Issue 7: LODLAM
EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community



















EuropeanaTech Insight is a multimedia publication about R&D developments by the EuropeanaTech Community
Linked Open Data (LOD) enables cultural heritage institutions to publish and share their data in a way that seamlessly offers possibilities for data re-use, data enrichment and annotation increasing the visibility of collections and data for much wider audiences. Europeana has now been committed to sharing all its metadata as Linked Open Data for half a decade and has dedicated considerable efforts to improving and showcasing the adoption of Linked Open Data world wide. This includes being involved in the LODLAM Summit, a gathering of libraries, archives and museums who, in un-conference style, come and present, discuss and share their LOD projects and activities (for a complete account of the 2017 edition, see this post).
With this issue of EuropeanaTech Insight in collaboration with the LODLAM 2017 Summit, we invited several finalists from the LODLAM Challenge to elaborate on their projects. The LODLAM Challenge highlights data visualisations, tools, mashups, meshups, and all types of use cases for Linked Open Data in libraries, archives, and museums. Entries for the Challenge are all demonstrable use cases that leverage Linked Open Data in libraries, archives and museums, and include digital humanities projects. You can read more about the challenge and all the entrants here.
In addition to these LODLAM challenge finalists we also invited two LOD projects and topics that we found interesting and worth sharing in the context of this LOD specific issue of EuropeanaTech Insight. New to Linked Open Data? You can watch this great video from Europeana that simply explains the main principles of LOD.
Linked Open Data - What is it? from Europeana.
Learning from History is Hard
Many websites publish information about the Second World War (WW2), the largest global tragedy in human history. Such information is of interest not only to historians but to hundreds of millions of citizens globally who themselves or whose relatives participated in the war actions, creating a shared trauma all over the world. However, WW2 information on the web is typically meant for human consumption only, and there are hardly any websites that serve machine-readable data about the WW2 for Digital Humanities (DH) and end-user applications to use. Our work on the WarSampo system is based on the belief that by making war data more accessible our understanding of the reality of the war improves, which not only advances understanding of the past but also promotes peace in the future. Georg Wilhelm Friedrich Hegel has said: “we learn from history that we learn nothing from history”. Hopefully this is not the case for the WW2 now that fighting has started again even within the borders of Europe in Ukraine.
The WarSampo system 1) initiates and fosters large scale Linked Open Data (LOD) publication of WW2 data from distributed, heterogeneous data silos and 2) demonstrates and suggests its use in applications and DH research. WarSampo is to our best knowledge the first large scale system for serving and publishing WW2 LOD on the Semantic Web for machine and human users. Its knowledge graph metadata contains over 9 million associations (triples) between data items including, e.g., a complete set of over 95,000 death records of Finnish WW2 soldiers, 160,000 authentic photos taken during the war, 32,000 historical places on historical maps, 23,000 war diaries of army units, and 3,400 memoir articles written by the veterans after the war. WarSampo data comes from several Finnish organizations and sources, such as National Archives, Defense Forces, Land Survey of Finland, Wikipedia/DBpedia, text books, and magazines.
WarSampo has two separate components: 1) WarSampo Data Service for machines and 2) WarSampo Semantic Portal with various applications for human users.
WarSampo Data Service
WarSampo publishes massive collections of heterogeneous, distributed (meta)data about WW2 on the Semantic Web. The datasets are harmonized into LOD using event-based modeling, based on an extension of CIDOC CRM, and are enriched semantically with each other’s contents and external data sources. The data is openly available for download, Linked Data browsing, and querying with SPARQL via the Linked Data Finland “7-star” platform for Digital Humanities research and for creating applications.
WarSampo Semantic Portal
To test and demonstrate the usefulness of the data service, the WarSampo Semantic Portal was created, allowing both historians and the general public to study war history and the destinies of their family members in the war from 7 interlinked application perspectives: Historical events, Persons, Army Units, Places, Memoir Articles, Death Records, and Photographs. Two new application perspectives pertaining to some 650 war cemeteries and over 3,000 photographs of them, and to a database of some 4,500 prisoners of war, will be published by the end of 2017, the centennial of independence of Finland. The portal immediately attracted thousands of visitors after its publication in November 2015.
A typical use case of the system is automatic reconstruction of a soldier’s life story based on data linking. For example, if one’s relative was killed in action, he can be found in the death record data telling, e.g., in which army unit he served. For army units, data about their battles, movements, etc. can be found and therefore also the actions of a person in the unit be illustrated on maps and timelines (assuming that he was travelling with the unit). Additional data, such as photographs, can be linked not only to persons and units mentioned, but also to events based on places and times mentioned in the metadata and using Named Entity Linking. Furthermore, links to the actual war diaries can be provided based on the army unit data. For example, Figure 1 illustrates data about a unit selected on the left (a). Related events are shown on a timeline (c), and those in the particular time window in the middle are visualized on the map (b) with a heat map about casualties within the currently visible time window. On the right, information regarding the unit is shown, including photographs related to it (d). Additional links are shown to 445 persons in the unit (e), related units (f), battles (g), and war diaries (h).
