Letter from the editors
Welcome to the very first issue of EuropeanaTech Insight, a multimedia publication about research and development within the EuropeanaTech community.
EuropeanaTech is a very active community. It spans all of Europe and is made up of technical experts from the various disciplines within digital cultural heritage. At any given moment, members can be found presenting their work in project meetings, seminars and conferences around the world. Now, through EuropeanaTech Insight, we can share that inspiring work with the whole community.
In our first three issues, we’re showcasing topics discussed at the EuropeanaTech 2015 Conference, an exciting event that gave rise to lots of innovative ideas and fruitful conversations on the themes of data quality, data modelling, open data, data re-use, multilingualism and discovery.
Welcome, bienvenue, bienvenido, Välkommen, Tervetuloa to the first Issue of EuropeanaTech Insight. Are we talking your language? No? Well I can guarantee you Europeana is.
One of the European Union’s great beauties and strengths is its diversity. That diversity is perhaps most evident in the 24 different languages spoken in the EU.
Making it possible for all European citizens to easily and seamlessly communicate in their native language with others who do not speak that language is a huge technical undertaking. Translating documents, news, speeches and historical texts was once exclusively done manually. Clearly, that takes a huge amount of time and resources and means that not everything can be translated... However, with the advances in machine and automatic translation, it’s becoming more possible to provide instant and pretty accurate translations.
Europeana provides access to over 40 million digitised cultural heritage offering content in over 33 languages. But what value does Europeana provide if people can only find results in their native language? None. That’s why the EuropeanaTech community is collectively working towards making it more possible for everyone to discover our collections in their native language.
In this issue of EuropeanaTech Insight, we hear from community members who are making great strides in machine translation and enrichment tools to help improve not only access to data, but also how we retrieve, browse and understand it.
So here it is, EuropeanaTech Insight Issue 1!
Automatic Solutions to Improve Multilingual Access in Europeana
Juliane Stiller, Berlin School of Library and Information Science at Humboldt-University
Europeana has the potential to become a truly multilingual digital library – offering content in over 34 languages to an audience speaking an even larger variety of languages. Matching people’s needs with the content in a digital library is not a trivial challenge, especially in a multilingual context. Europeana has implemented automatic solutions for overcoming the language barrier and for improving multilingual access, such as query translation and automatic enrichment with external multilingual vocabularies.
Making Europeana multilingual requires adjustments on several different dimensions. Both the interface and portal display should be adaptable to the users’ preferred languages. This can happen automatically through detecting the users’ browser languages or by setting a cookie after the users have manually chosen their preferred language. Furthermore, the system needs to offer ways for people to discover objects through searching and browsing, which might be described in languages they are not familiar with.
It is only recently that Europeana has offered query translation. By changing their settings, people can determine up to six languages that they want their queries translated into. When the user submits a query, Europeana calls on the Wikipedia API, translations are retrieved and the query with all language variants is constructed (Kiraly, 2015). With the implemented process and the decision to return the user’s queries in all the user’s chosen target languages, Europeana overcomes the challenge of automatically determining the query language. Defining the source language is hard as queries are often very short, consisting only of one or two terms. In a multilingual environment, 39% of the queries belong to more than one language (Stiller et al., 2010). This is true for named entities (places, persons…) such as “London”, which make up most of the queries in cultural heritage digital libraries. But it is also true for terms such as “Strom” which means “Power” in German and “Tree” in Czech.
Another way to improve multilingual search and browsing is by enriching data with multilingual datasets that can deliver translations of metadata keywords. Europeana enriches four different types of metadata fields, namely agents, geographic locations, concepts and time spans. There are several different target vocabularies for the various enrichment types. For example, concepts found in the dc:subject and dc:type field are enriched with the GEMET thesaurus, whereas geographic entities are enriched with GeoNames
Figure 1 shows an example of a Europeana object that was enriched with all language variants of the original object creator: Johannes Vermeer. Due to the enrichments with DBpedia, the objects can be found with queries also using different variants of Vermeer’s name such as Jan Vermeer in Italian.
