multiple Expressions and Works with derivative relationships are studied and some interesting findings have been derived. Mapping content relationships and bibliographic families
Work with a single Expression The simplest and the most frequent bibliographic case [7] is a Work with a single Expression and a single Manifestation, e.g. a monograph (book) in a language. The mapping for this case seems straightforward (Figure 1). The FRBR path Work-is realized through-Expression is mapped to the bf:Work class, while the rest constructs of the path are mapped 1:1. More precise mappings may be developed for each of the 10 subclasses of the BIBFRAME Creative Work class and for the 5 subclasses of the bf:Instance class.

Fig. 1. Mapping from FRBR to BIBFRAME representation pattern for a Work with a single Expression.
The exploitation of (a) the attributes of the FRBR Expression and Manifestation entities and (b) controlled vocabularies from the Library of Congress Linked Data Service or ISBD vocabularies to specify the values of the attributes improve significantly the semantic precision of the mapping rules. For instance at the Expression level, we have identified the form of expression attribute and we used the LC Content Types Scheme for its values to enable precise mappings for all bf:Work subclasses. In some cases these values may even determine the mapping to a bf:Instance subclass (see Figure 2). Furthermore, at the Manifestation level, we have identified the form of carrier attribute and used the LC Carriers Scheme.
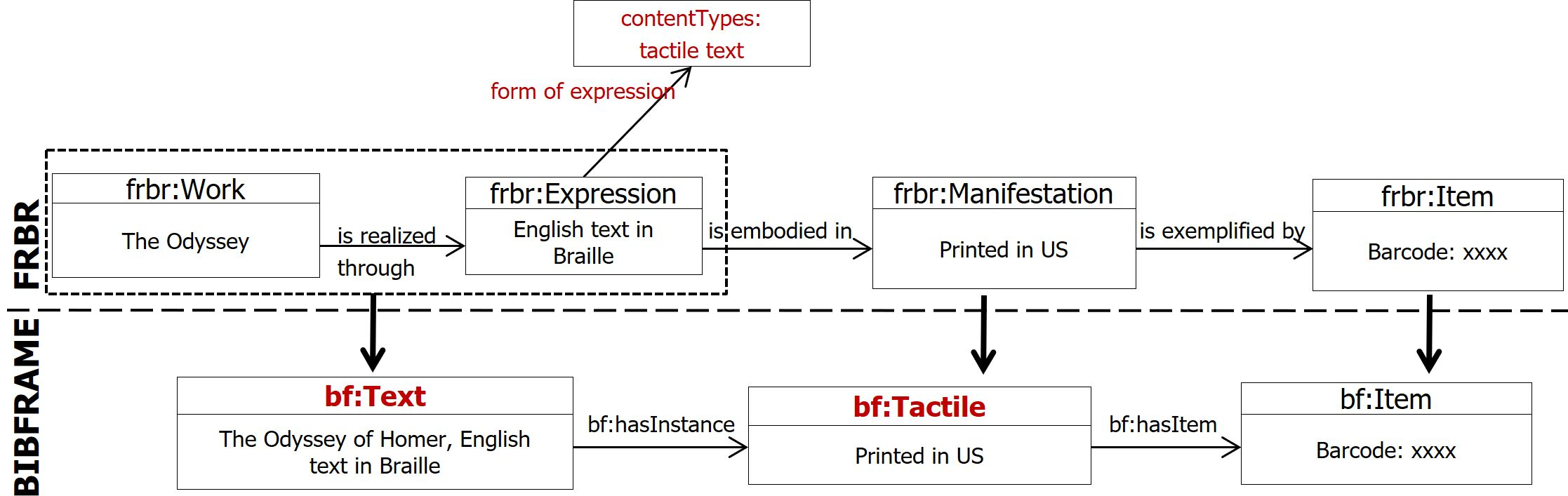
Fig. 2. Mapping from FRBR to BIBFRAME a detailed representation pattern for a Work with a single Expression.
The path Expression-form of expression-contentTypes: tactile text triggers mapping to bf:Work and bf:Instance subclasses. The utilization of controlled vocabularies for interoperability reasons demands both their multilingualism and their representation in RDF. Therefore, cataloging should be performed taking into account the collaboration and data reusability principles.