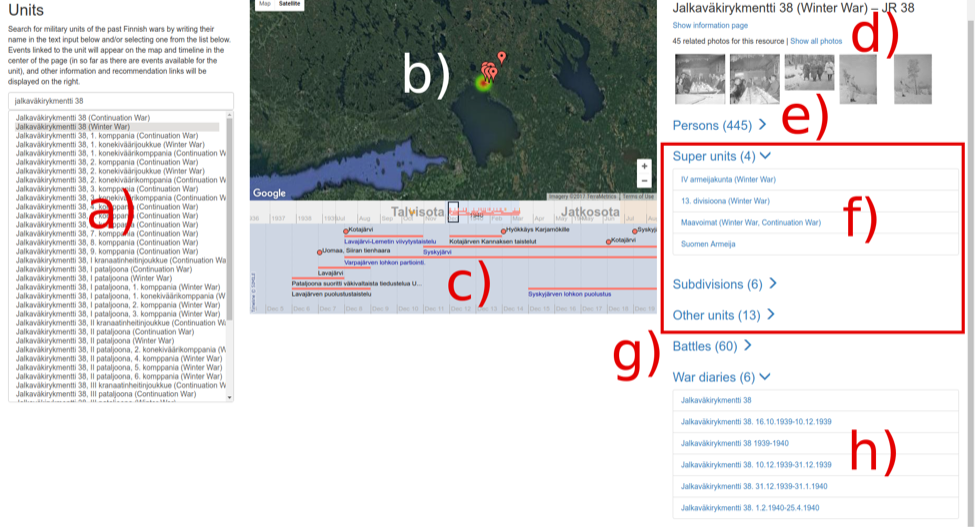
Figure 1: A view from the Army Units application perspective showing aggregated spatio-temporal data about the history of the Infantry Regiment 38.
Lessons Learned Work on WarSampo argues and demonstrates that world war history makes a promising use case for Linked Open Data because war data is by nature heterogeneous, distributed in different countries and organizations, and written in different languages. WarSampo is based on the idea of creating a shared, open semantic data repository with a sustainable “business model” where everybody wins: when an organization contributes to the WW2 LOD cloud with a piece of information, say a photograph, its description is automatically connected to related data, such as persons or places depicted. At the same time, the related pieces of information, provided by others, are enriched with links to the new data.
The project homepage describes the system in more detail and contains additional videos on using the application. Scientific publications as well as academic theses based on WarSampo research are available at the bottom of the project homepage, such as:
Eero Hyvönen, Erkki Heino, Petri Leskinen, Esko Ikkala, Mikko Koho, Minna Tamper, Jouni Tuominen and Eetu Mäkelä: WarSampo Data Service and Semantic Portal for Publishing Linked Open Data about the Second World War History. In: The Semantic Web – Latest Advances and New Domains (ESWC 2016), Springer-Verlag, May, 2016. http://seco.cs.aalto.fi/public...
Introduction
Fishing in the Data Ocean is a LOD-based project reusing 40, 000 metadata records of the fish collection in the Taiwan Digital Archives Union Catalogue (TaiUC), an online portal gathering over 5 million digitized cultural objects from more than 100 LAM groups, academic and governmental institutions in Taiwan. This pilot study, reports how the Academia Sinica Center for Digital Cultures (ASCDC) applies Linked Open Data (LOD) techniques to convert the original metadata of the fish collection into a machine-readable RDF format and to maintain the original data meaning after converting into a LOD dataset.
Data reconciliation and enrichment
The metadata of these 40,000 items in TaiUC are drawn from the museum collection of the Biodiversity Research Center in Academia Sinica, consist of various data types such as specimen pictures, otolith images, X-ray images and drawings, and are mapped to Dublin Core as the common metadata standard
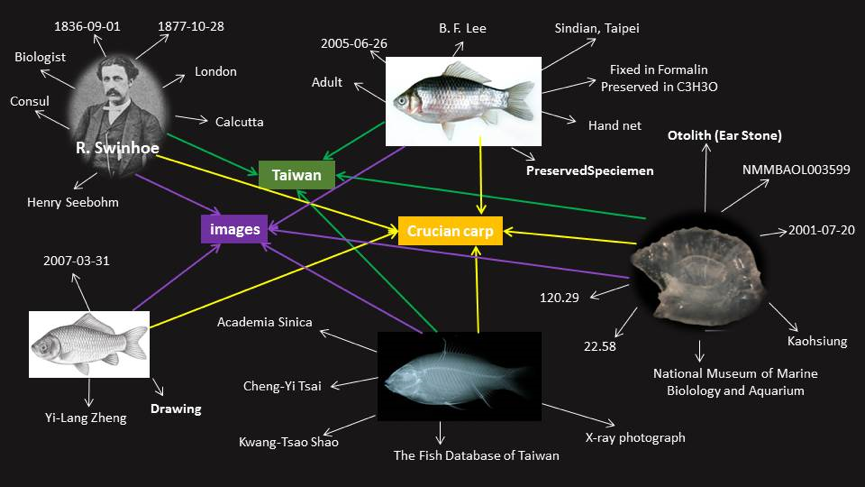
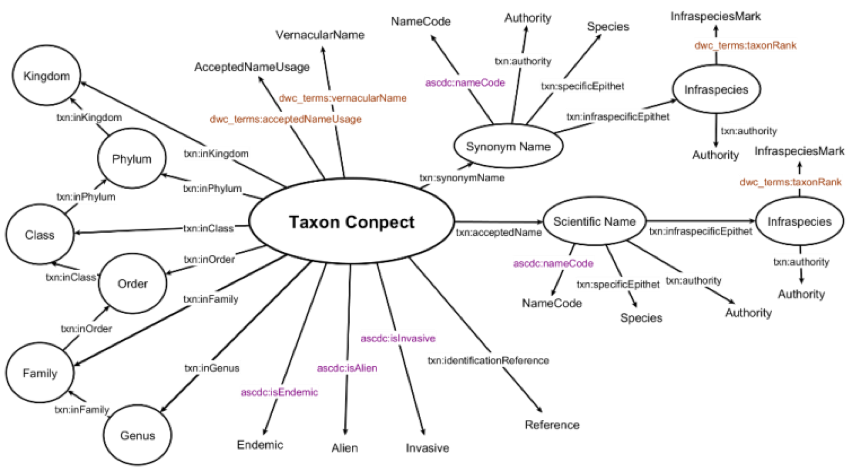
As a first step in reconciling these heterogeneous data contents while preserving their original meaning, we analyzed the original records and designed the semantic data model by reusing one generic (dcterms) and seven other specific vocabularies: TaxonConcept (txn), Darwin Core (dwc), Open Vocabulary (ov), Wgs84 (geo), Sampling Features (sam), Schema.org (schema) and Creative Commons (cc). The metadata of each record is further structured in 24 specific fields, which are particularly focused on the reconciliation of the biological data.
