
Antoine Isaac
R&D Manager , Europeana Foundation

Juliane Stiller
Information Specialist , You, We & Digital
Vivien Petras
Professor for Information Retrieval , Humboldt University of Berlin
A Multilingual and Semantic Enrichment Strategy
The Task Force set out to find solutions to prevent enrichment errors and flaws that decrease the overall quality of the metadata in Europeana.
We are very happy to announce that the report from the EuropeanaTech Task Force on multilingual and semantic enrichment strategy is now published. The Task Force set out to find solutions to prevent enrichment errors and flaws that decrease the overall quality of the metadata in Europeana. To achieve this, we analysed six collections in detail. On the one hand, we wanted to discover problems in enrichments that were executed and on the other hand find out the reason for objects not being
enriched. But let’s first look at enrichments and their influence on the objects in Europeana.
A semantic enrichment is additional information that is added to the data about certain resources. Semantic enrichments can be interpreted by the system and should be also understood by users. Different disciplines value semantic enrichments for various reasons. For example, in the Linked Data context, semantic enrichments chiefly refer to the creation of new links between the enriched resources and other reference datasets greatly contributing to the vision of the Semantic Web. For information retrieval or search purposes, an enrichment means adding new terms to a query or document, making it therefore more likely to be found with a given query.
In Europeana, enrichments are visible in the portal display, as shown in the object below, and can be identified as links in certain metadata fields (1) and the foldout field ´Auto-generated tags´ (2).
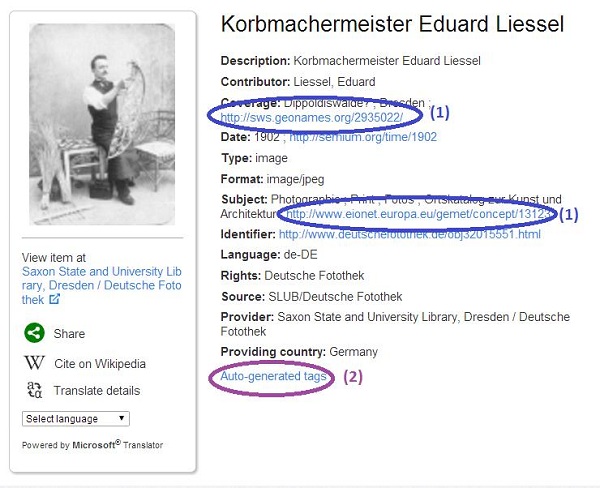
Clicking on “Auto-generated tags” reveals the matched label (3) and its broader label (4).

Currently, the Europeana development team is working on improving both the display of the semantic enrichments and the contextual entities provided by our partners.
The enrichment process can be subsumed under two main steps:
1. Matching the metadata of Europeana objects to external semantic data results in links between these objects and resources from external datasets. The example record shows that the objects was automatically enriched with the concept of 'photography' (3) in the GEMET thesaurus:.
2. The exploitation of these links by adding translated labels and broader labels. In the example given above, this means that the record is supplemented with all the translated labels of the GEMET concept (e.g., 'fotografi' in Swedish), as well as with a link to the broader concept in GEMET and all its translated labels (e.g., 'industrial product')(4).
During a one-day workshop in Berlin, the task force analysed six very different datasets in Europeana and found that enrichment flaws can be caused during one of the five stages that the metadata undergoes before it is displayed in Europeana:
1. Creation of the metadata by the provider
2. Mapping to EDM
3. Ingestion into Europeana
4. Choice of vocabulary used for enrichment
5. Enrichment process
The report gives a detailed account of the influence of these processes on the enrichment quality and gives recommendations on how to prevent some of the issues discovered.
You can download the document here and we welcome any feedback or suggestions on the report and the recommendations.
We would like to thank all participants of the task force for the enthusiasm in analysing collections, their feedback on this report and their contributions during the course of this task force: Agnès Simon, Daniel Vila Suero, Eero Hyvönen, Esther Guggenheim, Lars Svensson, Nuno Freire, Rainer Simon, Rodolphe Bailly, Roxanne Wyns, Seth van Hooland, Shenghui Wang and Vladimir Alexiev.
We would also like to thank Valentine Charles, David Haskiya, Maarten Brinkerink and Kate Fernie for providing valuable feedback.