Work with multiple Expressions In the case of mappings from an FRBR Work with multiple Expressions to BIBFRAME, two instances of the bf:Work class are generated. However the semantics regarding the origination of the two instances of the bf:Work class from the same Work (intellectual idea) are lost (Figure 3).
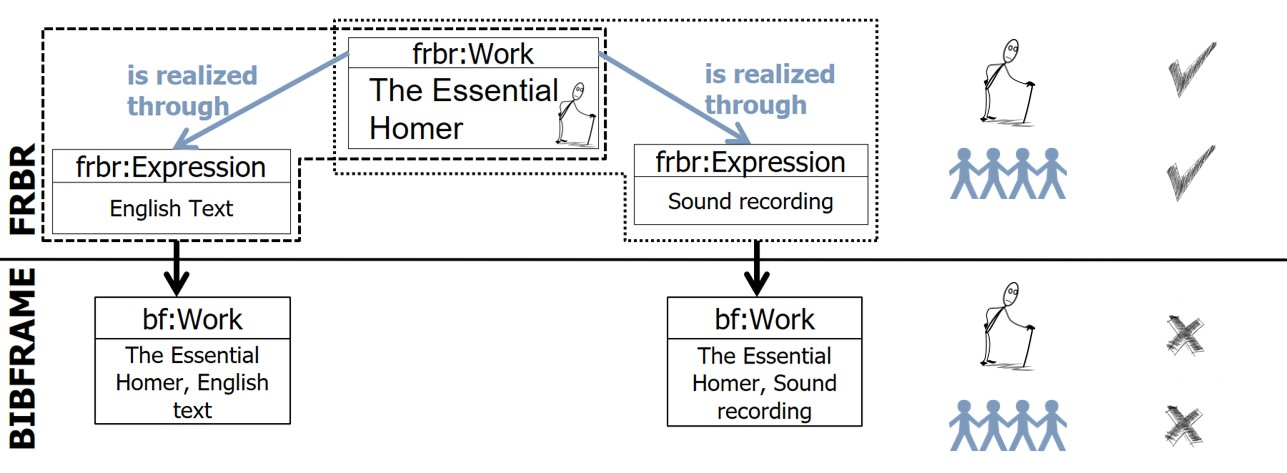
Fig. 3. Mapping from FRBR to BIBFRAME representation pattern for a Work with a single Expression. After mapping, both parent and bibliographic relationship are lost.
Derivation - translation Literal translation is represented in FRBR by relating two or more Expressions of the same Work with the has translation relationship (upper part of Figure 4). After mapping to BIBFRAME, the content relationship between the two Expressions is preserved in the two bf:Works. The information that the bf:Work instances have the same progenitor (Work) is not preserved though (Figure 4).
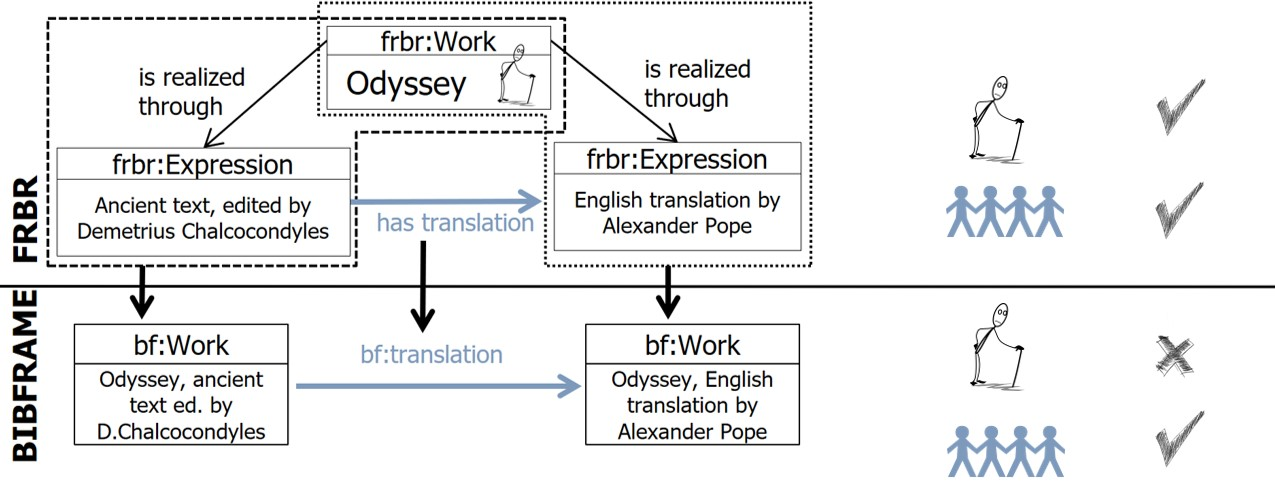
Fig. 4. Mapping from FRBR to BIBFRAME representation pattern for the translation case.