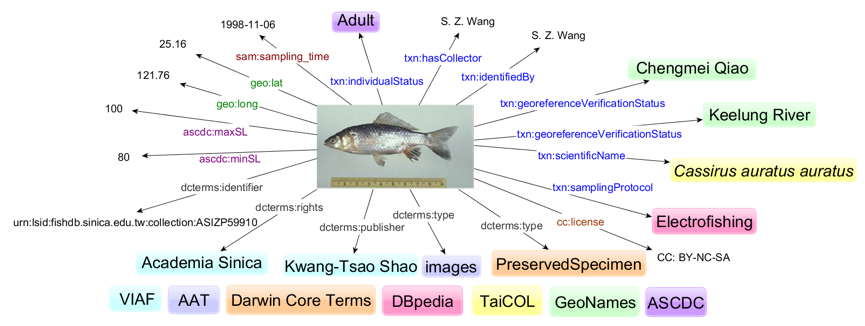
In general, the semantic data model of the fish dataset is based on the European Data Model (EDM) and modified according to the specific needs of the collection. Each record is composed of two parts: a descriptive metadata record for the digitized item (ProvidedCHO), and the item's digital representation (WebResource).
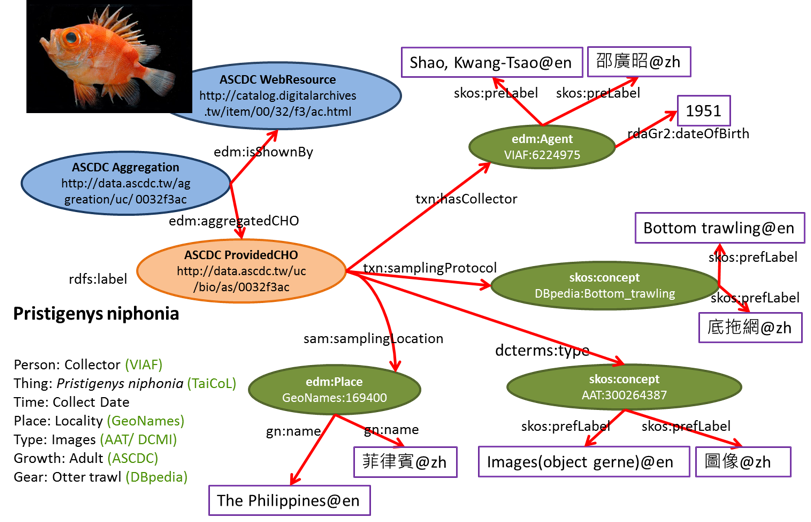
To enrich the data content seven LOD-based external authority vocabularies are reused (iAAT, DBpedia, DwC terms, GeoNames, VIAF, TaiCoL and ASCDC), especially for describing the developmental stage of a fish. In addition, specific biological terms, such as Adult, Larva, Juvenile, Young-Adult which were not found in existing vocabularies, are included and maintained as controlled vocabularies by ASCDC. These multilingual external resources are adopted to enrich the data in different data fields. For example, VIAF is reused to enrich the information on persons and institutes, while GeoNames is for detailing the geographical information; AAT, DwC Terms for data types; Catalogue of Life in Taiwan (TaiCoL) for scientific names. The multilinguality of these controlled vocabularies can enhance the readability of the TaiUC data, whose contents are originally conceived for the Chinese users.