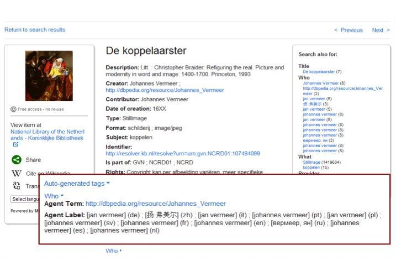
As a big portion of Europeana’s metadata is enriched automatically, evaluation workflows need to be in place to monitor the quality of these automatic enrichments (Stiller et al., 2014).
Incorrect enrichments that might occur when the language of the metadata is not matched with the language of the target term in the vocabulary lead to a devaluation of curated metadata. Due to the multilingual dimension, semantically incorrect enrichments propagate to different languages as wrong keywords might be added in several languages. Irrelevant search results follow, impacting the user experience and leading to a loss of trust from providers. Therefore, it is important to evaluate the processes ensuring that the automatic processes improve access and do not introduce errors. A first effort to do exactly this was undertaken by the Task Force on Multilingual and Semantic Enrichment Strategy. In their report, seven use case collections from Europeana were analysed to derive recommendations for enrichment processes.
Multilingual access is a continuing undertaking. Automatic solutions targeted on overcoming language barriers for searching and browsing have to be adapted constantly. For that, best practices need to be developed and fostered by Europeana. The EuropeanaTech community and network are essential to tackle multilingual issues and guide Europeana. One example of such a community effort is the recently announced Task Force on Enrichment and Evaluation joined by many experts from the EuropeanaTech community.
References:
Péter Király (2015): Query Translation in Europeana. Code4Lib Journal, Issue 27, http://journal.code4lib.org/articles/10285
Juliane Stiller, Vivien Petras, Maria Gäde, Antoine Isaac (2014): Automatic Enrichments with Controlled Vocabularies in Europeana: Challenges and Consequences. In: Digital Heritage. Progress in Cultural Heritage: Documentation, Preservation, and Protection. EuroMed 2014, pp. 238-247
J. Stiller, M. Gäde, and V. Petras (2010): Ambiguity of Queries and the Challenges for Query Language Detection. In: CLEF 2010 Labs and Workshops Notebook Papers, ed. by M. Braschler, D. Harman and E. Pianta.
Multilingual Linked Data
Daniel Vila-Suero and Asunción Gómez-Pérez, Universidad Politécnica de Madrid, Spain
Languages and Linked Open Data
Linked Open Data (LOD) and related technologies are providing the means to connect high volumes of disconnected data at web-scale and producing a huge global knowledge graph. This graph is enabling the development of unprecedented technologies such as highly advanced question answering systems or personal assistants. One common aspect of this new breed of technologies is their increasing need to understand and deal with human languages.
In the article “Challenges for the Multilingual Web of Data” (2011) we identified the challenges to be faced when dealing with language (e.g., how to publish LOD with language information, how to query data that can be in different languages, etc.). Since 2013, we have also been analysing the spread of language information across datasets in the LOD cloud (see “Guidelines for Multilingual Linked Data” (2013). Our latest analysis (Figure 1) showed that there are a fair amount of multilingual datasets available, most of the text is not marked up with its language, and English is the predominant language although the amount of data in other languages is growing.