In order to preserve information about the common parent, an additional Expression-agnostic bf:Work instance will be created (bf:Work with the long dash-dot outline in Figure 5). Then this additional bf:Work instance will be linked with the others bf:Work instances using the bf:hasExpression property (also depicted with a long dash-dot line). This Expression-agnostic bf:Work cannot have any bf:Instances but it can serve as a the parent for all bf:Works that somehow derive from it.
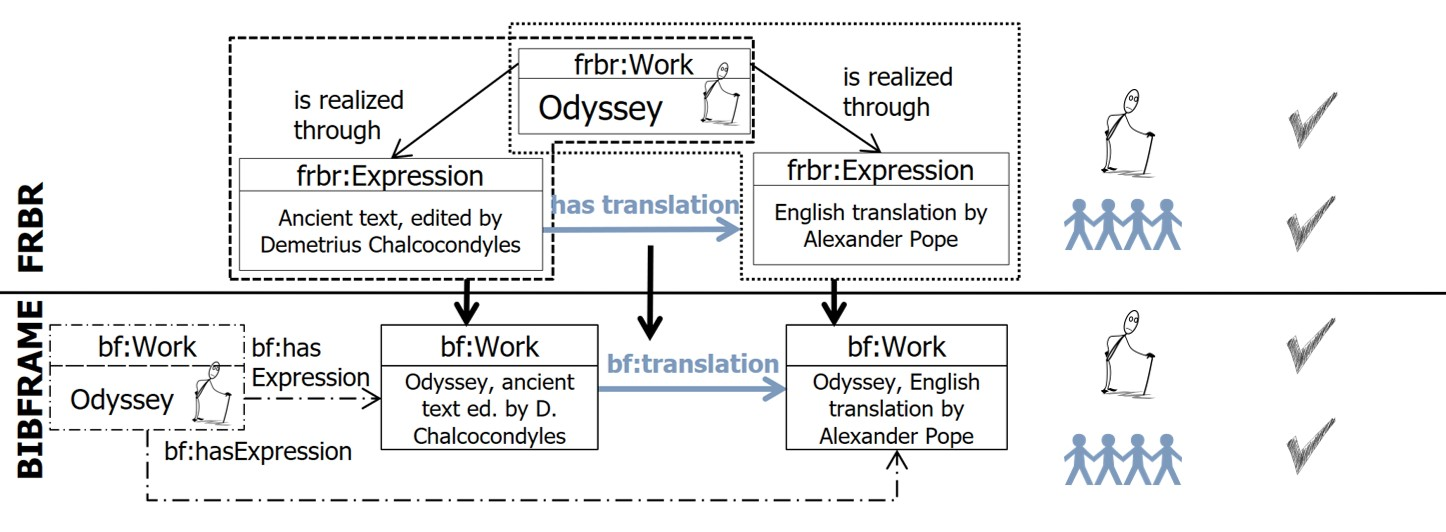
Fig. 5. Mapping from FRBR to BIBFRAME representation pattern for the translation case. The bf:Work with the long dash-dot outline has been added in the mapping to preserve the parent bf:Work of the Odyssey bibliographic family.
Adaptation is represented in FRBR, either between Works, or between Expressions of different Works. This case demonstrated similar results with the translation case: content relationships are preserved, the parent is lost and the addition of Expression-agnostic bf:Work preserves information about the bibliographic family.