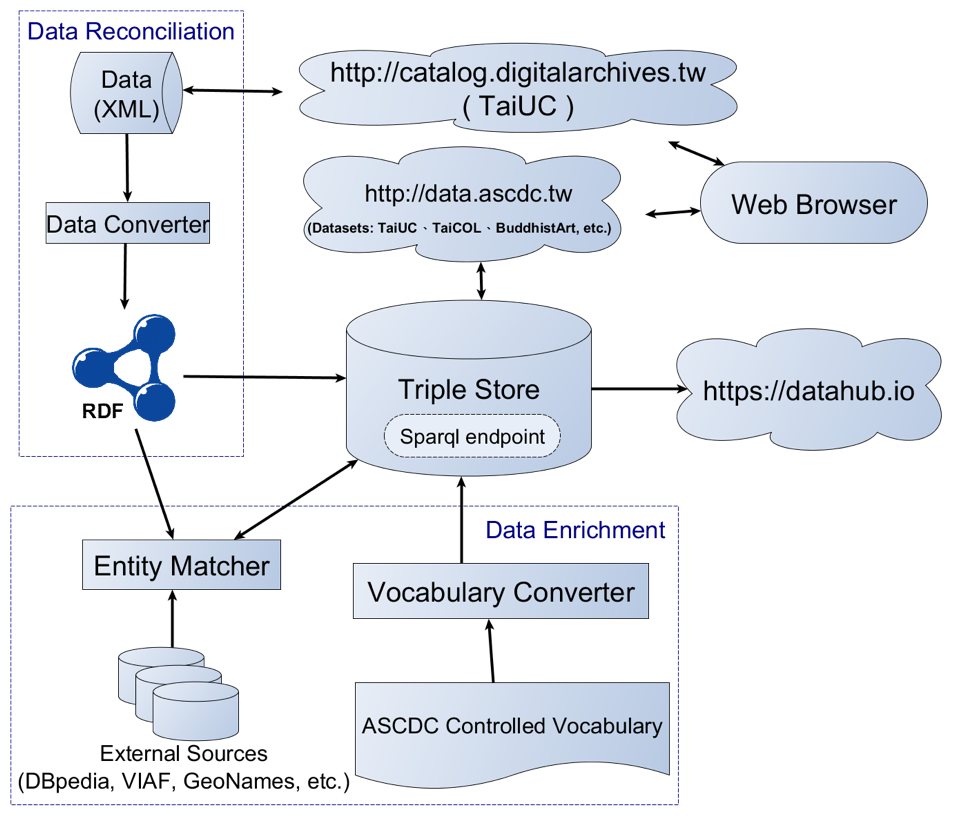
In the light of technical process, the project developed its own triple parser program by using the Apache Jena framework according to the data model. Thus, those triple-parsed metadata XML files are then converted into RDF format and uploaded in the triple store. The RDF-XML is then used as input in the entity matcher to map to the external authority files. In the triple store the data will be linked to their matched external resources which will enrich their data meaning. For data enrichment, entire or parts of datasets from AAT, DBpedia and GeoNames are downloaded and input in the entity matcher to mapping with the string in the RDF/XML. By applying the specific designed JAVA program, the matched data string text will be replaced by URIs.
In addition to converting the original TaiUC metadata to Linked Open Data, a special challenge in the project is how to deal with the Chinese scientific and vernacular name in the original metadata, given that there is currently no biology-oriented LOD dataset in Taiwan. As result, we convert the entire dataset of Catalogue of Life in Taiwan (TaiCoL), which is available online and maintained by ASCDC, into a machine-readable dataset in RDF format and uploaded in the triple store. Data concerning taxonomic concepts in TaiUC are thus linked to the TaiCoL LOD dataset.
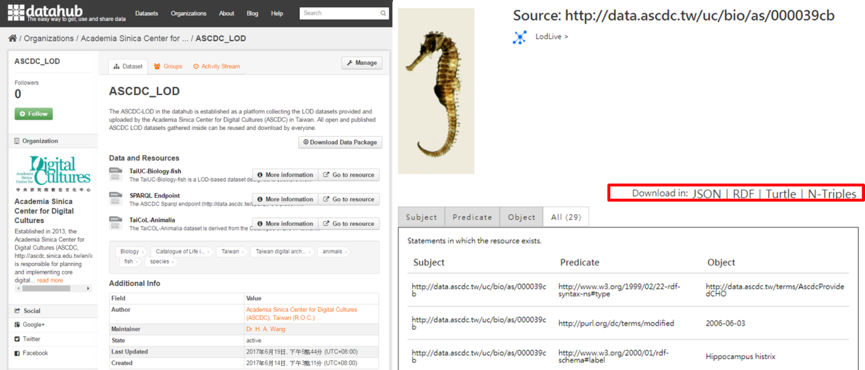
Accessibility to Data Consumers
To optimize the data reusability, the entire package, both TaiUC-Biology-Fish and TaiCoL-Animalia datasets, is uploaded in the datahub and downloadable in N-triples. In the ASCDC’s Sparql endpoint, users can either perform a keyword search of the data collection or retrieve it after entering specific biology-related criteria such as sampling location, sampling time, sampling protocol, developmental stage, head length or body length of a fish. The open nature of the platform means that it is possible to download the whole fish dataset or metadata of a single digitized item in different formats including json, rdf, turtle, and n-triples. All the metadata records are released under CC0, while the digital images are released after request of the original rights holders under different CC regulations. In addition, the open-source lodlive application is used to help visualize the triple structures, assisting users in better understanding the data model and its data.
Impacts on Culture Heritage
Since mid-19th century many Westerners, - for example, the Englishman Robert Swinhoe (1836-1877) - came to Taiwan to collect a variety of animal and plant species for research. Some of their collected species, drawings and reports were brought back to Europe, and later became part of museum collections albeit distributed across different institutions. The TaiUC fish collection is not only the first biology-oriented LOD dataset in Taiwan, but also preserves the achievement of species collection by local biologists for more than a half century. Therefore, in the datasets we first apply the property as “schema:isRelatedTo” to link the scientific names in Europeana with TaiUC fish data and then to identify the sampling location in both datasets. Hence the exploration of the travelling traces of these sampling records, in some cases collected in what was then known as the Republic of Formosa over 100 years ago, can be achieved, though the original digitized object might be scattered all over the world.
In this paper we present DIVE+, which aims to advance the way in which researchers and general audience interact with heterogeneous online heritage collections by allowing an integrated exploration of objects of these collections. Within the context of DIVE+, we developed various data enrichment and linking strategies, resulting in an interconnected dataset. We especially focus on events. Rather than restricting the type of events, we include named historical events (Second World War), unnamed historical events (The Dutch prime minister making new year’s speech) or personal events (Death of a person). This is in addition to person, concept and location-based enrichments, as events can be combined into event narratives as context for searching, browsing and presenting cultural heritage collection objects. DIVE+ is the result of a true interdisciplinary collaboration between computer scientists, humanities scholars, cultural heritage professionals and interaction designers. DIVE+ is integrated in the national CLARIAH (Common Lab Research Infrastructure for the Arts and Humanities) research infrastructure.