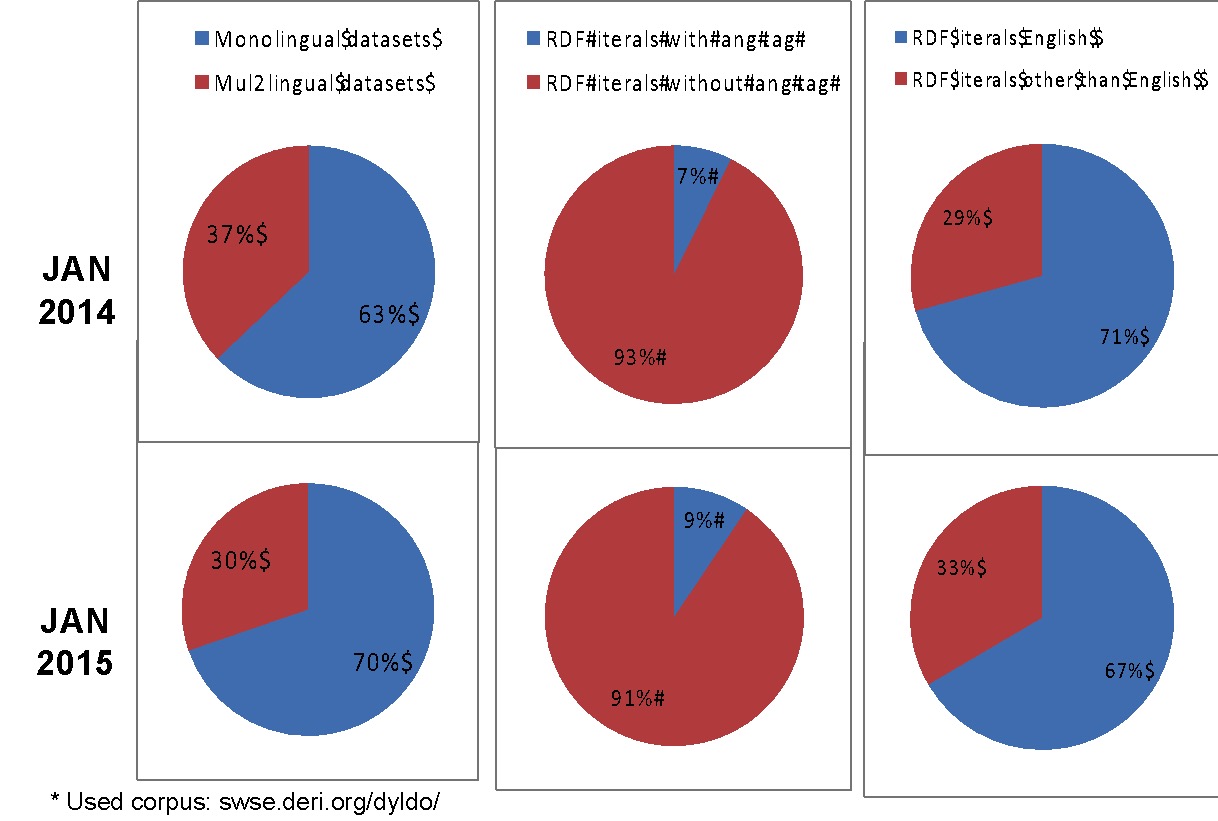
Connecting both our theoretical and empirical analyses, we have come to the conclusion that there is still a lack of awareness on the importance of and the guidelines for publishing LOD with language information. But why do publishers need to care about language information? Let’s see an example.
Why add language information to your datasets?
Cultural institutions across Europe are currently making large amounts of linked data available on the web. Prominent examples include Europeana, the National Library of France, and the National Library of Spain. These connected datasets can be used to provide enhanced experiences to people when searching and browsing library information (Figure 2).
This already showcases the power of Linked Data, but can language information really help data publishers to go a step further and add value leveraging language information?
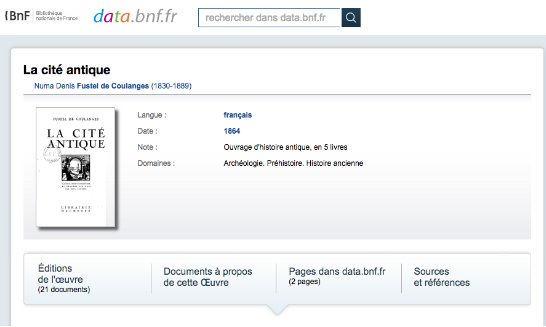
Imagine a humanities researcher from Spain looking for digitised materials about ancient cities (in Spanish “Ciudades antiguas”) and performing a search in datos.bne.es (Figure 3).