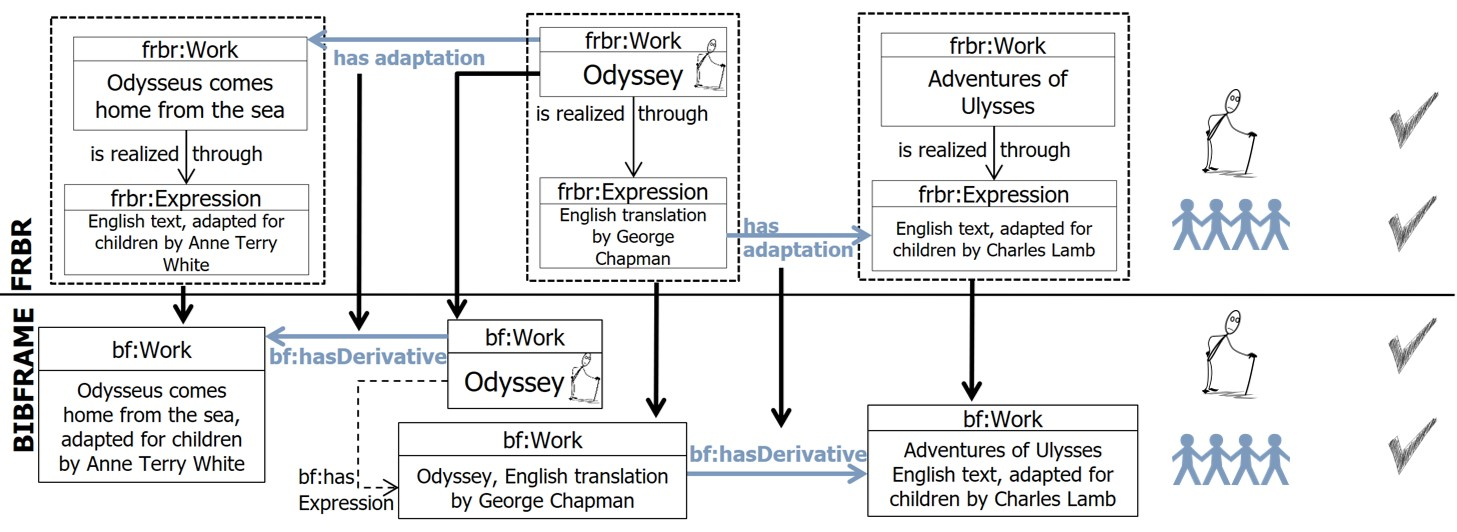
Fig. 6. Mapping from FRBR to BIBFRAME representation pattern for the adaptation case. The Expression-agnostic bf:Work serves as the parent bf:Work of the Odyssey bibliographic family.
Conclusions
One key finding has been that relationships between members of a bibliographic family are preserved in BIBFRAME when FRBR Expressions are related. Moreover, the parent Work is not always represented in BIBFRAME after mappings.
This study uses a limited set of cases and data. A follow-up study shall use a bigger dataset and test more cases; it will also compare the transformation using existing transformation tools to evaluate their degree of preservation of bibliographic relationships after mappings. Interesting findings are also anticipated for testing IFLA LRM to BIBFRAME and the opposite mappings.
References
[1]Tillett, B.B.: Bibliographic relationships. In: Bean, C.A. and Green, R. (eds.) Relationships in the organization of knowledge. pp. 19–35. Springer Science+Business Media, Dordrecht (2001).
[2]Smiraglia, R., Leazer, G.: Derivative bibliographic relationships: The work relationship in a global bibliographic database. J. Am. Soc. Inf. Sci. 50, 493–504 (1999).
[3] Arastoopor, S., Fattahi, R., Mehri Parikosh: Developing user-centered displays for literary works in digital libraries: integrating bibliographic families, FRBR and users. In: 2nd International Conference of Asian Special Libraries ICoASL. pp. 83–91. Special Libraries Association - Asian Chapter, Tokyo (2011).
[4] Smiraglia, R.P., Heuvel, C. Van Den: Classifications and concepts: towards an elementary theory of knowledge interaction. J. Doc. 69, 360–383 (2013).
[5] Merčun, T., Žumer, M., Aalberg, T.: Presenting bibliographic families: Designing an FRBR-based prototype using information visualization. J. Doc. 72, 490–526 (2016).