User studies The design and strategies developed within DIVE+ are based on requirements gathered through extensive user studies in the Digital Humanities domain. DIVE+ is continuously being updated and improved based on continuous user studies. These studies include investigation into the different hermeneutic needs of different kinds of Digital Humanities researchers - for example, historians, students and journalists. They also include more focused user studies on the exploratory interface and the ways in which it supports the various types of search and browsing of the users. One of the outcomes of these studies is a shared need for a tool that supports not only serendipitous exploration, but also the construction of narrative building blocks, which can be expanded to narratives at a later stage. DIVE+ supports the creation, saving and sharing of explored connections between objects, events, persons, places etc. in the form of so-called proto-narratives[1].
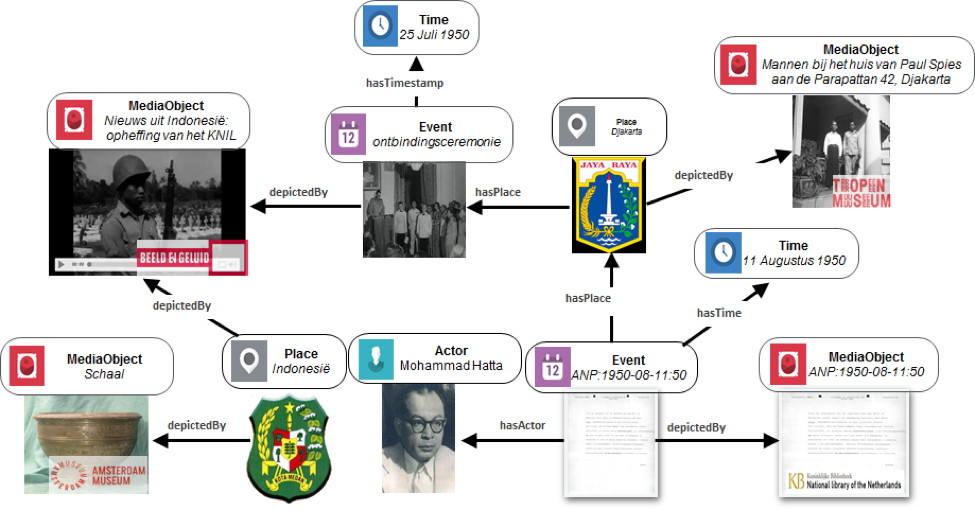
Figure 1: visualisation of the knowledge graph, showing relations between events, persons, places and objects from different collections
Data sets The current version of the DIVE+ tool connects four different Dutch heritage collections:
1. OpenImages.eu news broadcasts as archived by the Netherlands Institute for Sound and Vision consisting of 3,220 videos published on the Open Images platform.
2. ANP Radio News Bulletins. These are scans of 197,199 typo-scripts which were read aloud on broadcast radio in the period 1937-1984 and are now archived by the Dutch National Library.
3. Amsterdam Museum collection. This concerns 73,447 cultural heritage objects from the Amsterdam Museum collection.
4. Tropenmuseum collection. This consists of 78,270 cultural heritage objects from the collection of the Tropenmuseum related to ethnological research.
The datasets and structured vocabularies that accompany them are available as Linked Data and imported in an RDF triple store.
Enrichment To make an interconnected knowledge graph which can be used for exploratory search out of the four heterogeneous data sources, we employ various strategies for enrichment. We establish mappings from collection-specific metadata to generic terms for each of the collections. This ensures that queries on this generic level (such as retrieve a textual description for an item) return relevant results from each of these collections.
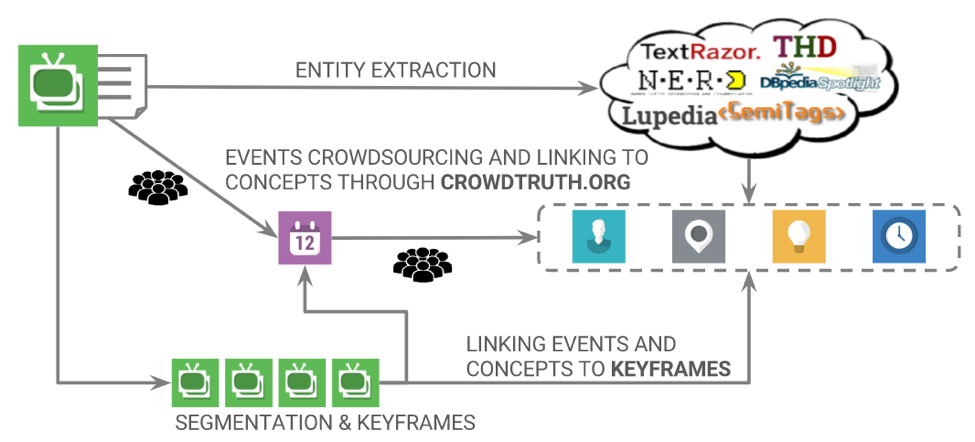
To enrich objects with (shared) persons, places and most importantly events, we establish a hybrid pipeline (see Figure 1) that combines Natural Language Processing and crowdsourcing to identify and verify these entities from object descriptions. In the current version of the pipeline, we first use various Named Entity Recognition (NER) tools to extract the set of relevant concepts from object description. Rather than selecting based on majority voting, we harness the disagreement between different extractors to achieve a more diverse set of entities, preserving initially all extracted entities. Each media object description is then used in a crowdsourcing task where the crowd is asked to highlight events mentioned in the text. The NER and crowd output are then aggregated into a second crowdsourcing task that aims to create links between the detected events and their participating entities. We use the CrowdTruth[2] platform and methodology in order to perform all the crowdsourcing steps and experiments.