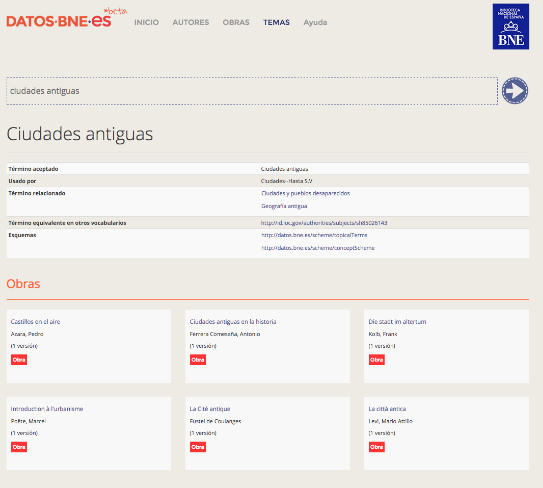
Figure 3. Search for Ancient cities in datos.bne.es
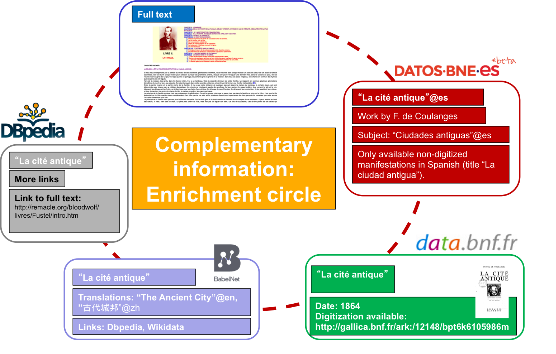
Although datos.bne.es is able to provide almost 50 different results, none of them contain digitised materials. However, from the set of results, a recurring resource is “La Cité Antique” by “Fustel de Coulanges”. If the datos.bne.es system could recognise the title in French, it could automatically expand the results and answer more broadly and accurately. The system could compute the most frequent titles and their languages and then query authoritative sources of each language. For instance, it could query data.bnf.fr to find digitised copies of these works (see figure 4). Moreover, it could further enrich the results using linguistic resources such asBabelNet, creating a “multilingual enrichment circle” (see figure 5).
How to add language information
But, how can we connect LOD and languages? There are several methods and in “Publishing Linked Data: the multilingual dimension” (2014) we discuss some of them.
The simplest way is to attach ISO language tags to labels using the standard mechanism provided by RDF (Resource Description Framework).This approach is easy to implement but is limiting for complex scenarios.
A second option would be to use a more sophisticated vocabulary for representing linguistic information. TheW3C Ontolex Community Group will shortly be publishing a vocabulary. This vocabulary can be used to provide richer information about linguistic features such as gender, number, cultural variations, etc.
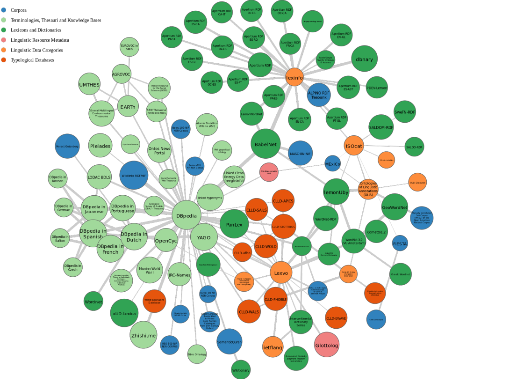
Finally, a third way is emerging, boosted by the growth of a cloud of Linguistic Data known as the “Linguistic Linked Open Data (LLOD) cloud” (figure 6). It contains hundreds of linguistic resources published as LOD. Using the LLOD cloud, data publishers can link to language resources (terminologies, Lexica, Dictionaries, etc.) to automatically enrich their resources. For instance, datos.bne.es could link the resource “La cité antique” to BabelNet, a large multilingual dictionary, thus enriching the library information with translations and richer linguistic descriptions (as shown in figure 5).
Where to look next
There are already several efforts to advance the topic of Multilingual Linked Data. TheEU Lider project is building a community around the topic of Linguistic Linked Data, multilingualism and content analytics. In Lider, together with the W3C, we are working on making linguistic resources such as LOD available, providing guidelines, a reference architecture, and defining a roadmap for the coming years. In this line, theW3C LD4LT (Linked Data for Language technology) and theW3C BPMLOD (Best Practices for Multilingual Linked Open Data) groups are working together with industry and academia to develop reference implementations and guidelines to help data publishers and consumers. If you are interested in these topics,please get involved!
Automated Translation: Connecting Culture
Spyridon Pilos, Head of language applications, Directorate-General for Translation
"Wouldn’t it be great if I could start using a public service in any Member State of the European Union from any place in the world and get the information in my mother tongue?" This simple question defines the vision that the European Commission has been supporting through numerous activities aimed at making it easier for public services to go online and connect to each other. Automated translation is part of this endeavour.