[6] Zapounidou, S., Sfakakis, M., Papatheodorou, C.: Preserving Bibliographic Relationships in Mappings from FRBR to BIBFRAME 2.0. In: Kamps, J., Tsakonas, G., Manolopoulos, Y., Iliadis, L., and Karydis, I. (eds.) Research and Advanced Technology for Digital Libraries: 21st International Conference on Theory and Practice of Digital Libraries, TPDL 2017, Thessaloniki, Greece, September 18-21, 2017, Proceedings. pp. 15–26. Springer International Publishing AG (2017).
[7] Bennett, R., Lavoie, B.F., O’Neill, E.T.: The Concept of a Work in WorldCat: An Application of FRBR. Libr. Collect. Acquis. Tech. Serv. 27, 45–59 (2003).
Introduction
People use digital cultural heritage sites in different ways and for various purposes. In this study, we addressed two research questions: (RQ1) What information do users search for using Europeana? and (RQ2) What do users use this information for? We gathered a sample of 240 search requests from users via an online survey on the Europeana portal and used qualitative content analysis to better understand users’ information behaviours. As a result the investigation provides an in-depth study of task, mainly at the level of the search task.
Methodology
A pop-up web survey was shown to users during their interactions with Europeana, i.e. viewing a search results page, or a Europeana item page. The first 6 questions are shown in Table 1; the remainder asked about level of subject knowledge and suggestions for further improvements to Europeana. The focus of this work was investigating responses to Q4 and Q5. The survey was administered in English and was shown to up to 66% of visiting Europeana users.
Table 1. Questions (first 6 out of 10) used in the pop-up survey
No | Question |
1 | How often do you visit Europeana? |
2 | How would you identify yourself? |
3 | How did you get to Europeana today? |
4 | What information are you looking for right now? |
5 | Why are you looking for this information? |
6 | After finding this information, you will: ___________________ |
Participants
The pop-up survey ran for 2 weeks (21 March – 4 April 2017) and elicited responses from 240 users of the Europeana portal from 48 different countries (Figure 1). As shown in Figure 2, the type of visitor and frequency of visits of the respondents vary widely.