Using alignment services such as Cultuurlink, we establish correspondences between the persons, places and events found in our enrichments and structured vocabularies (including GTAA thesaurus). In total, our enriched knowledge graph contains more than 350,000 objects, described by nearly 200,000 events, 291,000 persons and 66,000 geographical locations, for a total of over 15 Million RDF triples. Figure 2 shows a sample of the knowledge graph.
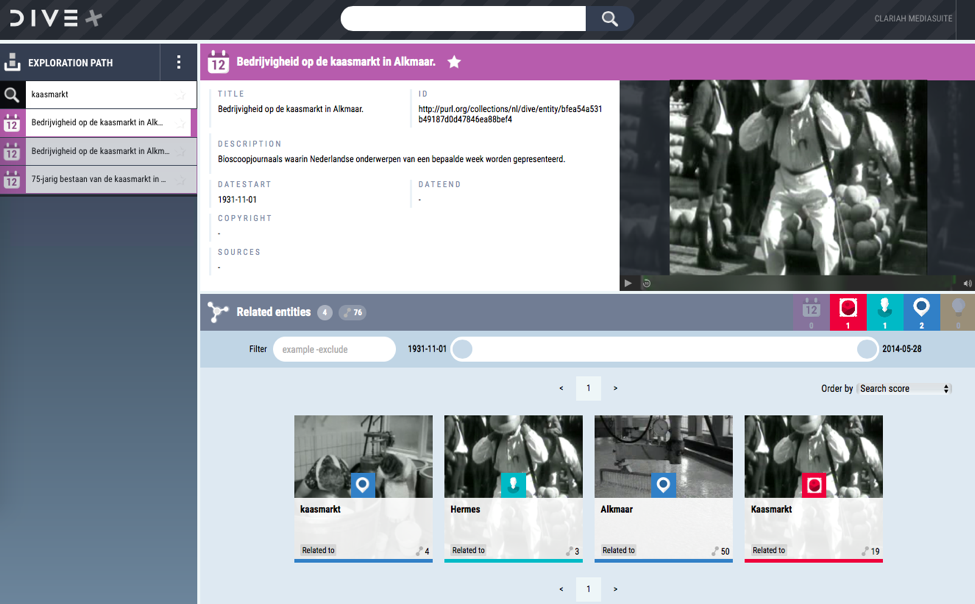
Exploration This interconnected graph can then be accessed through an innovative exploratory browser of which a screenshot is shown in Figure 3. Key features of this interface is that it supports exploration by presenting the user with objects, events, places and people that are related to the object the user is viewing. It allows for close inspection of the heritage objects themselves (photos, scans or videos) as well as of the metadata and relations. The user can use full-text search and filters to find other interesting objects.
Finally, to support the construction of event-based (proto-)narratives, users build and save personal exploration paths and share them with other researchers. This feature supports the practice of digital hermeneutics, where scholars or other users can construct the aforementioned proto-narratives around persons, places or objects based around events.
Technologies DIVE+ builds on Linked Data principles to represent heterogeneous datasets. It uses a hybrid NLP/crowdsourcing pipeline and interactive alignment tooling to enrich these datasets and to interlink them with structured vocabularies. The connection between User Interface and Triple store is done through an API layer that converts generic UI commands to SPARQL queries, which are executed on a separate triple store. This separation of interface and backend allows for more flexible re-use of UI and data components. This allows for the DIVE+ exploratory functionalities to be integrated in the CLARIAH MediaSuite via a sustainable infrastructure that allows flexible use of data collections and functionalities fitting the research needs of scholars.
Potential impact on the Cultural Heritage domain
DIVE+ presents several innovations that push the boundaries of cultural heritage collection browsers. First of all, it integrates several strategies for continuous collection enrichment. These strategies include crowdsourcing and the use of (expert) user feedback. This means that collections that use the platform can be constantly improved with respect to metadata for specific end-users. In the library and heritage domain, most digital tools focus on search and filtering. DIVE+’s exploratory interface focuses on interactive exploration of connected collections allowing for discovery of serendipitous links between elements from different collections. This services important needs of scholars and other users. The DIVE+ tool implements a number of elements that directly address the needs of humanities scholars. Based on extensive user studies, we have identified the need to have interactive tools that better connect to research practices. With DIVE+, we developed a platform that directly aims to address the need for digital hermeneutical research through the construction of (proto-)narratives.We expect that more platforms will incorporate such exploratory elements.