The European Commission has been involved in machine translation (MT) for more than 30 years, offering machine translation services for a few of the official EU languages to public administrations. July 2013 saw the launch of a new generation of the Commission machine translation service, covering all 24 official EU languages.
The service, going by the name of MT@EC, was developed by the Commission’s Directorate General for Translation and was partially funded by the ISA programme, which supports interoperability solutions for public administrations. It was built by combining the Moses system, a statistical machine translation technology developed with co-funding from EU research and innovation programmes, with the vast Euramis translation memories, comprising over 900 million sentences in 24 languages produced by the EU’s translators over the past two decades.
MT@EC follows the technological shift from rule-based to data-driven MT which was made possible by the huge increase in processing power and storage capacity of IT systems in conjunction with the availability of large monolingual and multilingual text corpora in electronic form. Today, the capacity and the raw material needed to build MT systems at a reasonable cost is available to researchers and market players all over the world.
Statistical MT produces automatic translations using "engines" that apply processes and algorithms to identify the most frequent translations of parts of sentences using enormous phrase tables, aka "translation models", and suggest ways to combine these into final translated sentences. The most appropriate translation is then chosen according to the "language model" built using high quality monolingual text corpora.
MT@EC is currently operated by the Commission and is available to EU institutions, public administrations in the EU Member States and through online services funded or supported by the Commission, like the Internal Market Information System, IMI, and SOLVIT, a service that can help you uphold your EU rights as a citizen or as a business if they have been violated by public authorities in another EU country.
In 2014, the Connecting Europe Facility was launched. This is an initiative aimed at deploying an ecosystem of digital services infrastructures (DSIs), one of which is Europeana. A key element of this DSI ecosystem is a set of reusable core building blocks, which include an automated translation platform (CEF.AT). This platform will have as starting point the existing MT@EC service, scaled up and adapted to serve the specific needs of CEF DSIs. Ultimately it will also be used by other public pan-European services and public administrations across the EU.
CEF.AT includes a "Language resources" component, which provides the data and tools which underpin the "MT service" component, which delivers the machine translations produced using the engines built in the "MT engines factory". Together these serve the specific needs of the different DSIs supported by CEF Work to deliver suitable solutions which will start in 2015 for a small number of DSIs. It will aim to provide adapted solutions and focus on the "factory" component, while the results will be piloted using the existing MT@EC service infrastructure.
Europeana could benefit from the possibility of using automated translation. It could use it to enable cross-border access to cultural content and services, allowing users to find content which is useful for them, whatever language it was originally written in. It could also eventually be used to enable cross-lingual searching. The CEF.AT platform is meant to develop custom solutions for the various DSIs; Europeana could prove to be a very challenging customer because of the broad range of content and metadata, along with the variety of formats used. But it should also be a very valuable partner, as it includes libraries and archives in the EU which are key sources of valuable text corpora for all EU languages. Such corpora can help improve automated translation services for all users.
Automated translation can help connect culture, as we move towards an interconnected multilingual Europe.
Big Data, Libraries, and Multilingual New Text
Jussi Karlgren, Gavagai and KTH, Stockholm
Ever since the development of writing and the printing press, lowering publication and dissemination thresholds has been the goal of information technology. Technology developments in recent years have quite dramatically accomplished this. These advances have given rise to new types of text - dynamic, reactive, multilingual, with numerous cooperating or even adversarial authors. Many of these new text types remain true to established existing textual genres and conform to standard usage. Others break new ground, moving towards new emergent textual genres enabled by technological advances. While heterogenous as a category, these new text types share features in that they are subject to little or no editorial control compared to traditional media which has higher publication thresholds.
This means libraries have more material to be considered for collection, preservation, maintenance and making available. What should be preserved, if the individual objects are of less archival interest than the stream and the discourse they are part of? Should individual forum posts or microblog comments be preserved? Should all various versions of some published essay be retained for future study? Libraries struggle with these questions daily.