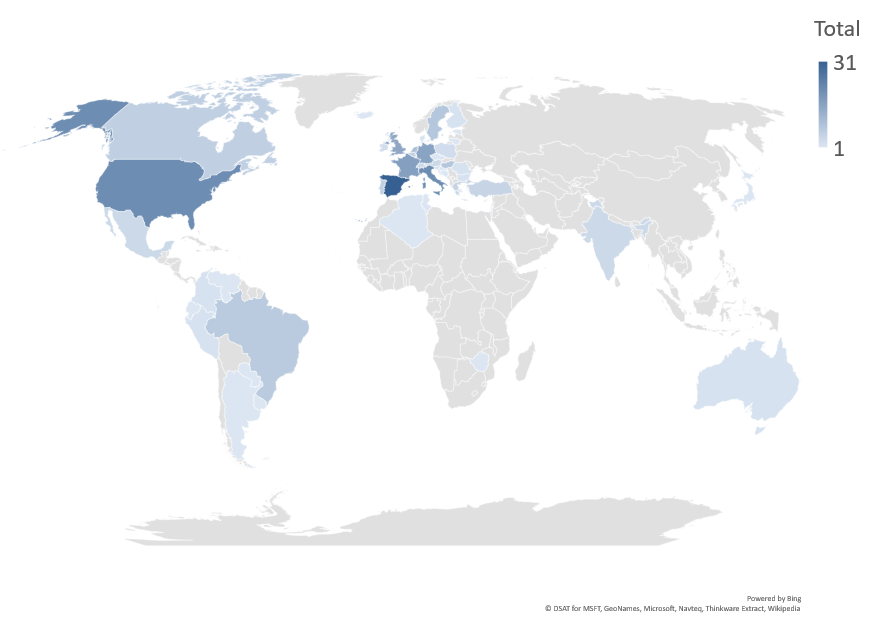
Figure 1. Country of origin of respondents
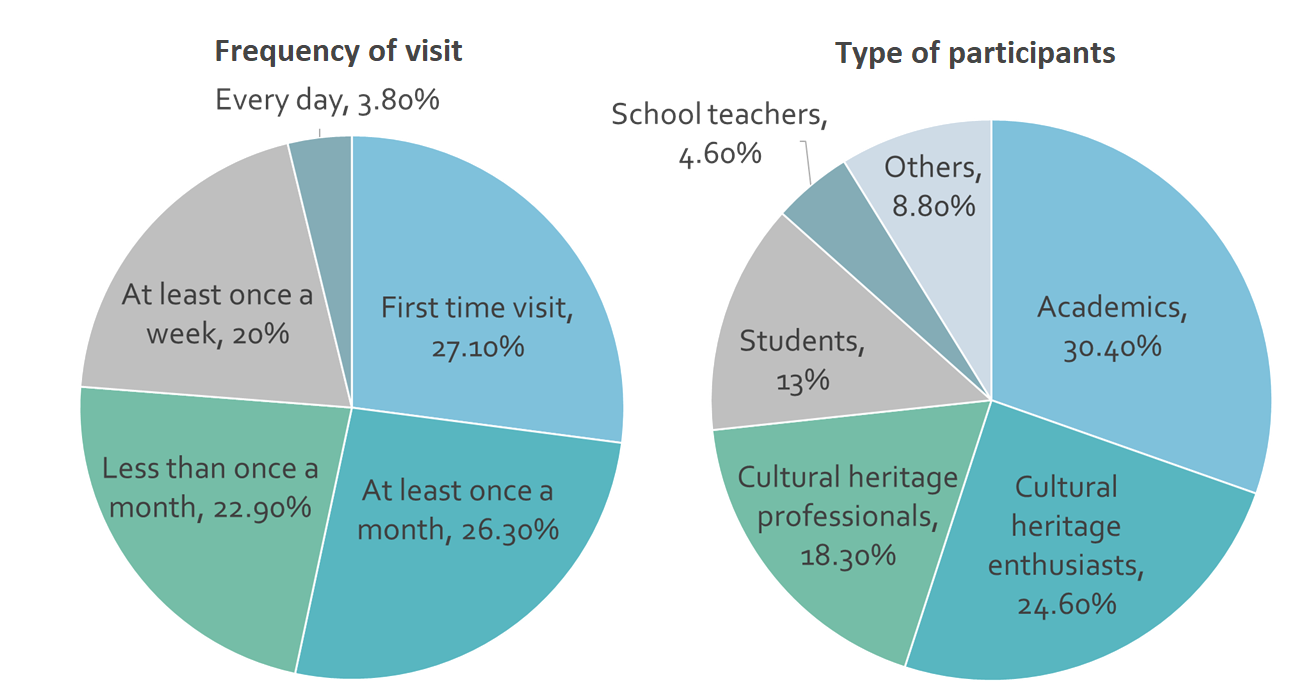
Figure 2. Demographics of respondents (Q1 and Q2)
Analysis of the search requests
One of the major challenges was analysing the rich data provided by the free-text responses describing users' search requests. Examples of users’ responses are shown in Table 2.
Table 2. Examples of users’ search requests (Q4 and Q5)
Q4: “What information are you looking for right now?” | Q5: “Why are you looking for this information?” |
I am looking for the 1919 film "Les fetes de la victoire". | I want to use the excerpt to illustrate a university lecture. |
I'm looking for traces of Russian émigrés from 1917 to the 1930s : art, photographs, or maps. | To help plan an exhibition for an International summit. |
I´m trying to find reusable patterns to use in a fabric screenprinting project. | I am going to attend a course in screenprinting this autumn and need to prepare some ideas. |
Search tasks can be categorised in various ways, such as by goal or intent, complexity, search tactics and moves, timeframe and specificity. However, many of the prior schemes are specific to Web search and less suited to cultural heritage. In this study, we performed a categorisation of search tasks using six categories described in Table 3.
Table 3. Scheme to categorise types of search tasks
Search Tasks | Definitions |
Specific-item search | Search for specific item (i.e., known-item) typically expressed precisely |
By named author | Search for information by a specific named author or provider |
Specific-subject search | Find information for specified (or named) subject (i.e., person, place, location, etc.) forming the main subject of the request |
General topical search | Find information for general subject |
Browsing or exploring | Used to identify searches where the user has no specific goal |
Ambiguous or unclear | The search request is unclear or difficult to determine category |
We also performed a categorisation based on mode/facet analysis, by adapting the approach described in Armitage and Enser (1996) to derive 18 categories suitable for analysing the subject of Europeana search requests (Table 4).