Short video about the DIVE+ Project
[1] Akker, C.v.d., Legene, S., Erp, M.v., Aroyo, L., Segers, R., Meij, L.v.D., Ossenbruggen Van, J., Schreiber, G., Wielinga, B., Oomen, J., et al.: Digital hermeneutics: Agora and the online understanding of cultural heritage. In: Proceedings of the 3rd International Web Science Conference. p. 10. ACM (2011)
[2] Aroyo, L., Welty, C.: The Three Sides of CrowdTruth. Journal of Human Computation 1, 31{34 (2014)
The lowered technical barriers and costs of 3D capture (especially photogrammetry) within the museum and archaeology domains has seen an explosion of 3D data within the cultural heritage sector over the last few years. This is because of low-cost or free photogrammetry software and improvements in hardware that have made it possible to process large photo collections on personal computers (as opposed to the high-powered servers required 10–15 years ago). Furthermore, the introduction of off-the-shelf drones has made it possible to capture architecture and archaeological sites more efficiently than ever before. Cultural heritage 3D models (from artifact scans to excavation trenches and entire sites) are being published to the web by many organizations through a wide variety of information systems. Many organizations have turned to Sketchfab as the primary mode of publication, but others are using home-grown systems. In truth, 3D publication is the Wild West. There aren't even readily agreed-upon open standards for the models themselves, let alone metadata standards, publication frameworks, or APIs for accessing models/metadata (in contrast to 2D images through IIIF standardization).
It’s for this reason that I'm discussing 3D models at LODLAM—metadata standards, emerging practices in archiving and disseminating models, etc. While I myself am not a producer of 3D models, as a developer working on Linked Data systems for both numismatics and Greek pottery, my interests are in harvesting relevant 3D models from content producers (museums or individuals) and making them available to relevant scholarly audiences (and the general public), either for domain-specific projects such as Kerameikos.org or broader aggregations like Pelagios, DPLA, or Europeana. In this regard, I put together a proof-of-concept to demonstrate at LODLAM: adapting a proposed extension of the Europeana Data Model presented at ALA to capture basic metadata about a 3D model hosted by Sketchfab. You can read more about it here.
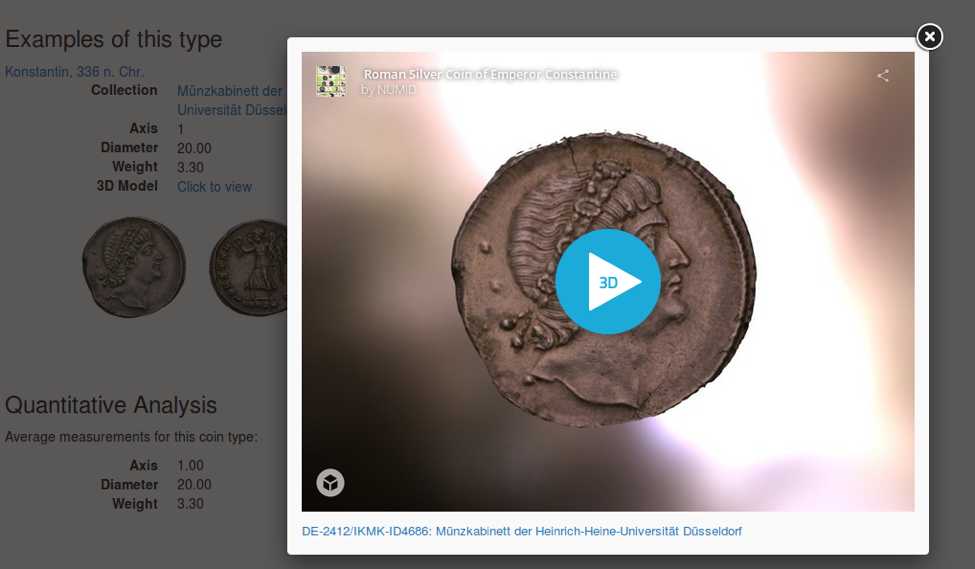
There is a general awareness in the GLAM sector of the growing potential for 3D models as tools for access, analysis, preservation, and teaching. These use-cases present new challenges for long-term maintenance and dissemination. As a regular participant in the Computer Applications in Archaeology (CAA) conference, I have seen presentations on 3D infrastructure and web-based rendering for several years, but many of these projects have not evolved beyond the prototype phase. With many museums and libraries involved in either the data capture or data archiving aspect of the 3D content, a number of initiatives have emerged to get a handle on this amorphous world of cultural heritage 3D. One of the most notable initiatives is the Horizon 2020-funded PARTHENOS project, and their recent white paper, “Digital 3D Objects in the Arts and Humanities: challenges of creation, interoperability and preservation.” Similar discussions have taken place in the National Endowment for the Humanities-funded “Advanced Challenges in Theory and Practice in 3D Modeling of Cultural Heritage Sites,” and subsequent conference sessions at CAA and Digital Humanities 2017. Recently, Duke University posted a software developer job to extend their Hydra-based institutional repository to accommodate 3D models. Much work is being done in different communities, but it isn’t clear how much collaboration is occurring between them.
One of my goals in the proposal of the session at LODLAM was to encourage specialists in different domains of cultural heritage to sit down and create channels of communication in order to unite these disparate initiatives. One such platform may be in the IIIF Slack group. There had been discussion at the IIIF conference earlier in the summer about extending IIIF principles toward 3D. While IIIF for 3D is still many steps down the road (after standardized, open model formats and metadata schemas), the principles of standard APIs and scholarly annotation are integral to a broader vision for integrating 3D content into the cultural heritage data cloud. Taking Greek pottery as an example, 3D models are much preferred over 2D photography for viewing inscriptions and iconography, and if 3D models can be annotated following the same standards we see in IIIF (Web Annotation RDF), scholars will be able to view all objects depicting, say, Dionysus, regardless of the 2D/3D medium of capture. I hope that LODLAM can serve as a bridge to facilitate new collaborations in this domain.
Our session was relatively small compared to some others at LODLAM, as the content is fairly specialized and not necessarily applicable across all domains in the way the controlled vocabularies or ontologies are. However, the small group enabled a focused and productive discussion. The full minutes of the LODLAM session are available here.