The role of a library (and other memory institutions) is - among other things, but most importantly for the purposes of this discussion - to ensure an authentic record of knowledge created and accumulated by past generations, in order to make advances in research and human knowledge possible and to preserve the world’s cumulative knowledge and heritage for future generations.
It is debateable that new texts such as blog posts or chat logs might not be what should be captured and preserved for that purpose, especially since their authors might not want them to be stored. After all, we do not collect informal spoken interactions between people systematically. Instead, what should be captured and preserved is the sense and the impact of the stream of text. We should build representations which capture not only the individual expressions but the stance, the tenor, and the topical content of discourse. This is a technological challenge those of us who work with language technology are happy to address in future research projects!
Bringing multilinguality into this equation will make it even more complex. New text is inherently, to an increasing degree, multilingual. It is not only that the documents may be written in different languages, but that new texts frequently interweave several languages within one document. How can we handle the technological challenges new text brings, if it is multilingual to boot?
This is not only a challenge, it is also an opportunity. We could build models which capture differences between what is said in various languages, compare them to each other. We can recount what is given in multiple languages, and what sort of materials are multilingual.
Most importantly, of course, libraries should formulate for themselves the questions they will want to answer about chatroom conversations, blog material, and even news items in a hundred years. And they should be prepared that these questions and answers may differ from the ones they ask themselves about materials collected in 1915. In any case, we should start building the technological infrastructure so that libraries can start thinking how to go about it!
Latvia translates with hugo.lv
Jānis Ziediņš, Culture Information Systems Centre; Rihards Kalniņš, Tilde
Today’s information society can be described as a grand conversation between the nations and people of the world. The biggest enabler of this great dialogue has been the internet, which allows people to share knowledge and information across the globe. However the diversity of languages fragments the information on the Web and makes it difficult to access.
One solution to this fragmentation can be found in the latest language technology, specifically machine translation. Technology solutions like machine translation tools allow members of one linguistic community to communicate with another and share knowledge and information, effectively bridging language barriers between people and nations.
Language technology has most often been developed for the larger, most widely spoken languages such as English, French, Spanish, German, Arabic and Chinese. Machine translation systems for these languages are readily available online, developed by global providers such as Google and Microsoft, and generally perform with high quality and accuracy.
Unfortunately, smaller languages – such as the other 6,000 languages spoken by the global population – are poorly served by these technologies. Machine translation systems for the world’s smaller languages often produce poor quality, inaccurate translations, if these systems are available at all.
The Latvian language, with less than two million native speakers, is a prime example of a smaller language that has traditionally been underserved by language technology such as machine translation. This has prevented many from accessing the great wealth of cultural heritage, educational content and media information produced in Latvian.
To rectify the situation and open up widespread multilingual access to knowledge, Latvia's Culture Information Systems Centre created its very own public machine translation service,Hugo.lv, based on open-source technology. The system was developed by Tilde.
The service features the world’s best machine translation system for translating Latvian content into English (and vice versa) and Latvian content into Russian. Hugo.lv opens up access to information in Latvian to citizens from around the globe, effectively “unlocking Latvia” for the world.
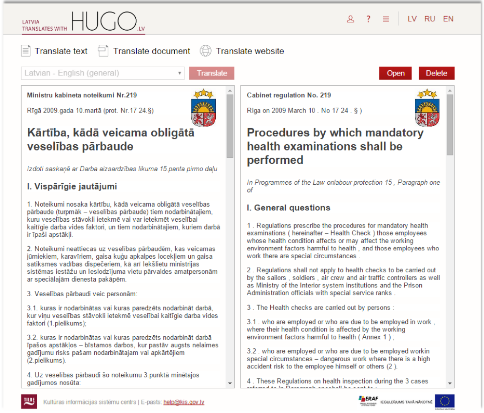
Hugo.lv is also integrated into Latvia’s e-services, so that various linguistic communities both in Latvia and abroad can access these services in multiple languages, promoting civic engagement and spreading e-democracy across the region.
Challenges
The first main challenge faced during the development of Hugo.lv was the lack of data sources to build the machine translation engines at the required level of quality. The small size of the Latvian language logically leads to a smaller set of data than might be found for larger languages elsewhere.
This is the central reason why the machine translation systems developed by large global providers favour larger languages and provide such poor quality for smaller languages.