Table 4. Scheme used to categorise subject contents of search requests
Category | Example |
Specific person/group | “Saint Francis of Assisi” |
General person/group | “working women”, “historical figures” |
Specific object/thing | “Prelude, Op. 28, No. 7, by Frederic Chopin” |
General object/thing | “paintings” |
Specific location | “Spain” |
General location | “public places” |
Specific event | “Great War” |
General event | “working”, “privatisation of school system” |
Specific time | “1940” |
General time | “medieval” |
General subject | “art”, “history” |
Creator | “paintings by Van Gogh” |
Provider | “I am searching for images from the Regional Archeological Museum Plovdiv.” |
Nationality | “Icelandic artworks” |
Language | “books written in Italian” |
Availability | “free open-source 3d models” |
Response | “looking for a nice painting” |
Medium | “image”, “video”, “text” |
The categories were used to identify the content of search request according to modes/facets. For example, “Great War photographs taken on exactly 100 years ago” would be coded as ‘Specific event/action (Great War) + Specific time (100 years ago)’. During the coding, each type of subject category is applied just once.
A final analysis considered why people were searching for information during their current activity (i.e. their motives). No prior suitable categorisation scheme was found available; therefore, we created a new scheme to categorise users’ motives and information uses that comprised five high-level classes:
Results and Discussion
RQ1: What Information are Users Searching for?
Figure 3 shows that the largest single search category is general topical search (47.1%), followed by specific-subject searches (24.6%), specific-item searches (11.25%); searches by named author (7.1%) and browse/explore (7.1%). Broken down by group, the highest proportion of specific-item searches (63%) come from academics; whilst the highest proportion of browse/explore searches (29.4%) come from cultural heritage enthusiasts. We also note differences based upon referrer: the greatest proportion of general topical searches (51.3%) come from people who already knew about the site and so came directly to it; whereas the greatest proportion of specific-item searches (48.1%) result from search engine referrals.
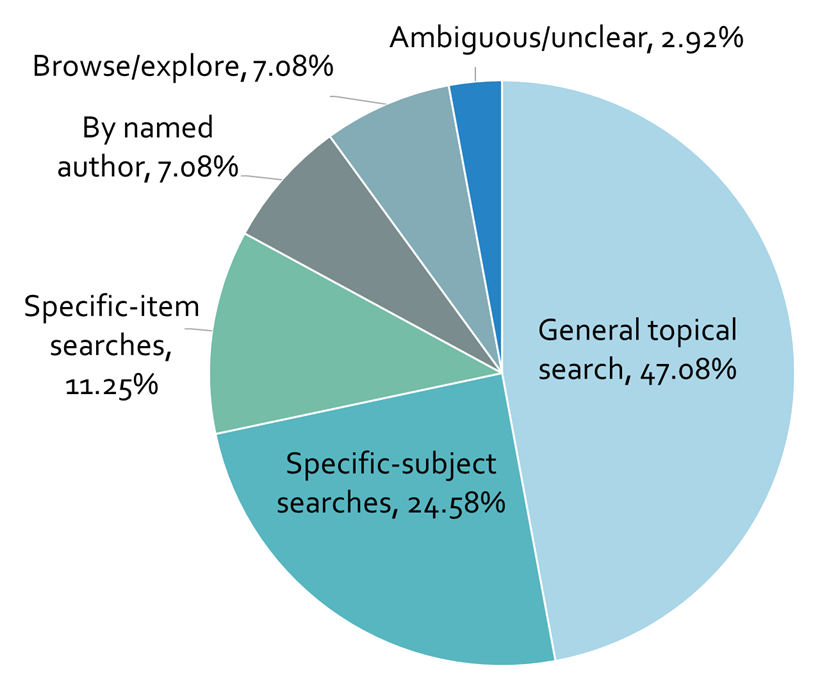
Figure 3. Categorisation of search tasks
Figure 4 provides insights into the subject content of the search requests. The most frequent mode/facet is general object/thing (71 occurrences), followed by specific location (42 occurrences). Search requests comprise an average of 1.53 modes/facets (min=1, max=5). The most common combinations are “Creator + Specific object/thing”, e.g., “I want to find some information about a painting of Willem van de Helde: ‘Het kanonschot’”, followed by “Creator + General object/thing”, e.g., “I am looking for artworks by Leonardo da Vinci”.