The Omeka team has a deep commitment to helping our users produce interoperable and shareable metadata. We also have a deep commitment to making the publication of cultural heritage artifacts, whatever their form, as easy and web-friendly as possible. The increasing availability of Linked Open Data, especially from services such as Getty and the Library of Congress, as well as data from the Digital Public Library of America and Europeana, made the orientation toward LOD in Omeka S a natural choice. Sometimes, though, our technological commitments conflict. This article lays out some of these challenges and how we addressed them in our newest product, Omeka S.
Omeka S embraces a renewed effort to facilitate high quality, interoperable metadata by building LOD into the heart of both the user interface and the API. All calls to the API, internally and externally and use JSON-LD structure. That is the easy part. What’s more difficult is the problem of creating a user interface that supports the goal of easy metadata entry while also incorporating the complex LOD structures. Indeed, because Omeka S is also anticipated to be used in educational settings, we need to find a good balance between exposing RDF and making it still accessible to students who have no prior knowledge of RDF.
Metadata entry in Omeka S therefore allows string text entry, references to internal Omeka S resources, and URIs to external resources for any available RDF property.
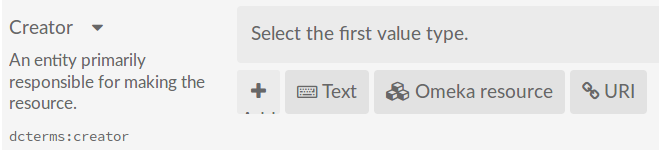
Figure 1: creator
The first hurdle we encountered was the “simple” task of choosing the properties to use for describing an item. Omeka S supports Dublin Core, Dublin Core Types, the Bibliography Ontology, and Friend Of A Friend. That’s a total of 184 properties and 105 classes – an overwhelming number of potentially useful descriptive elements. On the item creation page, then, we created a filtering feature allowing, for example, to start typing “title”, and limiting the properties to select from accordingly.
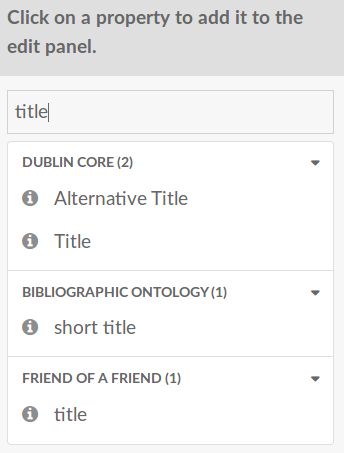
Figure 2: propertySelect
Even with that simplification, though, we saw that there was still a burden of assumed knowledge. It is fine to have a way to quickly select the property you want; but what if you are inexperienced, and do not yet know which properties to focus on in your organization’s workflow and product? The four vocabularies Omeka S supports are intended to cover a wide range of possible needs, but in many (if not most) cases, only a very small subset will be relevant to any one project or collection. Omeka S also makes it easy to import additional vocabularies that might or might not be relevant to other projects within a single Omeka S installation.
Thus, to guide metadata creation, we built in the concept of a “resource template”. An administrator with the knowledge the metadata to focus on for a particular project can do the intellectual work of pre-selecting the properties to be used People working on metadata entry will then automatically see those properties after selecting the designated resource template. Omeka S comes with a “Base Resource”, which conforms to the properties required by the Digital Public Library of America metadata profile.

Figure 3: Edit Resource Template screenshot
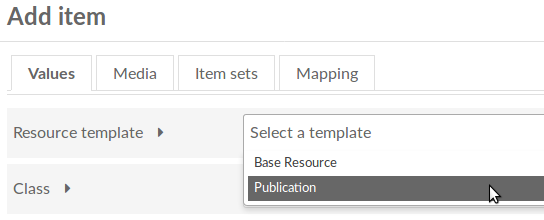
Figure 4: Select Resource Template screenshot
The resource templates also guide linked metadata creation by allowing the definition of data types for any property. The types are supplied by modules that extend Omeka S. Typically, they allow metadata creators to specify an external URI as the LOD metadata reference, along with an appropriate label. For example, the Value Suggest module can be used to suggest that the property has a value from a variety of LOD URI providers, such as Getty’s ULAN.
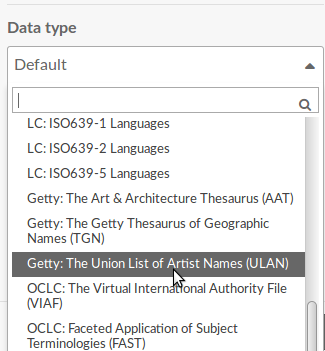
Figure 5: Value Suggest screenshot
Similarly, the contributed Rights Statement module allows use of statements from RightsStatements.org as LOD.

Figure 6: Rights Statements screenshot
Those affordances make for good Linked Open Data. But they also point to the complexity of uniting LOD sources, and to the complexity of easy and accessible web publishing for human readers.
For instance,The Value Suggest module has to use slightly different code for obtaining data from Getty, Library of Congress, and OCLC and massage it into a consistent data format of labels and URIs for creating the dropdowns pictured above. The Rights Statements module does some more direct data manipulation, explicitly defining a map between the URIs and appropriate labels for the dropdown.
Omeka S team is grateful for the increased LOD resources available for all of us to facilitate the creation of Linked Data. However, some challenges remain in creating easy interfaces, both in the user interface and in the interfaces with Linked Data sources. It might be the step missing between Linked Open Data and Linkable Open Data, which we will continue to address.
For more information about Omeka S or to play in our sandbox, please visit the Omeka S site.