The way we overcame this challenge was by collecting additional data for Latvian from a wide variety of sources. To this end, the developers used a number of novel methods. For data collection, new techniques were applied to process multilingual corpora. The developers also used tools to extract data from multilingual news sites, Wikipedia, and other comparable text collections.
In this way, the developers were able to build up the largest parallel data corpus for Latvian available in the world. As a result, the translation quality for Hugo.lv far outperforms generic online translation services such as Google Translate and Bing Translator.
Machine translation for cultural heritage
One of the activities planned in future is that Hugo.lv will help libraries, archives, museums, and other memory institutions make their content understandable to a wider range of individuals, sharing Latvian cultural information across the world. This will also guarantee that researchers around the world will be able to include Latvian cultural data in their studies, adding this cultural wealth to the memory of humankind and furthering preserving Latvia’s cultural heritage.
To ensure that, Culture Information Systems Centre together with the leading European language technology company Tilde worked on a feasibility study for using our machine translation technology for translating a diverse collection of cultural heritage.
The quality of machine translation was evaluated by calculating the BLEU score. The same process was performed using the translation systems offered by Microsoft and Google. The results show that the tailor-made statistical machine translation system is performing much better than others, which means that its output is easier to read and understand and the results are comparable to the texts translated by real translators.
Further information: www.kis.gov.lv
Contributing authors
Asun Gómez-Pérez is Full Professor in Artificial Intelligence, Director of the Ontology Engineering Group (OEG) and Director of the Artificial Intelligence Department at Universidad Politécnica de Madrid, Spain. In the library domain, her team is working with the National Library of Spain in the design and implementation of datos.bne.es. She is the LIDER project coordinator which deals with language resources and linked data for content anlytics.
Rihards Kalniņš is the International Development Manager for machine translation services at Tilde, a language technology company based in the Baltics. Tilde recently developed the Latvian public sector’s machine translation service Hugo.lv, for the Culture Information Systems Centre, as well as a set of MT tools for the 2015 EU Presidency. A former Fulbright scholar, Kalniņš holds a degree in philosophy from DePaul University. He has published articles in The Guardian, The Morning News, and the airBaltic inflight magazine.
Jaap Kamps is an associate professor of information retrieval at the University of Amsterdam’s iSchool, PI of a stream of large research projects on information access funded by NWO and the EU, member of the ACM SIG-IR executive committee, organizer of evaluation efforts at TREC and CLEF, and a prolific organizer of conferences and workshops.
Jussi Karlgren is one of the founding partners of Gavagai. He holds a PhD in computational linguistics, and a Ph Lic in Computer and Systems Sciences, both from Stockholm University. He has worked with research and development in information access-related language technology since 1987 at IBM Nordic laboratories, at the Swedish Institute of Computer Science (SICS), at Xerox PARC, at New York University, and at Yahoo! Research in Barcelona and with branding, trademark design, and language consultancy through his company Nordtal.
Spyridon Pilos studied mathematics at the University of Athens and joined the European Commission as a translator in 1992. Since 2009, he has worked at DG Translation as head of the language applications sector of the IT unit, where he led the development of the data-driven machine translation system MT@EC, operational since June 2013 and used by all EU institutions, public administrations and online services.
Juliane Stiller is a researcher at Berlin School of Library and Information Science at Humboldt-University in Berlin where she works in the EU-funded project Europeana Version 3 on best practices for multilingual access. She also studies researchers’ needs in virtual research environments in the project DARIAH-DE at the Max-Planck-Institute for the History of Science in Berlin.
Daniel Vila Suero is a PhD student at the OEG, and has an MSc in Computer Science. His research topics are multilingualism in the web of data, methodologies, digital libraries and Linked Data. He participated in the Spanish research projects related to Linked Data and multilingualism datos.bne.es and BabeLData. He is currently participating in the European project Lider.
Jānis Ziediņš has been working since 2004 in Culture information systems centre (Latvia) as project manager to help and lead IT projects in cultural sector. Janis has been involved in different types of culture related IT projects – most important of them – State Unified Information System for Archives and Joint Catalogue of the National Holdings of Museums, Digital Cultural map of Latvia, and recently in development of multi-lingual machine translation system Hugo.lv.