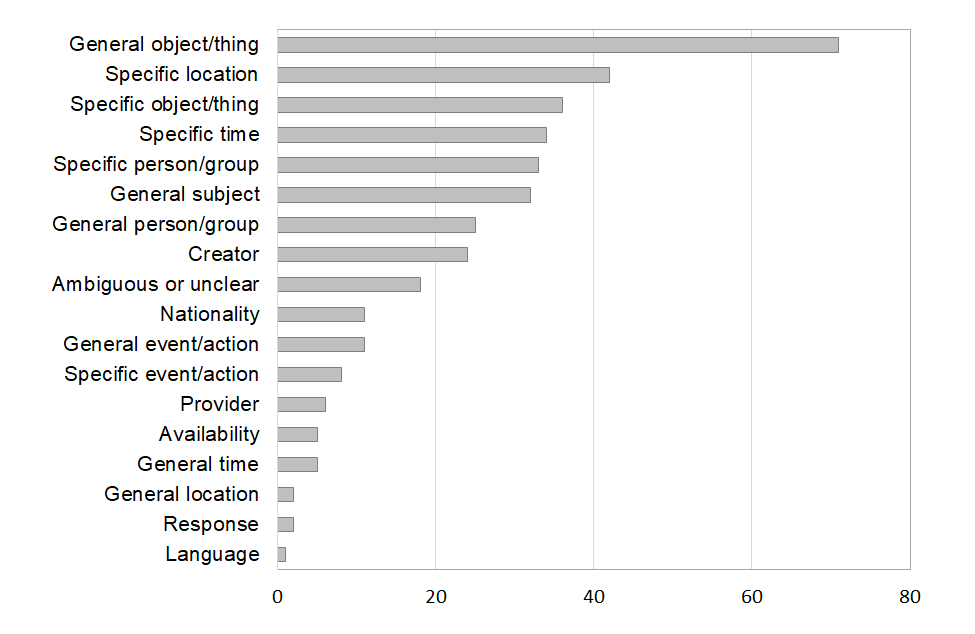
Figure 4. Categorisation of mode / facet analysis
RQ2: Why are Users Searching for the Information?
The majority of users (37.1%) were searching Europeana with the intention of using the information found to create a new work, e.g. “to write a book", or “to prepare an exhibition". Under the category of personal interest (27.5%), users are typically cultural heritage enthusiasts, with Europeana serving as one of their resources. We categorised 20.8% of search tasks as professional activities; with 7.9% of search tasks categorised under the category of teaching.
Table 5. Cross-tabulation of users' motivation vs. search task
Browse/explore | By named author | General topical search | Specific-item search | Subject-specific search | Total | |
Create new work | 17.6% | 23.5% | 37.2% | 48.1% | 42.4% | 37.1% |
Personal interest | 35.3% | 29.4% | 22.1% | 11.1% | 44.1% | 27.5% |
Professional activity | 11.8% | 41.2% | 26.5% | 22.2% | 5.1% | 20.8% |
Teaching | 17.6% | 5.9% | 5.3% | 14.8% | 8.5% | 7.9% |
Other | - | - | 0.9% | - | - | 0.4% |
Ambiguous/unclear | 17.6% | - | 8% | 3.7% | - | 6.3% |
Total | 100% | 100% | 100% | 100% | 100% | 100% |
We also analysed the relation between users’ motivations for searching and type of search task (Table 5) and found that, in the case of specific-item searches, information from 48.1% of searches is used to create a new work, commonly reflecting the greater search for specific-items by academics. In contrast, for specific-subject searches the majority of search tasks are split between personal interest (44.1%) and creating a new work (42.4%). The results highlight, again, the differences obtained based on the user's search task.
Understanding users and their context for information seeking is key to user-informed design and evaluation of information systems and services. This novel study investigated what information users search for using Europeana and why. Based on results from a pop-up survey we analysed the type and subject content of search tasks, as well as develop a scheme for categorising search tasks and information use. These results help better understand the users of Europeana and may inform search in cultural heritage more generally.
The dataset of search tasks is available for download from: https://doi.org/10.15131/shef.data.5411194
A more detailed version of this paper can be found in: Clough, P., Hill, T., Paramita, M. L., and Goodale, P. 2017. Europeana: What Users Search for and Why. In: Proceedings of TPDL 2017.